Object Detection#
从对于整张图片的分类,到对于每个像素的分类,我们始终缺少个体的概念
Object Detection的目标是把图片中感兴趣的物体用最紧的box框出来,然后再判断这个box里面的物体属于哪个类别
Single Object Detection#
假设图片中只有一个物体,我们要输出一个bounding box,这个box是axis-aligned的,即与坐标轴平行的矩形框。我们可以用4个自由度来表示这个box,比如,其中表示box的中心坐标,和分别表示box的宽和高
定位和分类可以一起做:
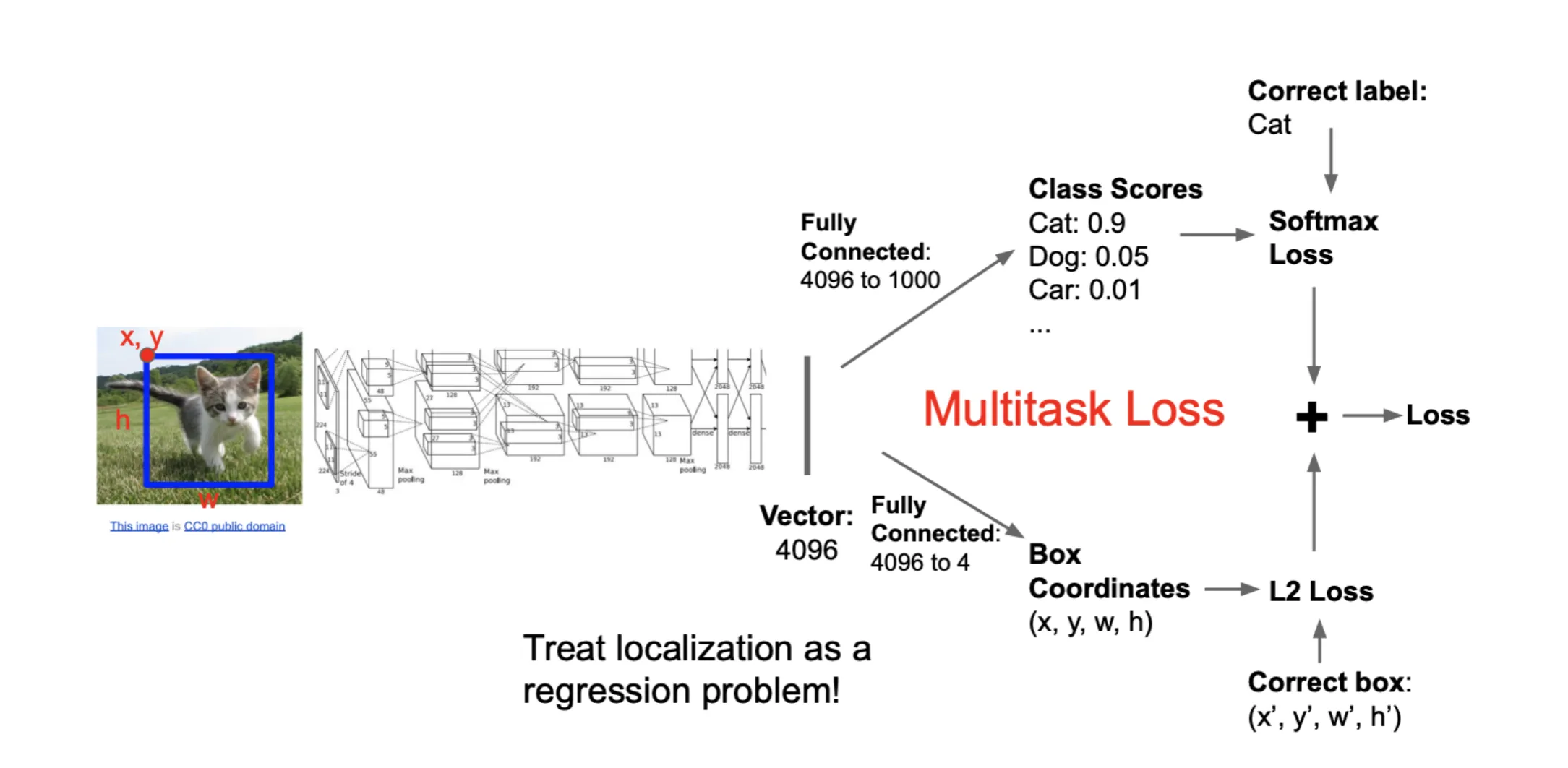
对于卷积层的输出,可以连一个全连接层来进行分类,输出概率;也可以连另一个全连接层来进行定位,输出box的参数
