本文内容基于 2025 秋季《计算机网络》课程讲述,如有差错,欢迎指正
传统Internet是一个尽力而为的服务模型,它并不对传输质量进行任何的保障,并且在传输时采用的是无连接的服务模式。 虽然说这种方法在今天是能够正常的工作,但在实际演进中,为了应对一系列现实中的问题或提供更好的服务,网络层引入了一系列增强技术
IPv6 协议#
IPv6 是用来取代现有的 IPv4 协议,其初始动机是 IPv4 的32位地址不够用,而 NAT 等技术无法根治此问题
- 后续一些优化:
- 简化头部格式,加快路由器的处理与转发速度
- 更好地提升服务质量(QoS)
IPv6 地址#
- 长度:128 bits(是 IPv4 的 4 倍)。地址数量约为
- 表示法:冒分十六进制(如
2001:0DA8:0000:0000:200C:0000:0000:00A5) - 简化规则:
- 前导零可省略。
- 连续的一组
0可以用双冒号::表示(全地址中只能出现一次) - 例:
2001:DA8::200C:0:0:A5。
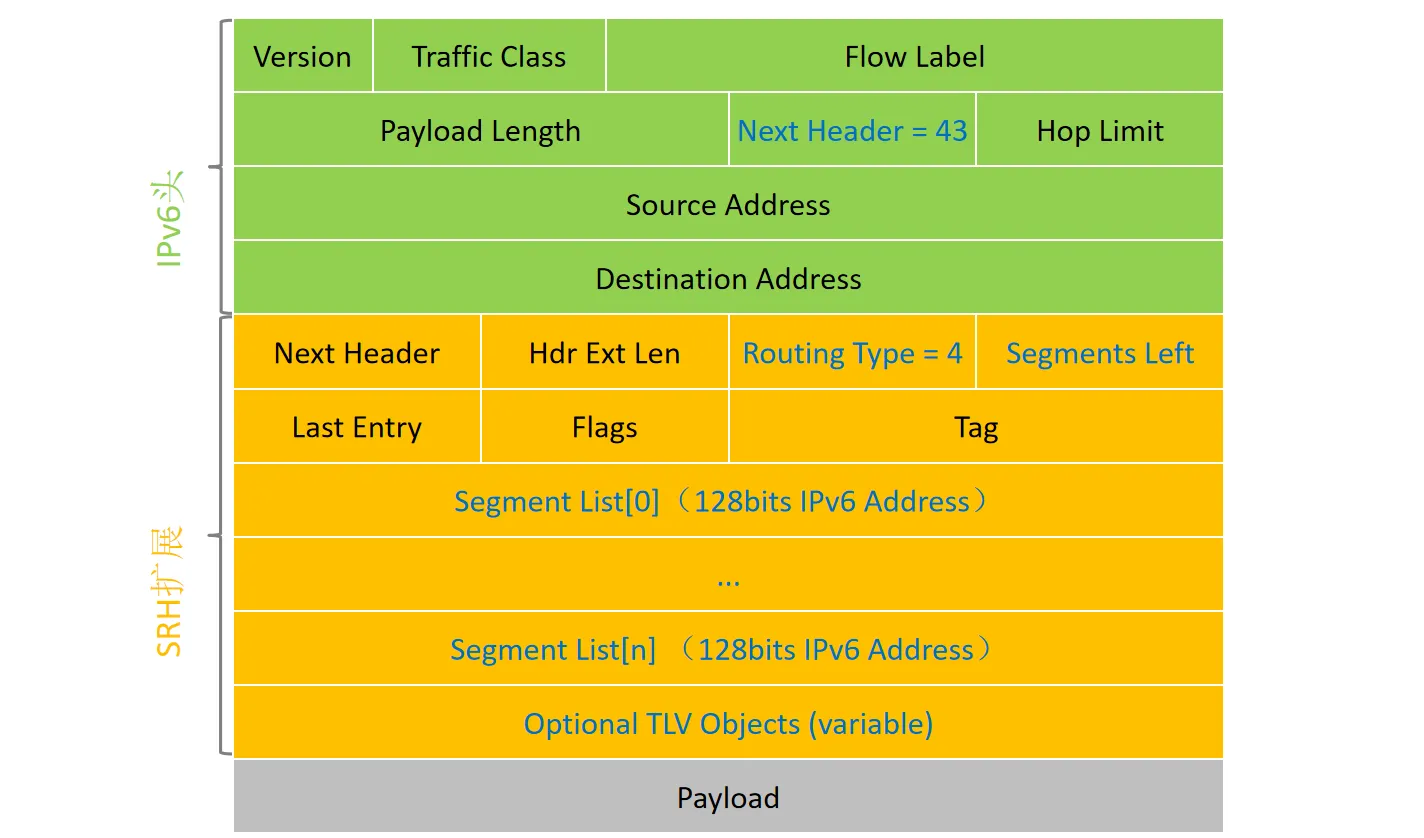
IPv6 数据报格式#
