Image Classification#
下面我们研究多分类问题,问题描述如下:
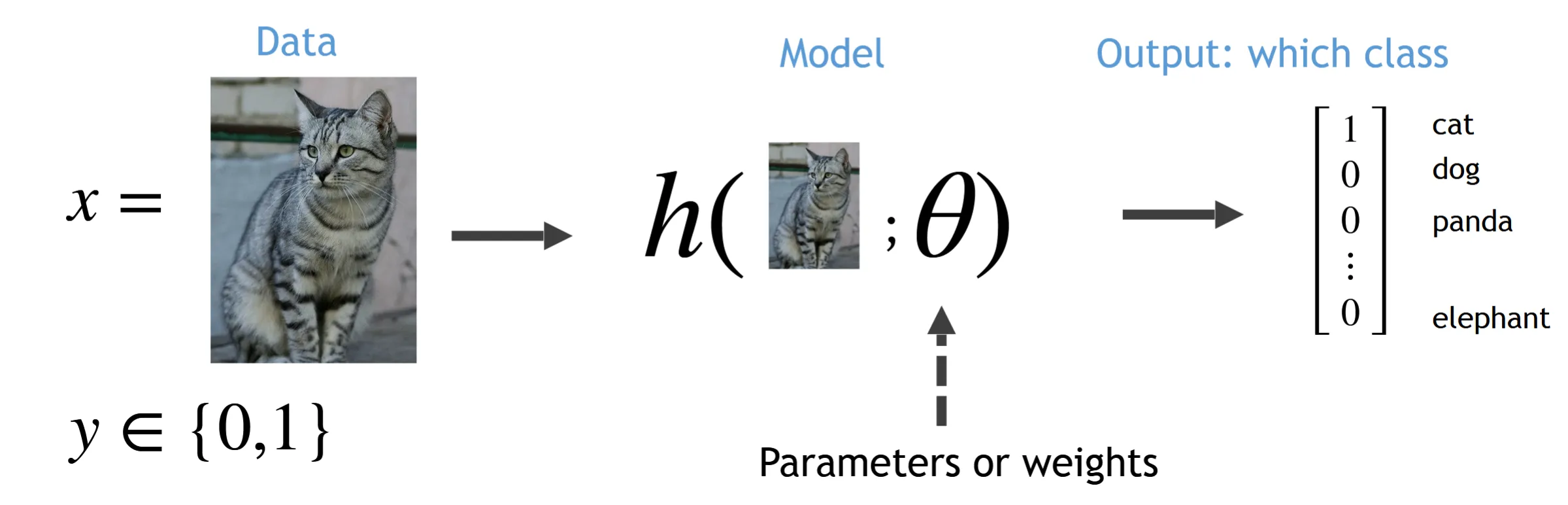
给定一张图片,经过模型后输出一个向量,向量的维度等于类别数,每个元素表示该类别的概率,且所有元素的和为1
其实多分类的具体框架和二分类相似,都是先经过多个卷积层/池化层/激活函数,最后展开成一个向量,再经过MLP。不过最后的输出层不同,二分类输出一个元素,经过sigmoid函数得到概率;多分类输出一个向量,经过softmax函数得到每个分类的概率
Softmax函数#
Softmax函数的定义如下:
通常情况下设置为1,当时,softmax趋近于argmax
Cross-Entropy Loss#
现在已经可以得到每个类别的概率,那我们该怎么计算损失函数呢
如果标签是one-hot编码的,那么仍然可以使用NLL损失函数,只需计算所属的类别的损失即可
其中是标签的one-hot编码,是模型输出的概率(已经经过softmax函数)
但如果标签表示为图片属于某个类别的概率,那么我们需要一种标准来计算模型输出的概率分布和标签的概率分布之间的差异
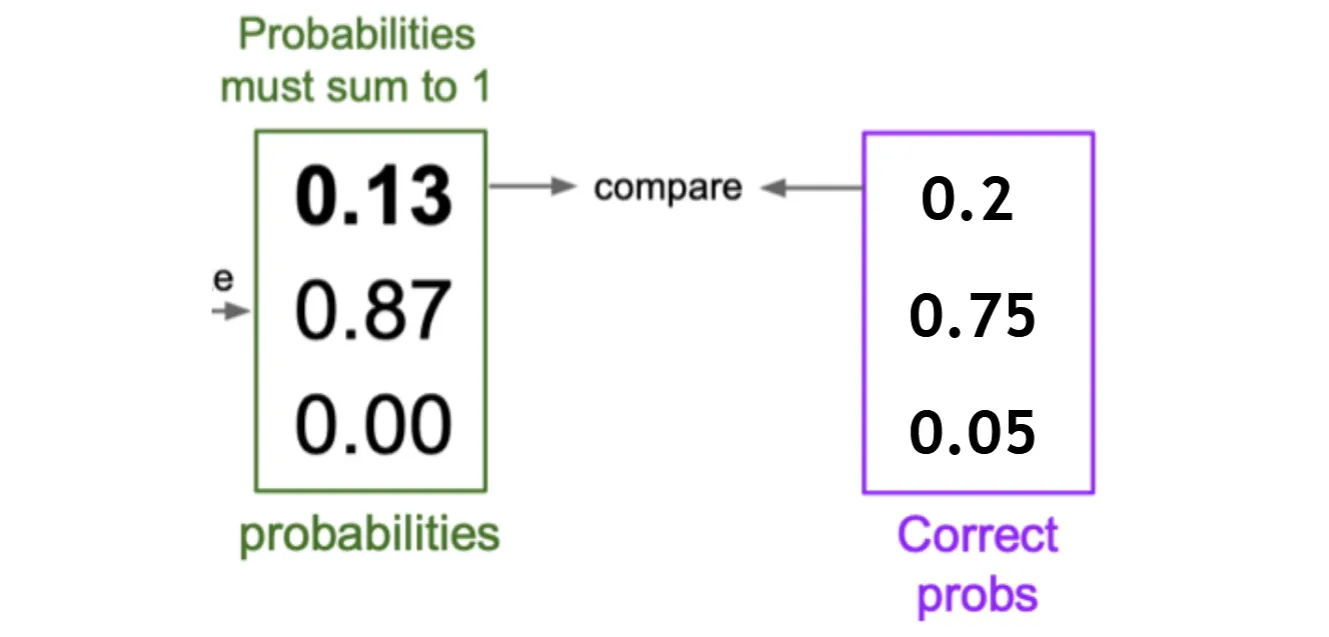
KL散度:
KL散度是一种常用的计算两个概率分布之间差异的指标,定义如下:
其中和分别是两个概率分布,和分别是第个类别的概率
KL散度的几个特点:
- 不对称,即
- ,当且仅当时,
把KL散度展开
其中表示P的熵,即,表示交叉熵,即,因此KL散度可以表示为:
是固定的,是常数,因此最小化KL散度等价于最小化交叉熵
我们得到了交叉熵损失函数的定义:
Underfitting#
Underfitting最简单的解决方法就是增加模型的容量,比如增加模型层数,增加参数数量
但增加模型容量可能会破坏参数的分布,导致模型难以优化(比如同一学习率对于不同层的参数可能不合适),我们需要一些方法来使模型深度增加后仍然能进行可控的优化
Batch Normalization#
为了控制不同层之间参数分布变化,一般会在FC Layer后,激活函数前加入Batch Normalization层
下面我们看一下BatchNorm的实现:
设输入的维度为,其中是batch size,是特征维度
- 计算输入的均值和方差
其中表示第个样本的特征向量,和都是维的向量
- 对输入进行Normalize
是一个小常数,防止除以0
这样得到了一个方差、均值的分布,但我们希望模型能够学习到不同的分布,因此需要进行缩放和平移
- 进行缩放和平移
其中和是可学习的参数,分别控制缩放和平移的程度。在反向传播时像线性层一样更新

经过BatchNorm层之后,输入被转化为一个方差为、均值为的分布
summary:
- 前向传播时要计算和,用moving average来更新和
- 反向传播时要更新和
- 在输出层(Softmax之前)不应再加入batchnorm层,否则会破坏参数分布
- 在Batch较小时,由于和的估计不准确,会导致效果变差
- 测试时使用的和与训练时的来源并不一样,可能导致结果不稳定
ResNet or Skip links#
随着网络深度的增加,模型的训练会变得困难,经常由于underfitting导致训练误差较大,甚至无法收敛。我们想让深层网络至少和浅层网络一样好。
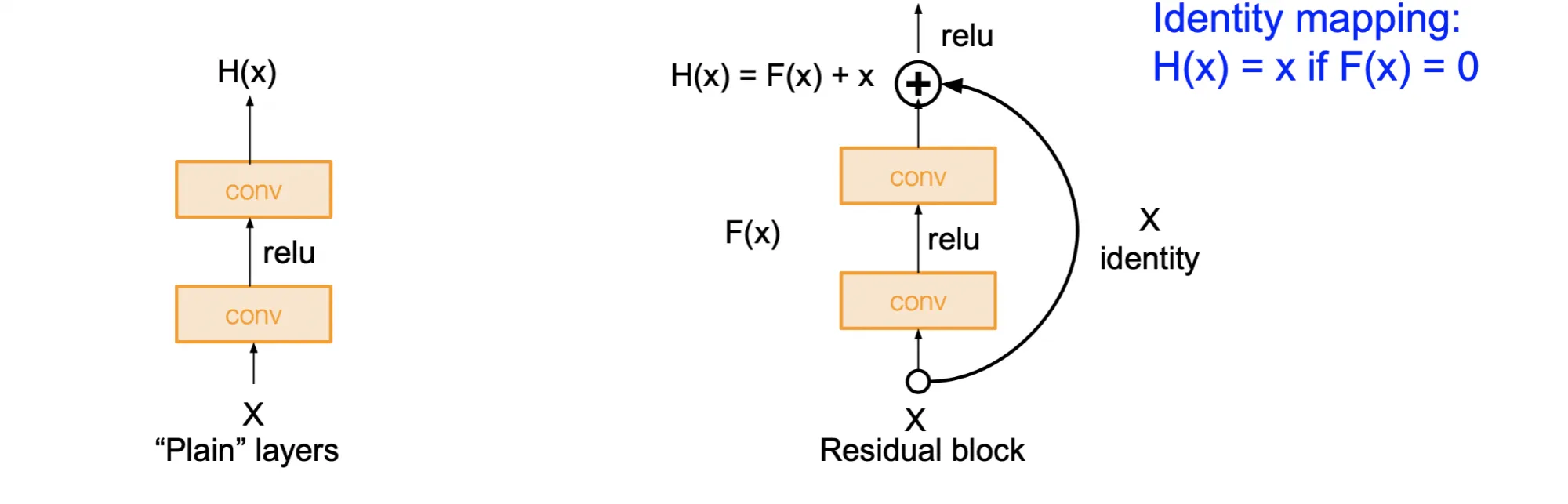
残差连接(Residual Link)或跳跃连接(Skip Link)是一种在深层神经网络中引入直接路径的方法,允许信息绕过一个或多个层直接传递到后续层。这样在面对深层网络时,模型更容易学到恒等映射(Identity Mapping),最少也能保证深层网络的性能不比浅层网络差
在反向传播时,梯度不断相乘,随着深度增加,梯度可能会变得非常小,靠近输入层的部分会难以训练。残差连接提供了一个直接的路径,使得梯度可以直接传递到前面的层,缓解了梯度消失的问题