Loss的计算:
- 分类的Loss可以用交叉熵损失函数
- 定位的Loss可以用L1损失函数或者L2损失函数
- 如果像上图一样一起计算,那么总的Loss可以是两者的加权和
下面我们重点看一下定位的Loss,设
- L1 Loss:,robust,但是不好优化(梯度大小始终为1)
- L2 Loss:,不够robust(对于大的梯度会非常大),但容易优化
人们结合了两者的优点,提出了Smooth L1 Loss:
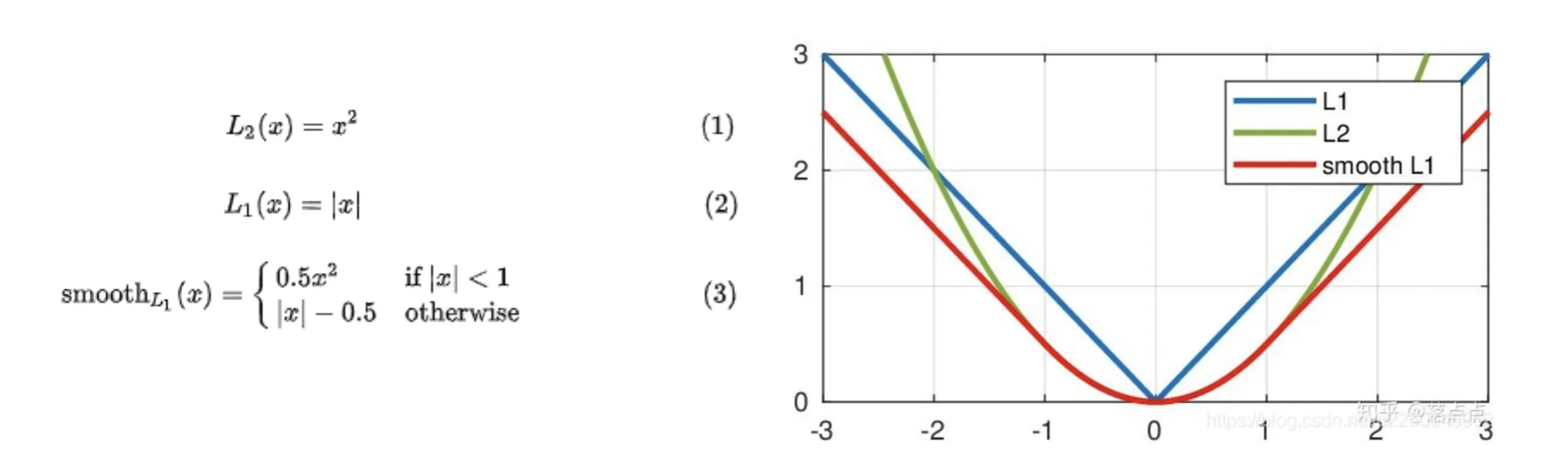
在时,Smooth L1 Loss和L2 Loss一样;在时,Smooth L1 Loss和L1 Loss一样