IPv6 采用了固定长度(40字节)的基本头部,以提高处理效率。
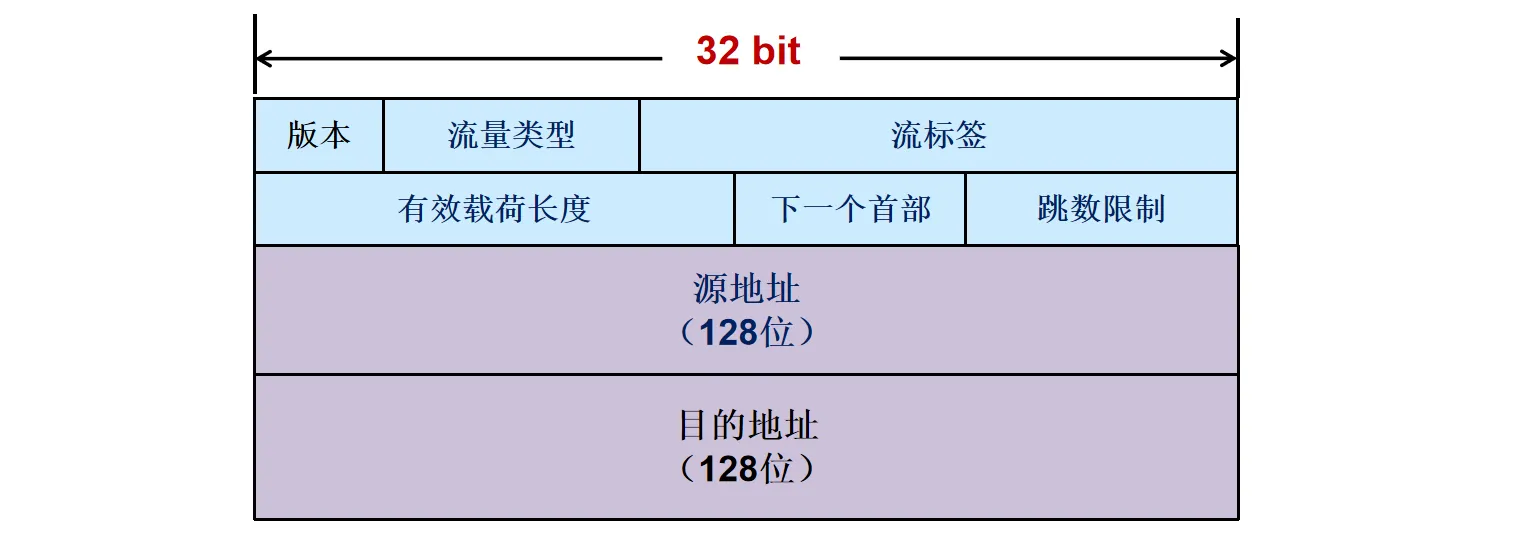
主要字段:
- 版本(Version):4bit,协议版本号,值为 6
- 流量类型(Traffic Class):8bit,用于区分数据包的服务类别或优先级
- 流标签(Flow Label):20bit,标识属于同一会话的数据流,便于路由器特殊处理
- 有效载荷长度(Payload Length):16bit,IPv6报头之后载荷的字节数(包括扩展头和数据),最大值64K
- 下一个首部(Next Header):8bit,IPv6报头后的协议类型,可能是TCP/UDP/ICMP等,也可能是扩展头
- 跳数限制(Hop Limit):8bit,类似 IPv4 的 TTL
- 源/目的地址(Source / Dest Address):128 bit
与 IPv4 的关键区别(移除的字段):
- 移除 Checksum(校验和):路由器不再进行差错校验,以此减少每跳的计算开销(依赖链路层和传输层保证可靠性)
- 移除分片相关字段:不再允许途中分片,分片字段移动到扩展头