summary:
- 面对underfitting问题,增加模型容量是最直接的解决方法,但可能会导致优化困难
- 随着参数增多,也要随着提升优化水平,否则多出的参数反而会成为负担
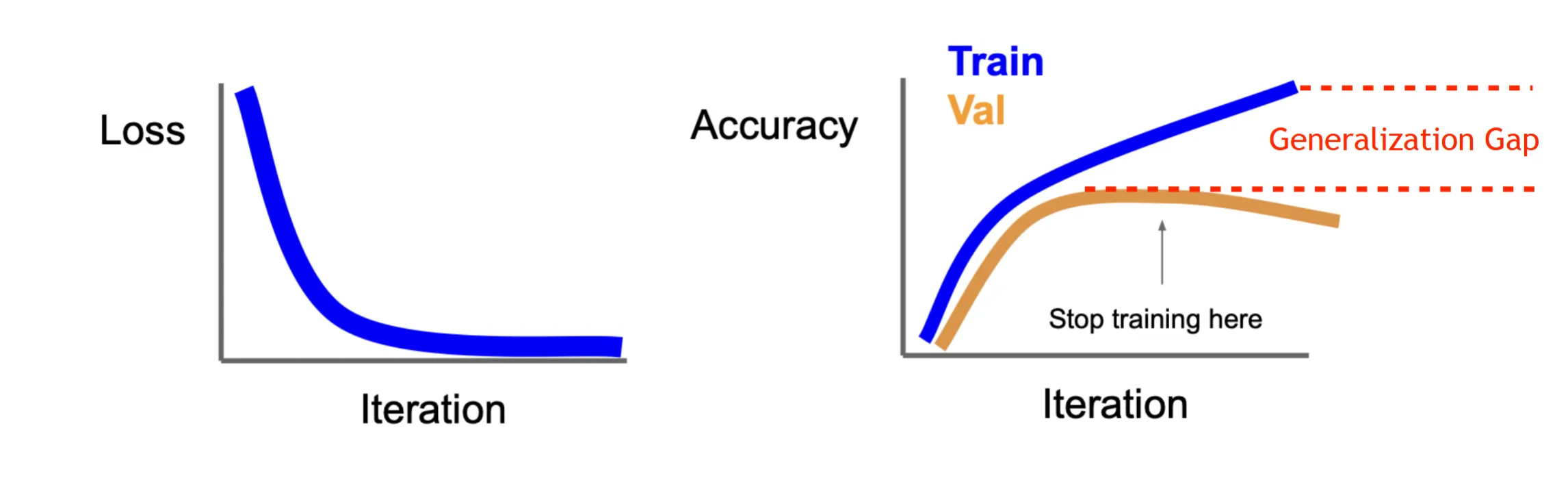
Overfitting#
模型真正有价值的能力是泛化能力,即在未见过的数据上表现良好。当模型在训练数据上表现很好,但在测试数据上表现很差时,我们称模型发生了过拟合(Overfitting)
过拟合可能是由于模型把训练集中不可泛化的特征也学了进去
Data augmentation#
模型的能力要与数据相匹配,如果模型的能力过强,数据量又不足,那么模型就会过拟合
解决这个问题最本质的方法就是获取更多的数据,但是可能会很贵;另一种简单的方法就是对现有的数据进行增强(Data Augmentation),在保持标签不变的情况下,通过一些变换来增加数据的多样性
常见的一些数据增强方法包括:
- Position augmentation:对图像进行平移、旋转、缩放等变换
- Color augmentation:对图像的颜色进行调整,如亮度、对比度、饱和度等
- 用一些生成模型生成新的数据