加上那些奇怪的系数是为了保证在处函数值和梯度都连续
Multi Object Detection#
每个图像中的物体数量是未知的,这就导致输出的维度可能会变化,这是全连接层无法处理的
最开始人们会用slide window的方法来一个个寻找可能的物体,但这种方法效率非常低下,且窗口的大小和步长难以选择
后面人们用一些启发式算法来估计物体可能在哪里
R-CNN#
R-CNN采用启发性的方法来生成一些候选框(Region Proposal);然后对于每个候选框,使用一个卷积神经网络来提取特征,再进行分类和定位
生成的候选框大小不一,又因为卷积神经网络的输入需要固定大小,所以需要对候选框进行裁剪和缩放
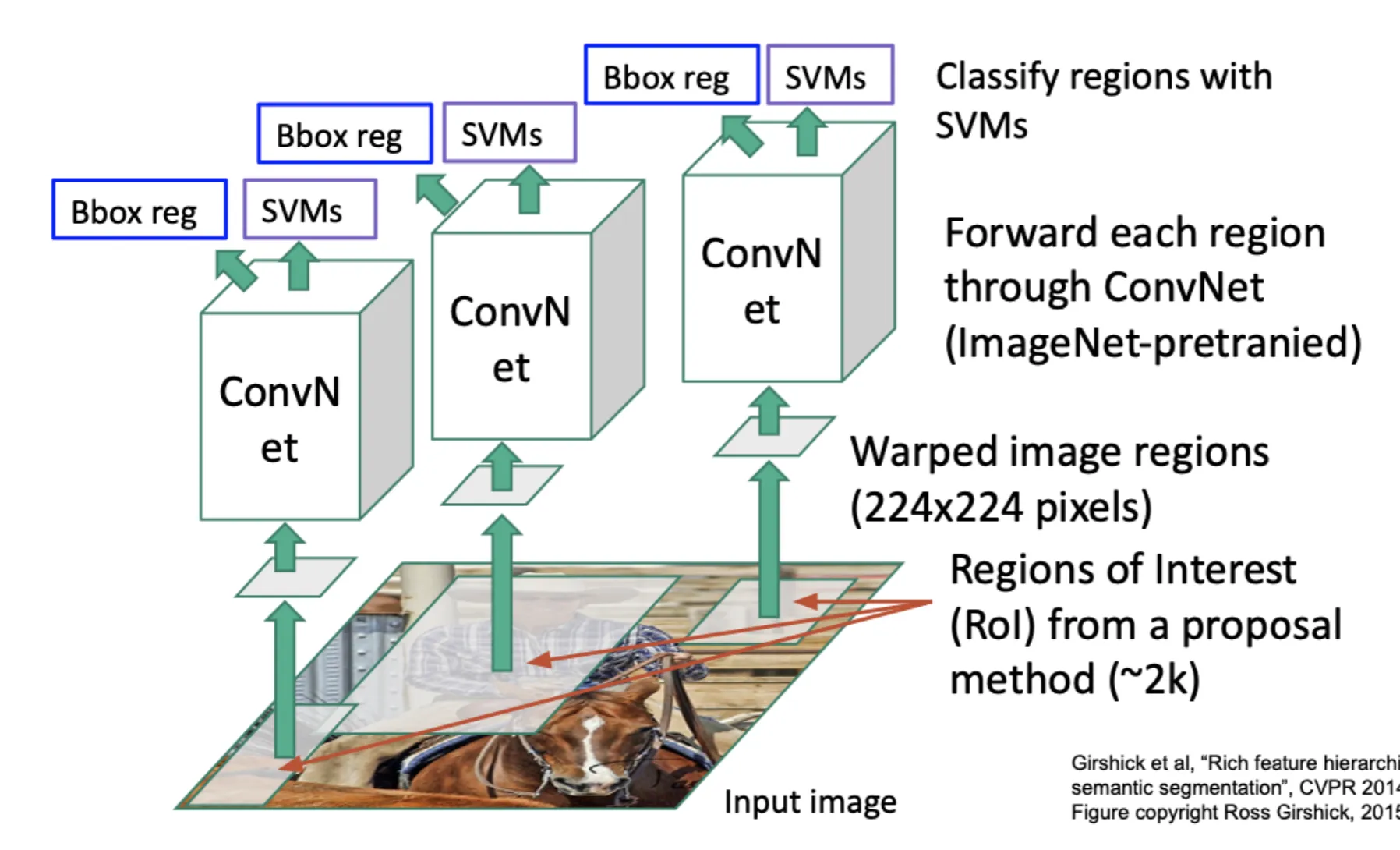