- 移除 Options(选项):改为使用扩展头部链式连接(位于头部字段后面),通过“下一个首部”字段表明
- 移出首部长度字段:固定为 40 字节
IPv6 报文可以包含多个扩展头部,形成链表结构(用“下一个首部”字段连接),最后一个扩展头部指向传输层协议
如有多个扩展头,需按规定顺序出现,如:逐跳选项头、路由头、分段头等
IPv6 还对一些传统的协议进行了改进,以适应 IPv6 环境
从 IPv4 到 IPv6 的迁移#
IPv4协议和IPv6协议并不兼容,全球范围内的网络设备和主机无法一夜之间全部升级到IPv6
目前为了实现平滑过渡,有两种主流过渡技术:
- 翻译技术:设备同时支持 IPv4 和 IPv6,把 IPv6 数据报转换为 IPv4 数据报,反之亦然
- 与上层协议可能会有兼容性问题,比如传输层的校验和 ↗需要重新计算
- 一些字段翻译困难,如 IPv6 的流标签在 IPv4 中没有对应字段,IPv6 到 IPv4 的地址翻译需要维护大量映射信息
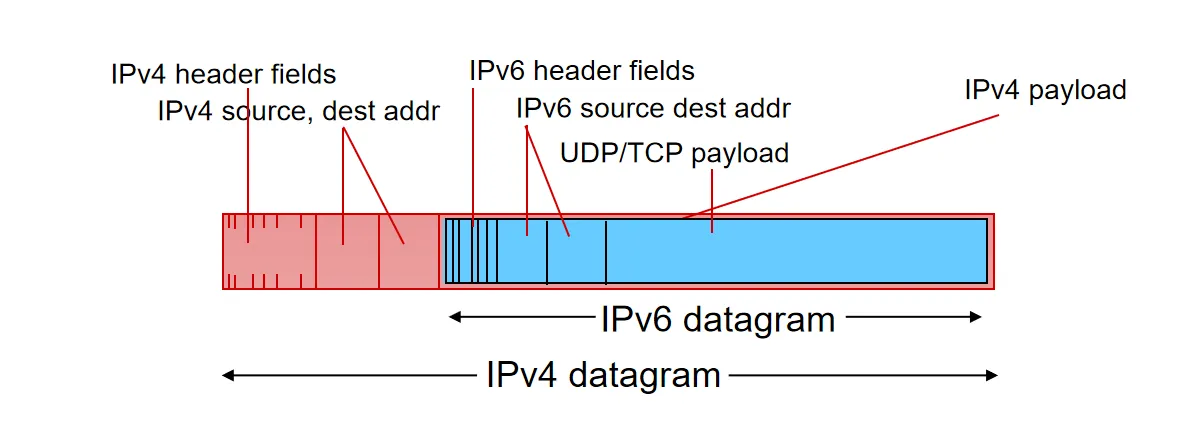
- 隧道技术:当两个 IPv6 孤岛需要穿越 IPv4 网络通信时,将 IPv6 数据报封装在 IPv4 数据报的载荷中传输
