Classification Backbones#
下面看一下一些经典的分类网络结构及其特点
Receptive Field in VGG#
在VGG网络中,卷积核的大小为。我们考虑三层卷积层,那么输出图像中一个像素对应于输入图像中的区域,这个区域被称为感受野(Receptive Field)
感受野的大小决定了模型能够捕捉到的上下文信息的范围,较大的感受野可以帮助模型更好地理解图像中的全局信息
三层卷积层的Receptive Field和一层卷积层的Receptive Field是一样的,但前者所需参数为,后者所需参数为,前者的参数更少,更容易训练
BottleNeck in ResNet#
ResNet中网络很深,直接使用普通的卷积层会导致参数过多,因此引入了BottleNeck结构
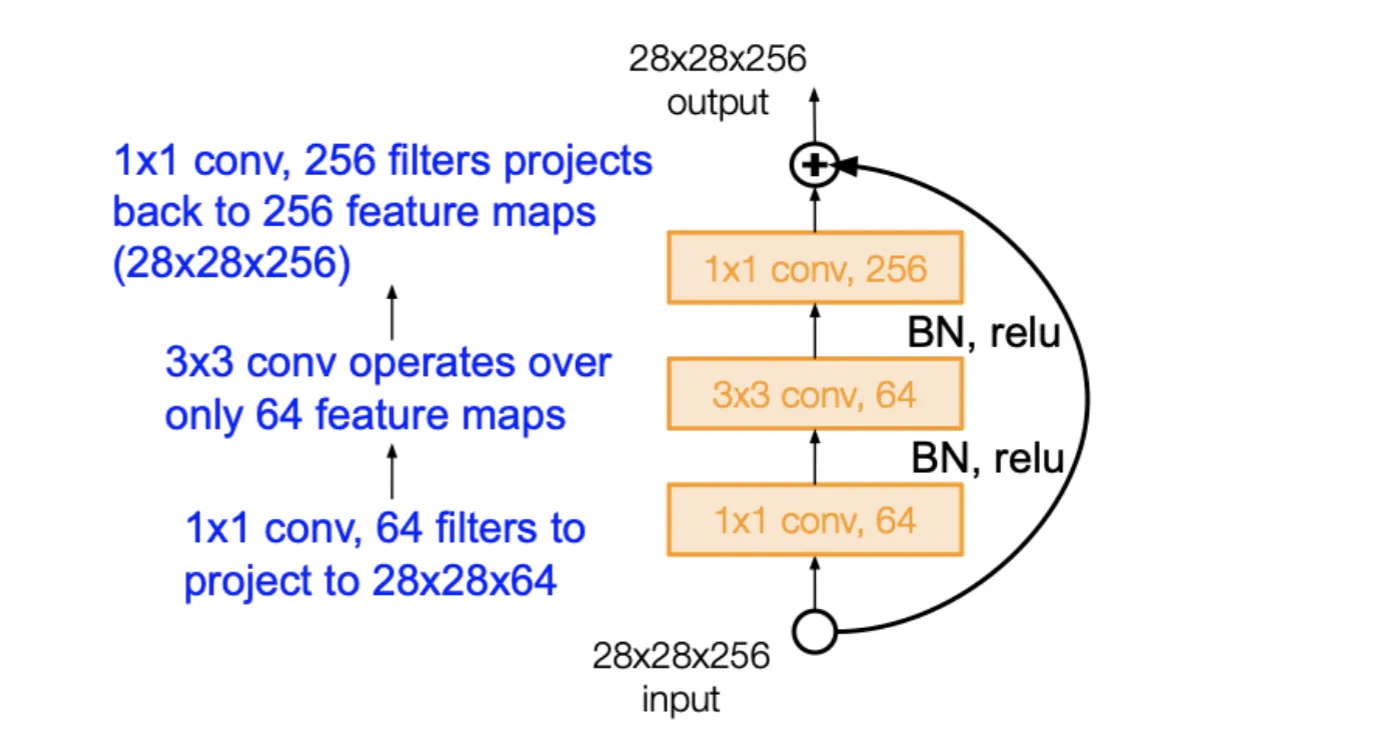
对于256Channel的输入,先通过卷积层将通道数降到64,再通过卷积层进行特征提取,最后再通过卷积层将通道数升回256,大大减少了参数量
Segmentation#
分类问题中,图片里面一般只有一个物体,我们只需要判断图片属于哪个类别;但在分割问题中,图片里面可能有多个物体,我们需要判断每个像素属于哪个类别
分割问题需要确定每个像素所属的类别,因此需要输出一个与输入图像大小相同的特征图,每个channel表示一个类别,每个像素的值表示该像素属于该类别的概率