R-CNN需要对所有候选框进行卷积特征提取,非常慢;而且在候选框不准确时,只能进行缩小的微调(因为CNN只看到了候选框里面的内容),性能也不好
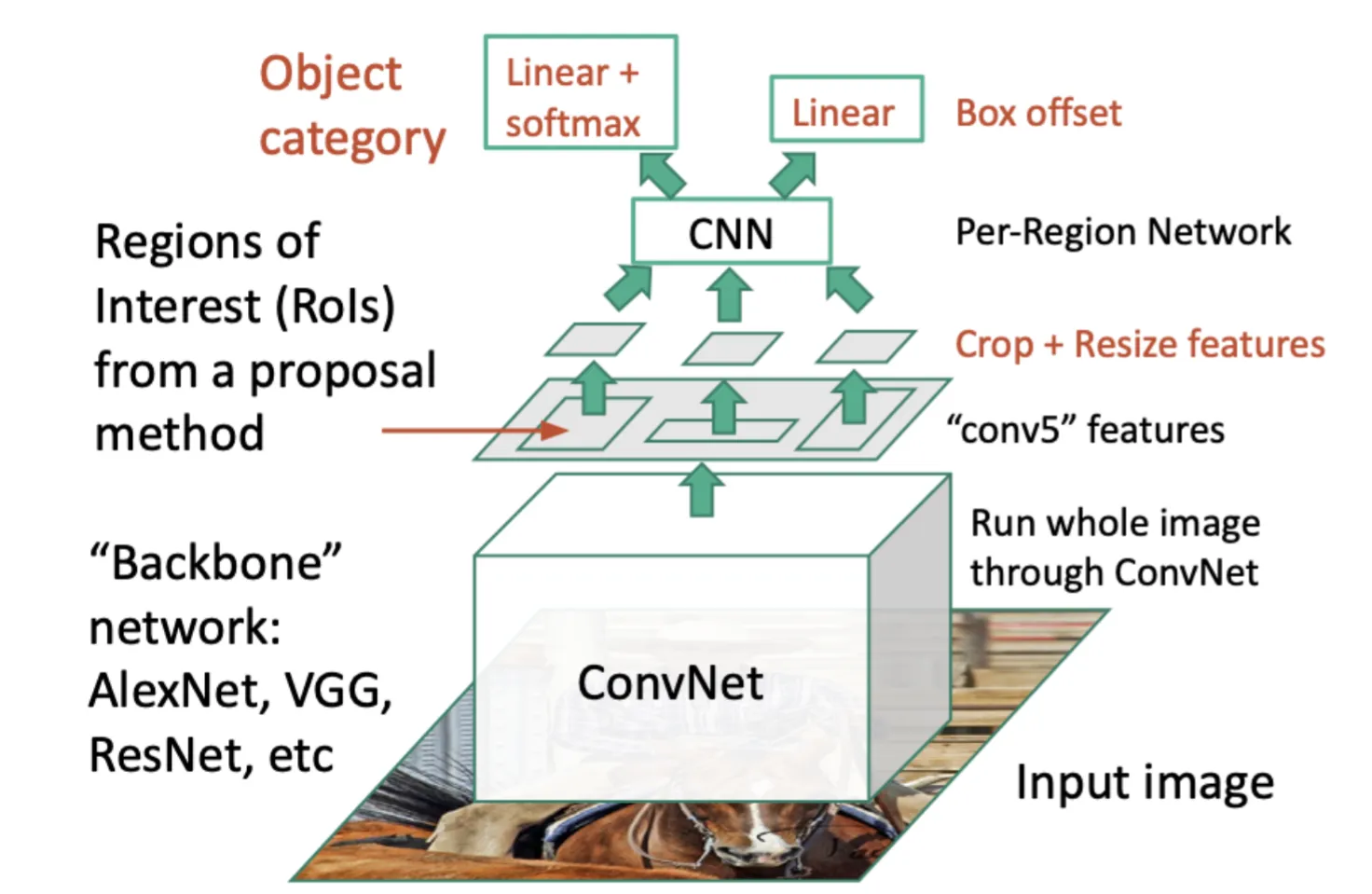
Fast R-CNN#
Fast R-CNN在R-CNN的基础上进行了改进,
- 首先对整张图像进行卷积,得到一个特征图;
- 然后将候选框映射到特征图上,再将这些框内的特征进行RoI Pooling,得到固定大小的特征图;
- 最后进行分类和定位
因为已经对整张图进行卷积,所以候选框内已经有了更大的上下文信息,可以用于微调位置
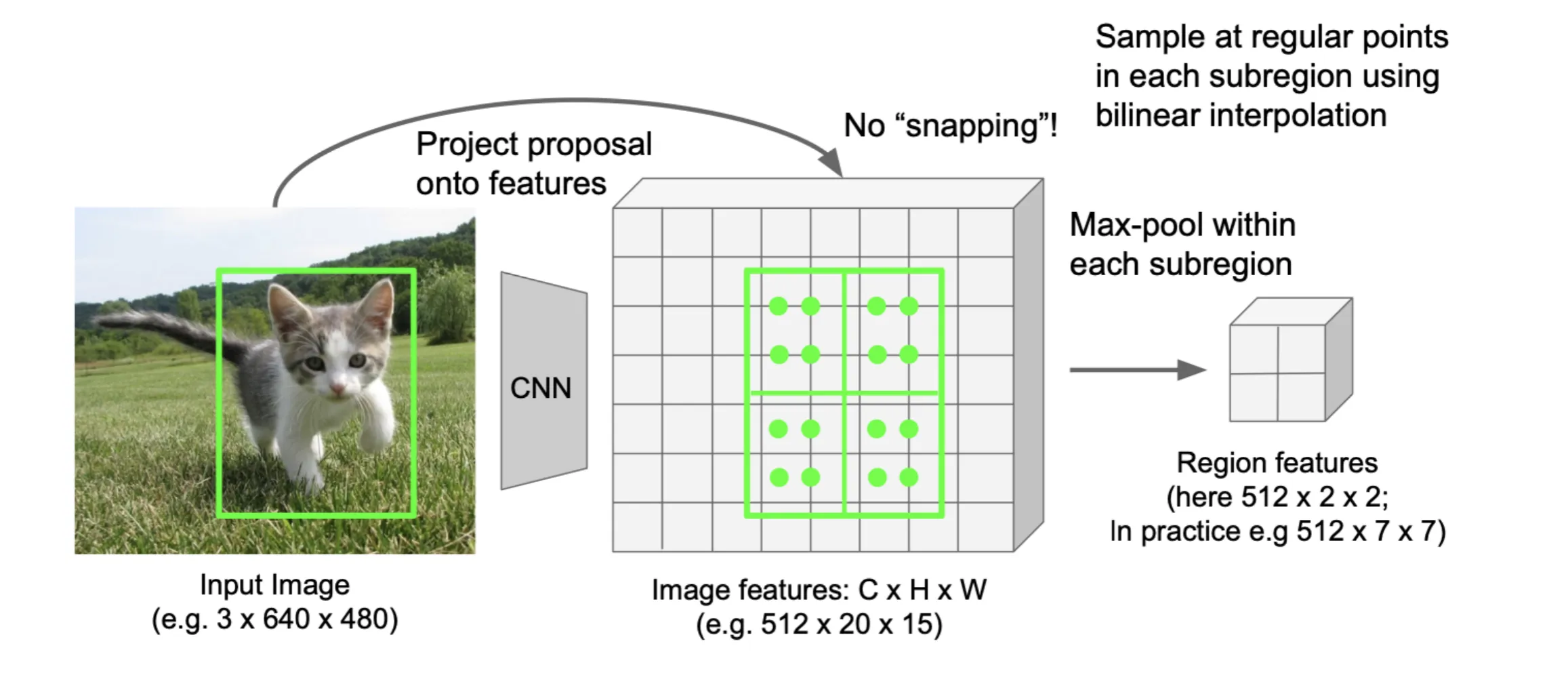
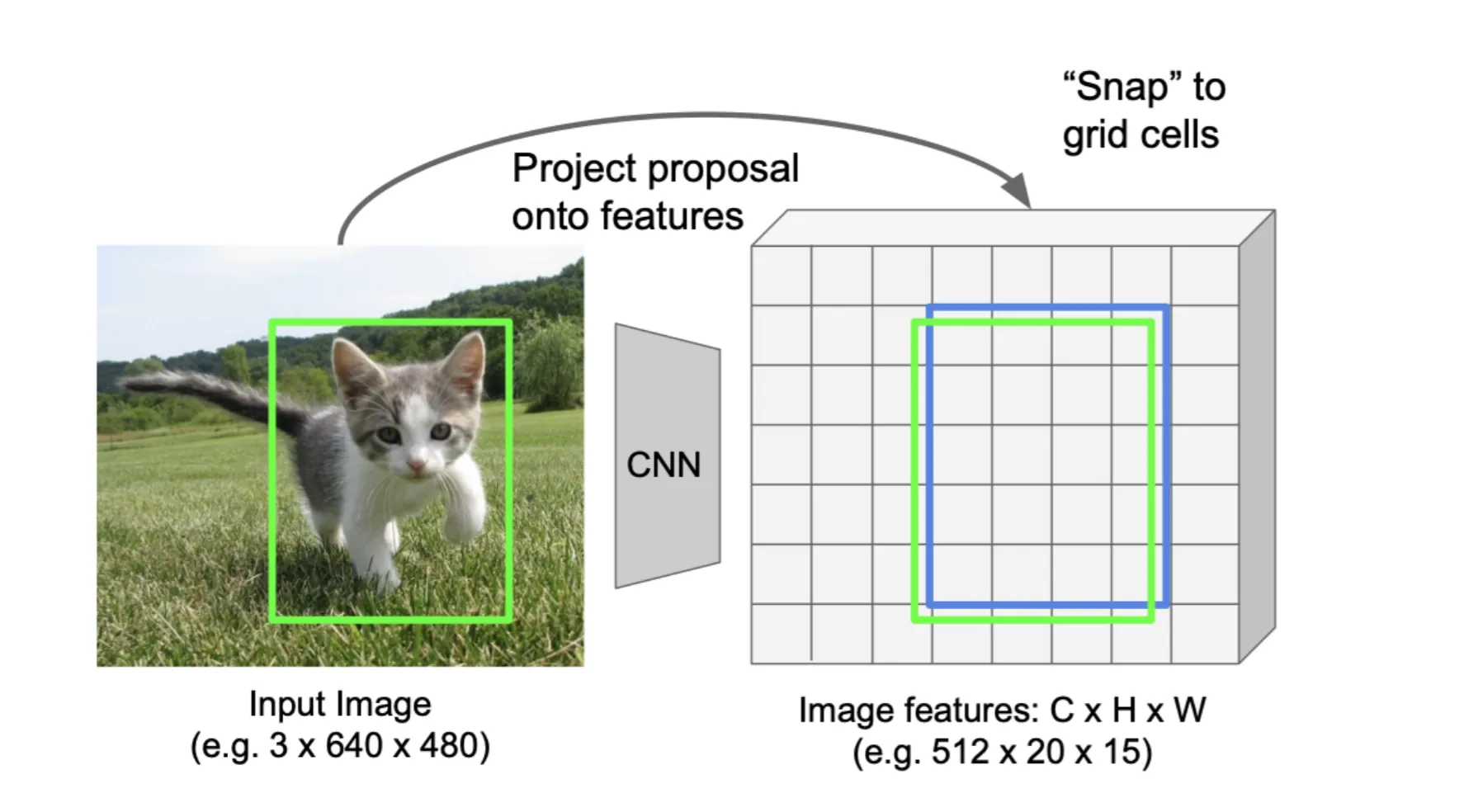