数据增强要适度,如果丢失了图像的核心信息,那么就没有意义了;也不能导致数据发生歧义
Regularization#
对模型参数加一定的惩罚项,防止模型过于复杂,导致过拟合
加入正则化项后,损失函数变为:
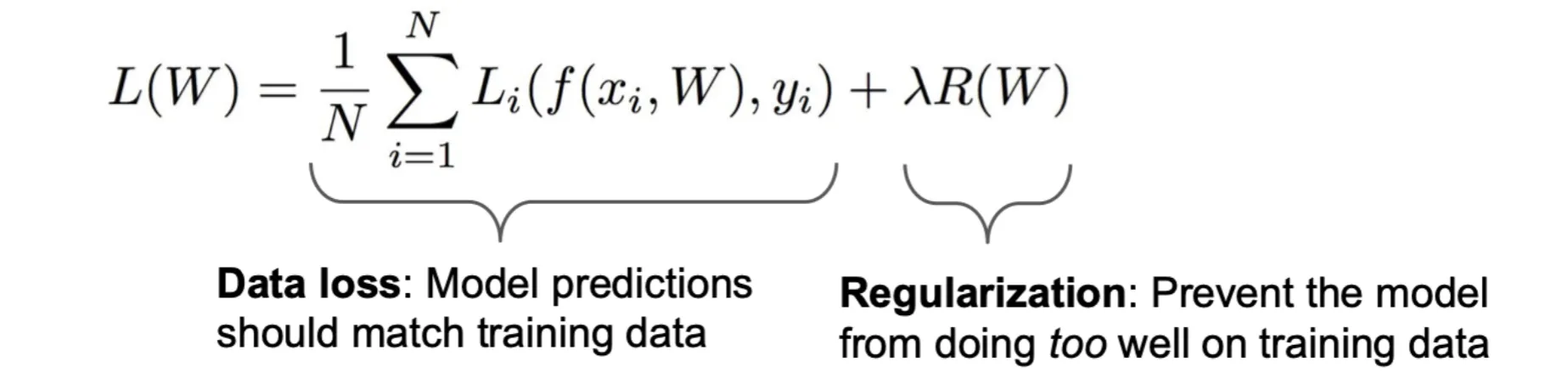
其中Data Loss部分是原始的损失函数,是正则化强度的超参数,是惩罚项,是模型参数的函数,随采用的正则化方法不同而不同
常见的正则化方法包括:
- L1正则化:,会使得一些参数变为0,具有特征选择的作用
- L2正则化:,会使得参数变小,但不会变为0
Dropout#
在训练过程中,有的概率随机丢弃一些神经元,从而提高模型的泛化能力
比如,对于一张鱼的图片,即使遮掉一部分,模型也应该能够正确地识别出这是一条鱼
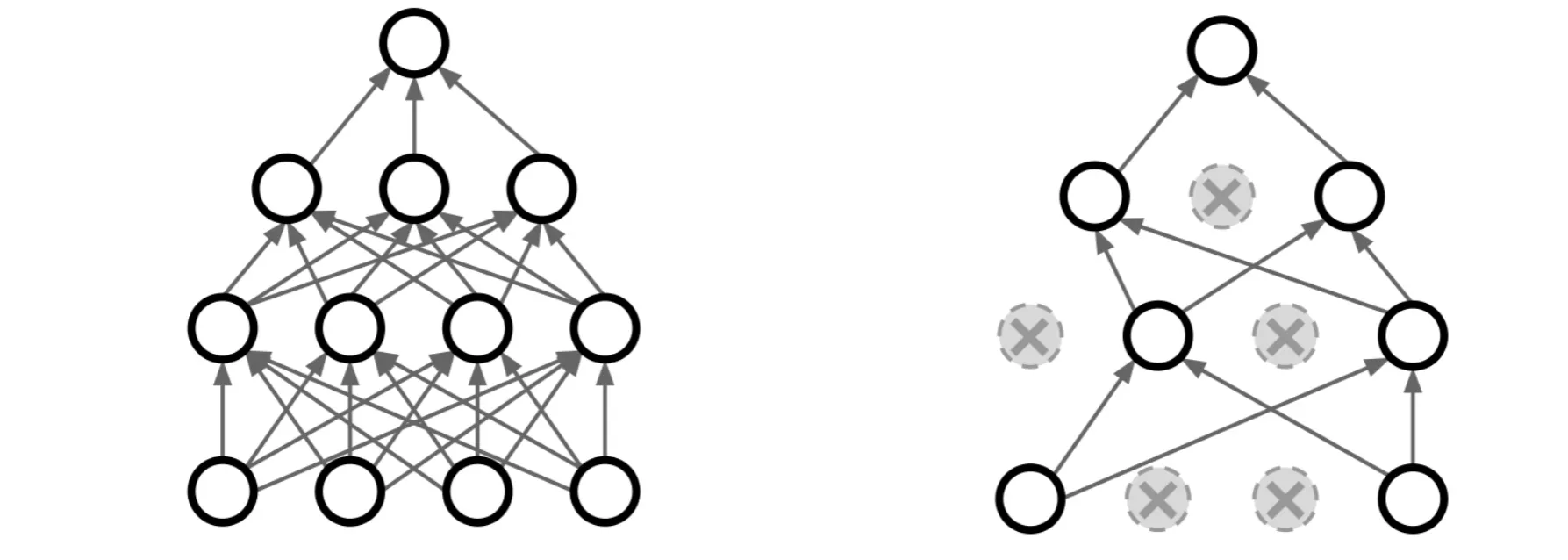
在测试的时候,不再丢弃神经元,而是使用所有的神经元,并且将它们的输出乘以,以保持训练和测试时的输出分布一致
Appendix#
BatchNorm的反向传播#
前面说过,BatchNorm层的前向传播分为四个阶段,最后的线性部分的反向传播比较简单,直接按照线性层的方式更新和即可
重要的是如何传播到BatchNorm层的输入,我们需要计算
具体可以参考这篇文章 ↗