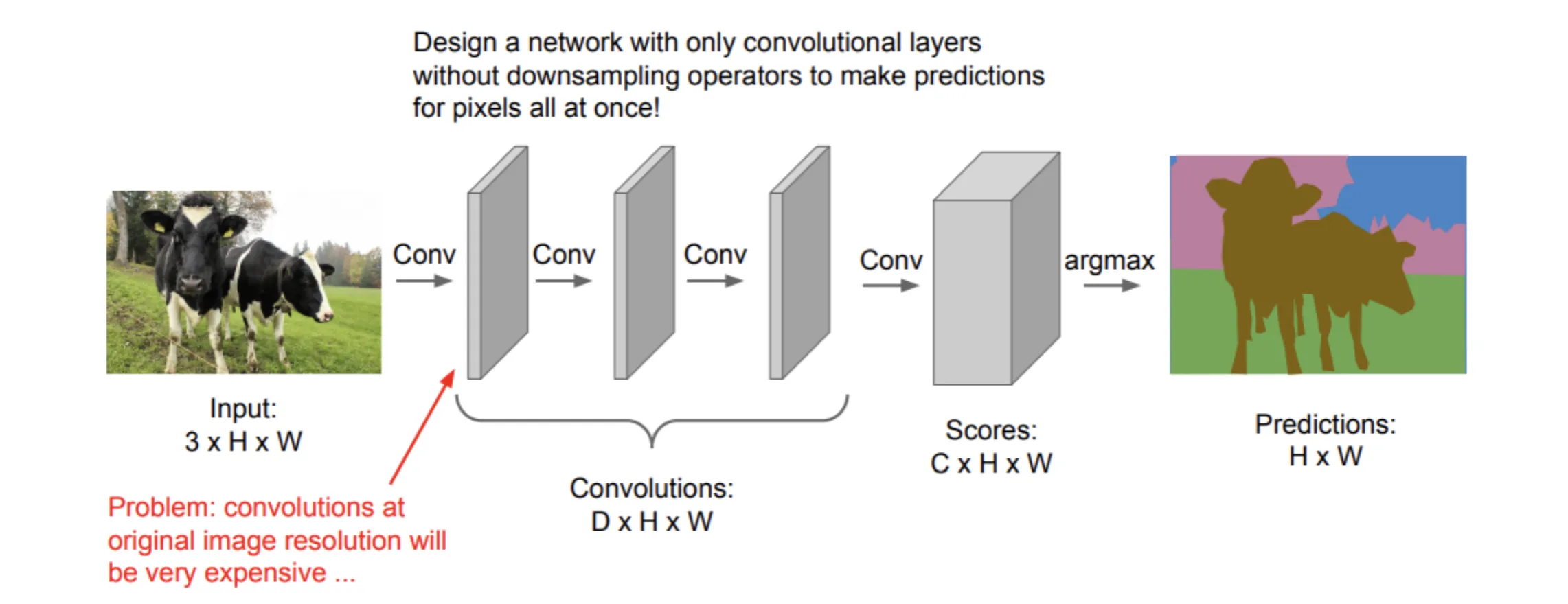
现在考虑网络内部结构的设计:
如果内部每层的输出都保持和输入图像大小相同,那么对存储非常不友好,因此需要对图像的信息进行压缩
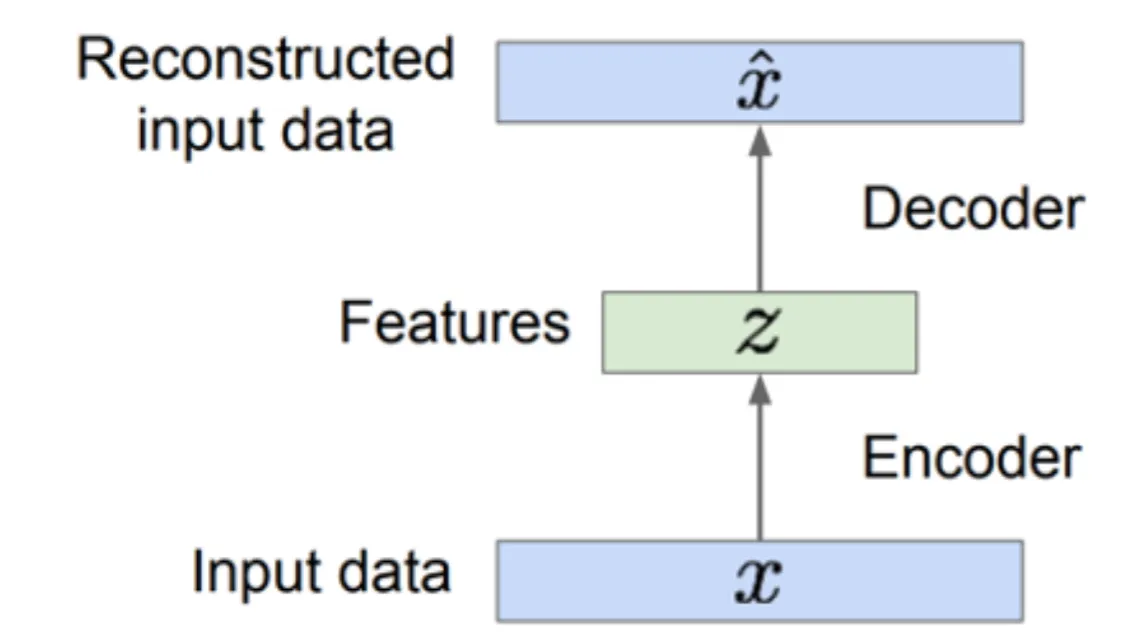
Auto-Encoder#
图片传递的信息其实是很少的,看似有着很高维的输入,其实内部有很多噪音。我们可以学习一个编码器,将输入图像压缩成一个低维的潜在空间表示,再通过一个解码器将其还原成与输入图像大小相当的特征图
将图像降维的方法我们已经知道很多了,比如卷积(stride)、池化;那么怎么将图像升维呢