从原图到特征图的映射:
- 最简单的就是按比例缩放,比如输入图像是,卷积层的输出是,那么就把候选框的坐标除以32
但是这种方法得到的位置可能不是格点,内部的像素值不能确定。我们可以直接把候选框贴到最近的格点位置上
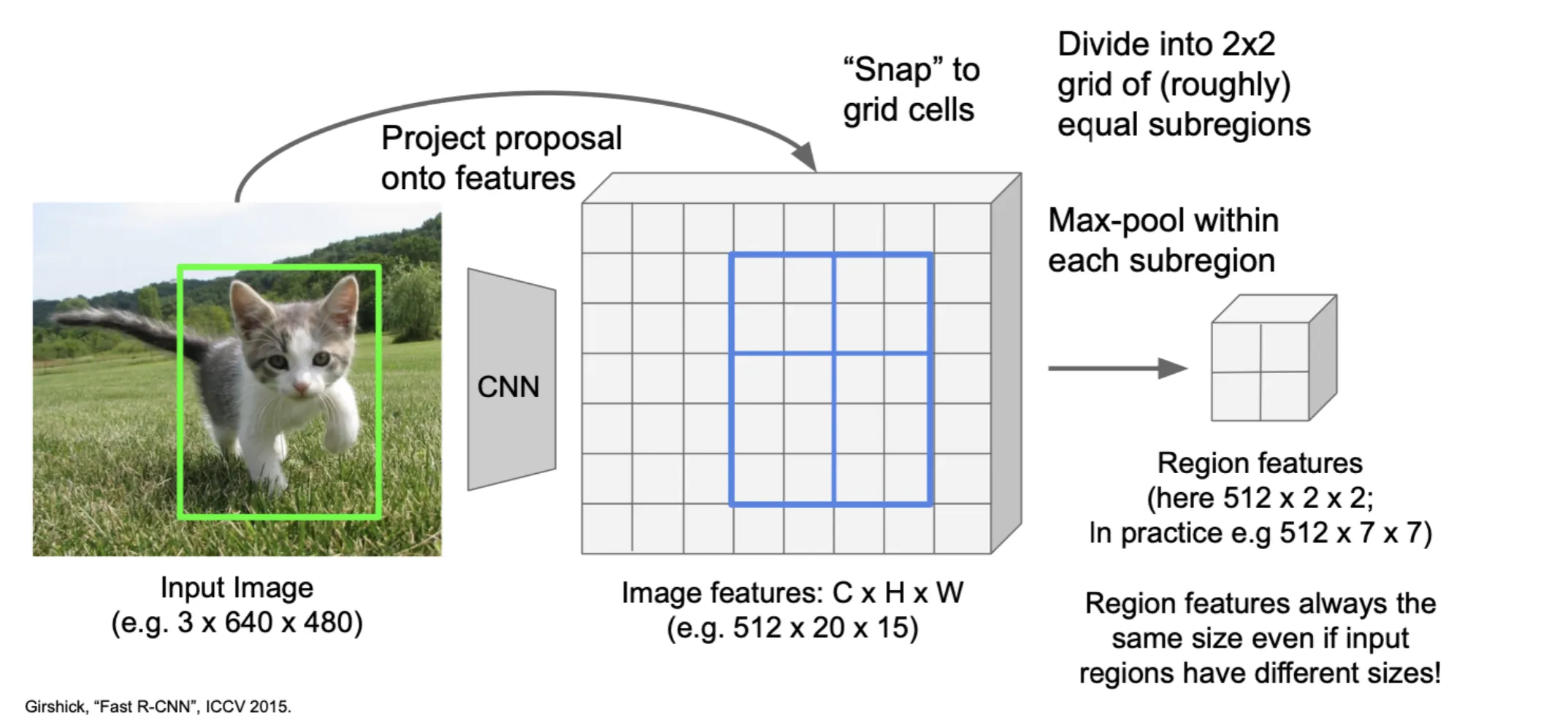
候选框大小不定,我们需要把它们都变成固定大小的特征,做法也很直接,就是把候选框划分成固定数量的子区域,然后在每个子区域内进行池化,得到一个固定大小的特征图
这两种方法都没有解决物体数量不定的问题,都是传统方法给出多少个就处理多少个
Faster R-CNN#
Fast R-CNN的瓶颈在于使用传统方法生成候选框,这个时间占了很大部分;Faster R-CNN提出了Region Proposal Network(RPN),使用神经网络来生成候选框
RPN使用一个在共享特征图上滑动的窗口,为每个位置生成k种预先设置好长宽比与大小的框(anchor)
对于每一个anchor,RPN会输出一个二分类的概率(这个anchor是否包含物体)和一个回归的坐标(这个anchor与真实框之间的偏移)
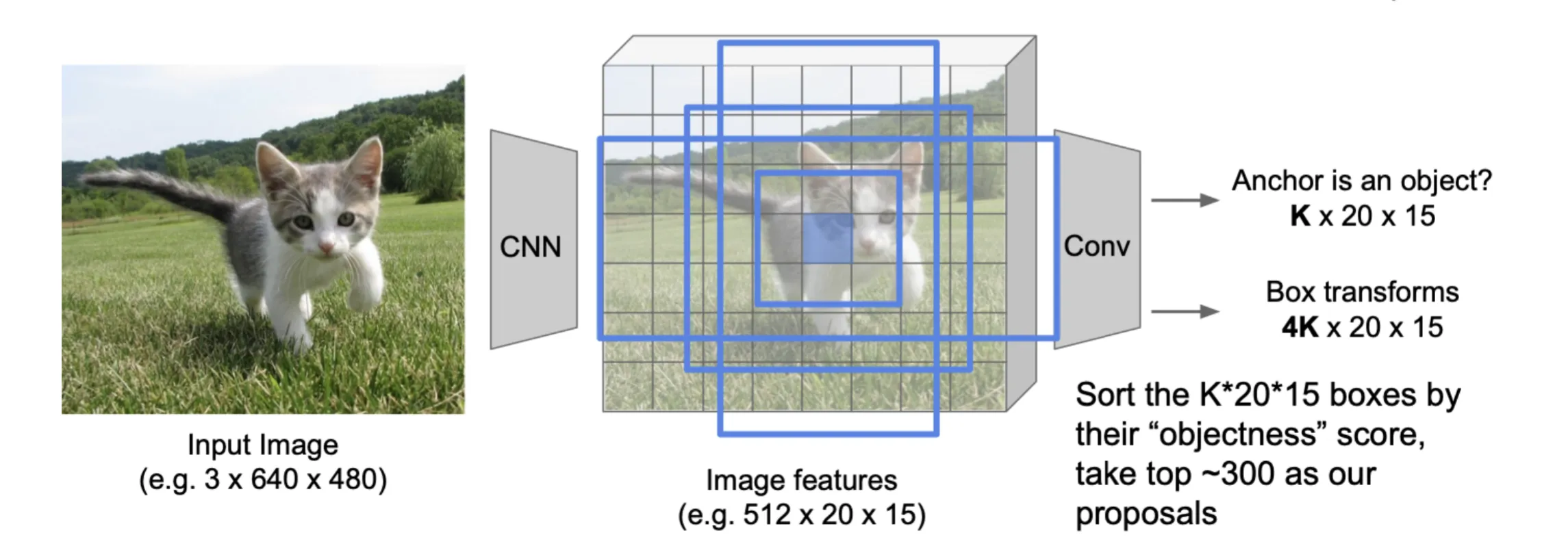
然后根据RPN的输出,选择一些候选框进行RoI Pooling,再进行分类和定位
最后得到的box可能有多个指向同一个物体的候选框,我们可以用非极大值抑制(Non-Maximum Suppression)来去重。具体如下:
- 选择候选框中概率最高的box