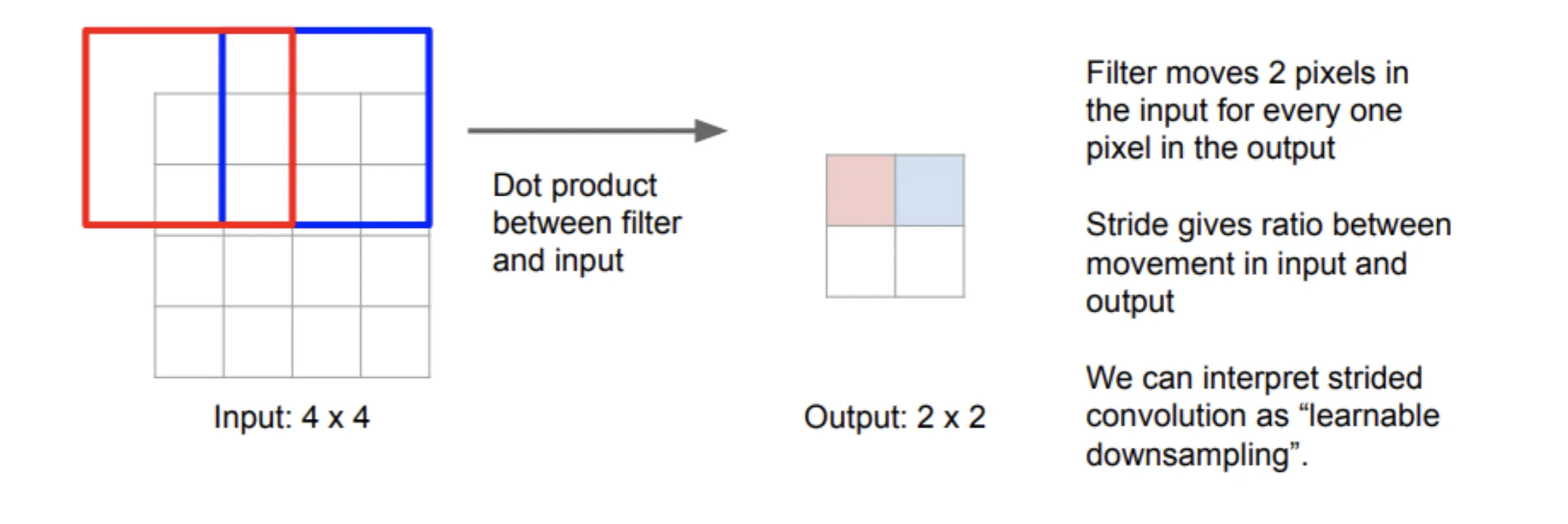
Transposed Convolution#
回顾一下卷积,我们考虑一个卷积核,步长为2,那么下采样的步骤如下图:(Input应该为的,图里面画错了)
我们可以用类似的方法,反过来进行上采样:(Output同上)
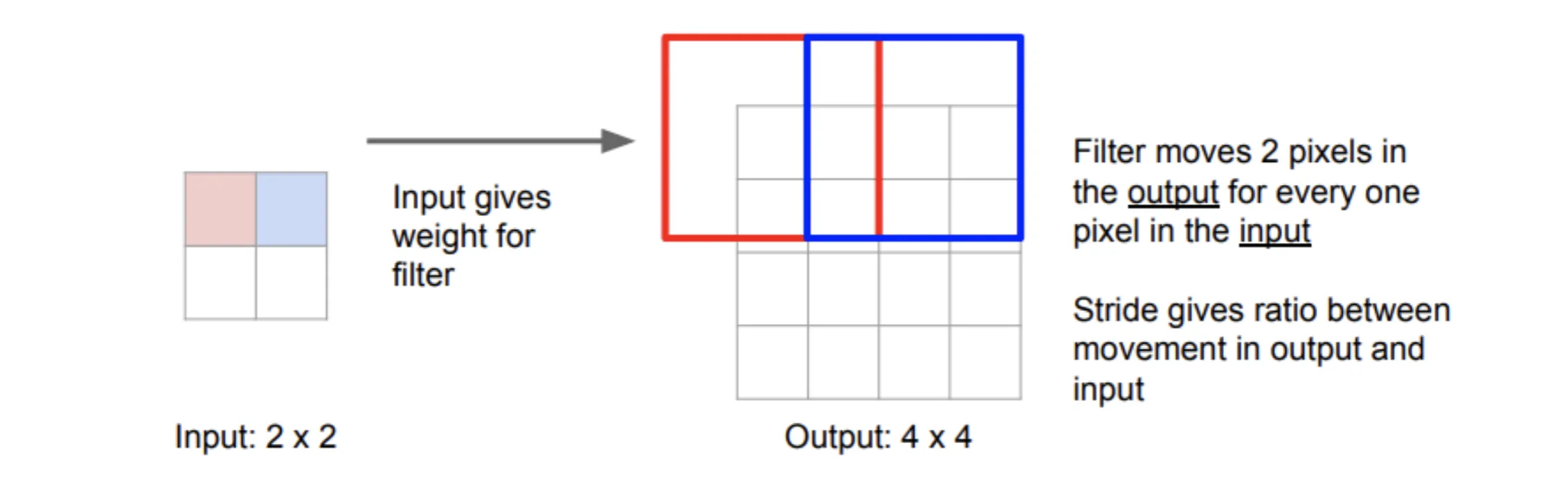
红色像素的值与卷积核相乘后,得到了输出图像红色部分的值;蓝色同理
要注意的是相乘后移动的步长也是2
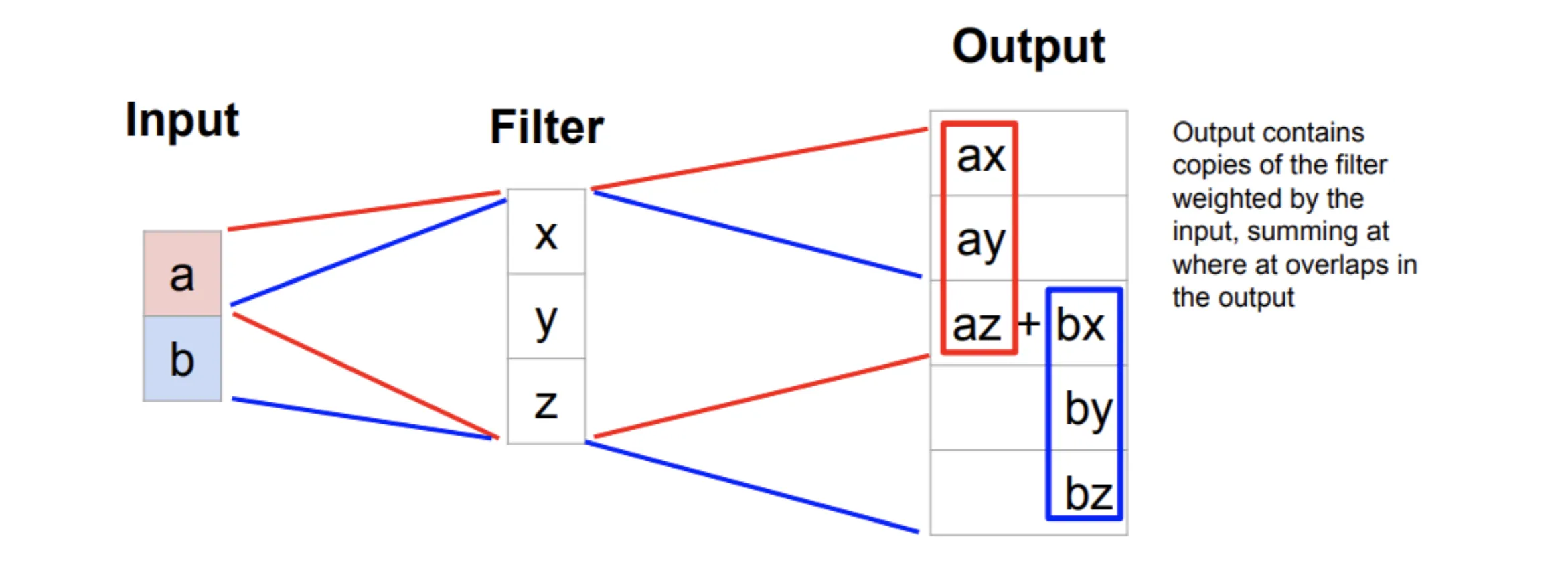
我们发现图中红框和蓝框部分相交,这部分输出图像的值应相加
一维看的更清晰:
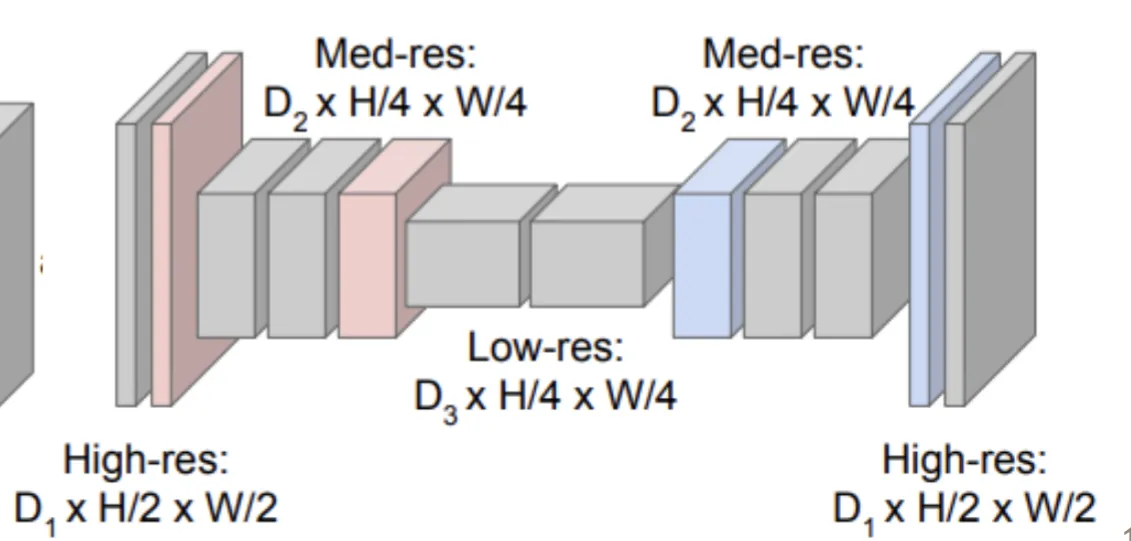
最后,我们通过引入encoder结构,得到了一种进行分割的网络结构
UNet#
在上面的分割网络中,由于BottleNeck的引入,Encoder部分的输出被压缩到很小
而为了还原到输入图像大小,BottelNeck需要记住输入图像的全局上下文信息,还需要记住分割后的边界信息,这会比较难
Unet引入了skip connection结构,在decoder部分将encoder部分的输出直接连接到decoder部分,这样decoder部分就可以直接获取encoder部分的特征图,帮助其更好地还原输入图像的细节信息(也就是不需要让bottelneck记住原图的精细信息,记住global context就行了)