- 抑制掉与它类别相同且IoU大于某个阈值的候选框
- 再看剩下的候选框,选择概率最高的box,重复上述步骤,直到没有候选框了
损失函数由四部分组成:
- RPN的分类损失:是不是物体
- RPN的回归损失:anchor与真实框之间的偏移
- 最终的分类损失:候选框里面的物体属于哪个类别
- 最终box的偏移
由于选择候选框的过程是不可微的,所以RPN和最终的分类定位网络是分开训练的
- 先训练RPN
- 用得到的RPN生成的候选框来训练最终的分类定位网络
- 冻结共享层,微调RPN
- 冻结共享层,微调最终的分类定位网络
Evaluate#
对于每个类别,我们计算Precision-Recall曲线,得到Average Precision(AP)
- Recall:正确检测的正样本占所有真实正样本的比例
- Precision:正确检测的正样本占所有检测为正样本的比例,通常认为IoU大于某个阈值的候选框是正确检测的正样本
每次选择top-n的输出,计算Precision和Recall,得到一个点;改变n的值,得到一条曲线
计算曲线下面积,得到AP。完美的模型的AP为1
Instance Segmentation#
有了Object Detection,接下来再做Instance Segmentation,就很简单了,就是在每个候选框内进行像素级的分类,得到一个分割图像。但有时候效果并不好
在Faster R-CNN中,我们直接把候选框贴到最近的格点上,这样就丢失了很多位置信息
Mask R-CNN直接使用线性插值来得到RoI Pooling的结果