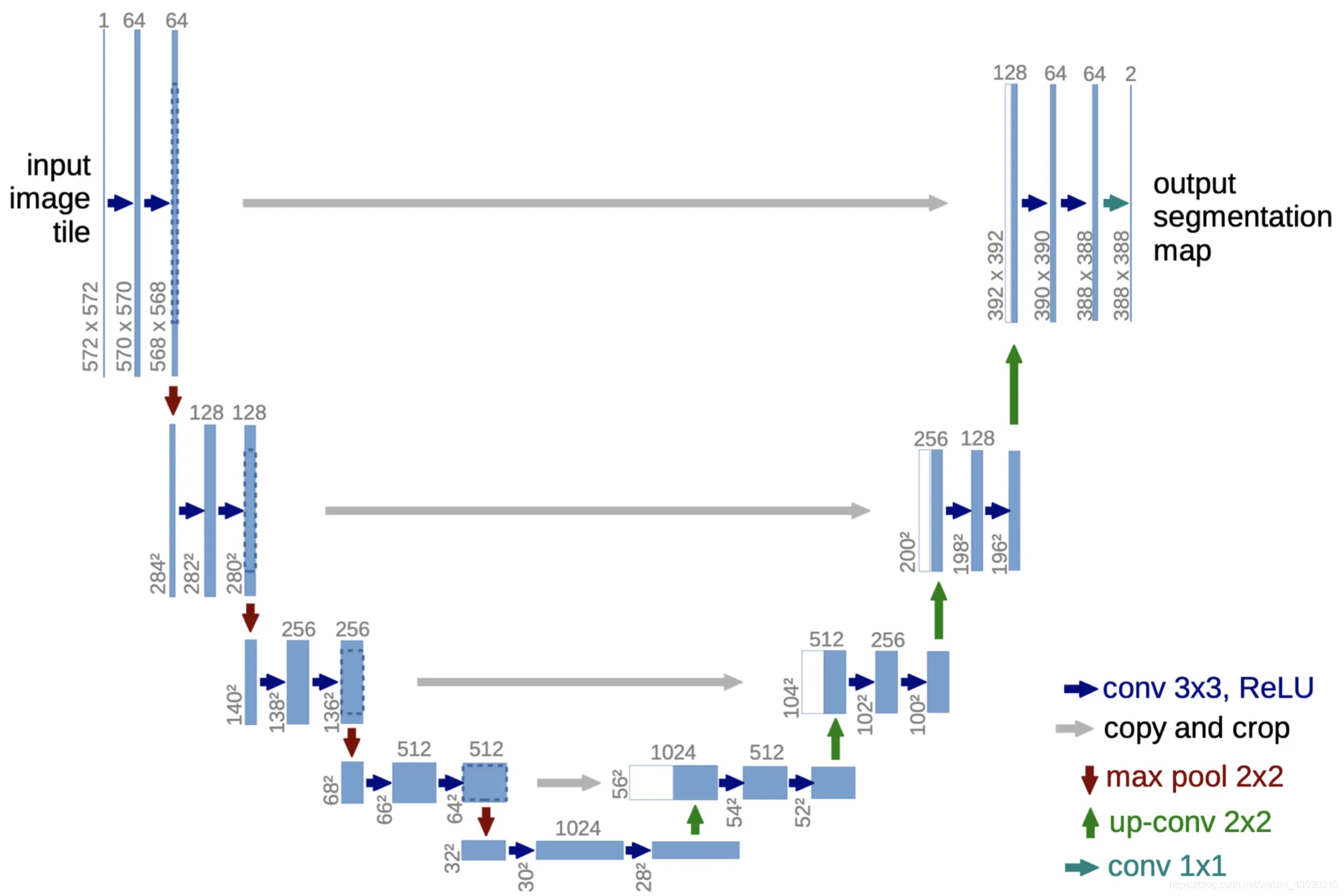
我们看最下面两层来理解一下Unet的结构:
- 对于大小为的输入,经过两次卷积后得到的输出图像
- 这个图像传到下一层,经过类似的操作后得到的输出图像
- 这个图像传到decoder部分,进行upper convolution后得到的输出图像
- 这个图像与encoder部分的输出图像进行concat操作,得到的输出图像,这个图像作为decoder的输入,进行后续的操作
- 注意到倒数第二层,encoder的输出大小为,而decoder需要的是,因此需要进行中心裁剪操作(即图中虚线)
Evaluation Metrics#
下面我们说一下如何去评测分割模型的好坏
Pixel Accuracy:对于每个类别,计算模型正确分类的像素占总像素的比例
这是最简单的指标,但会存在类别不平衡的问题,比如背景像素占大多数,那么模型只需要把所有像素都分类为背景就能得到很高的Pixel Accuracy
Intersection over Union (IoU):计算预测的分割区域与真实分割区域的交集与并集的比例
这样就避免了类别不平衡的问题
mIoU:对于多类别分割,计算每个类别的IoU,然后取平均值
由于IoU不可导,不能用于反向传播,因此人们构造出Soft IoU Loss来优化模型,这里就不展开了