- 报文长度变化导致分片问题,可能需要进行途中分片
- 解决办法:使用路径 MTU 发现技术,发送端探测路径上的最小 MTU 并在发送端提前规划分片
面向连接的增强#
虚电路#
回顾一下电路交换 ↗的概念, 虽然电路交换的可靠性较差,任意一个节点故障都会导致整条路径不可用,需要重新分配路径,但是它的一些思想还是可以借鉴的
虚电路引用了电路交换的思想,在网络主机间建立一个逻辑连接(虚电路),分组都沿着这条逻辑连接按照存储转发方式传送, 如果不发生丢包,分组会按照发送顺序到达目的地。在这条虚电路上,我们可以实现一些面向连接的机制,比如流量控制、拥塞控制等
转发策略:
- 给每个数据包分配一个标签(虚电路号),路由器根据标签识别数据属于哪个连接,然后基于连接的规则进行转发
- 标签由各个路由器之间分布式决定,因此在每次转发时,数据包的标签可能会被修改
建立连接:
- 源主机向目的主机发送连接请求,经过一系列路由器,路由器从上一跳为该连接获取输入标签(此时不知道输出标签)
- 目的主机响应连接请求,经过相同的路由器返回源主机,路由器从上一跳获取输出标签,完成标签映射
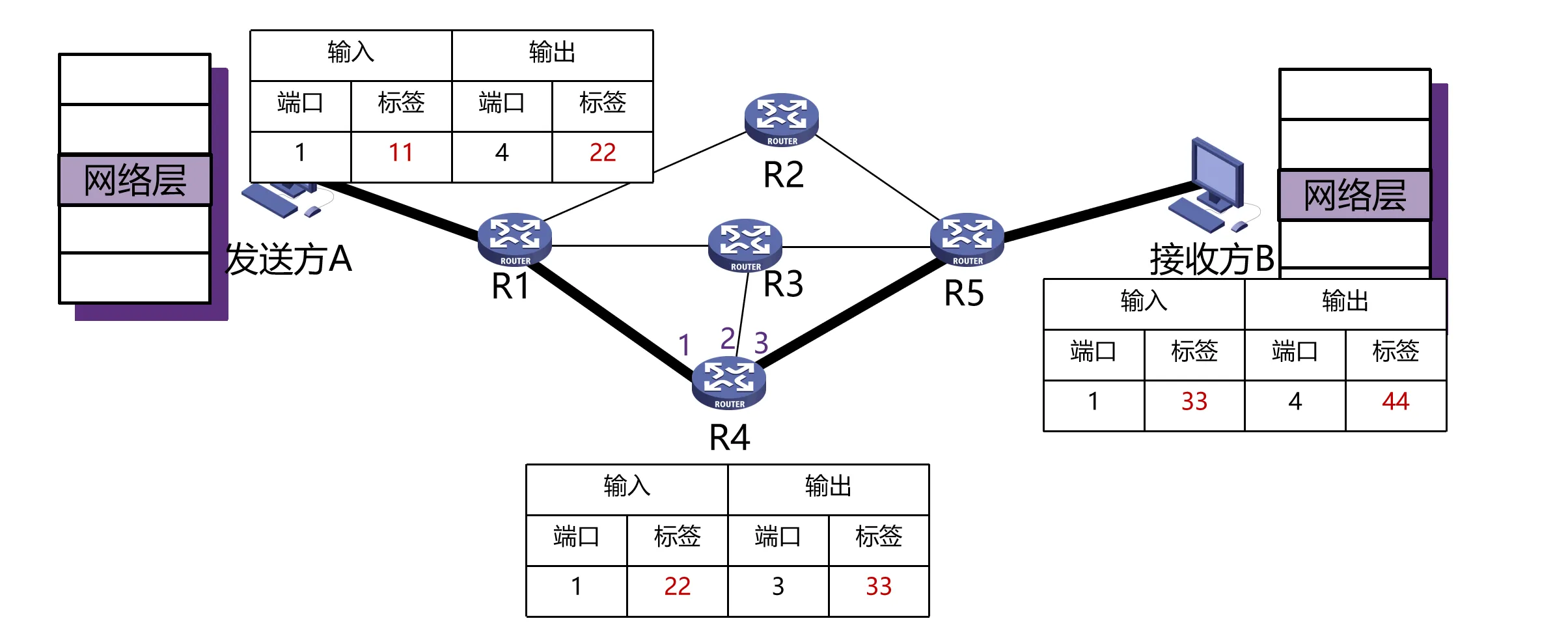
- 对R1来说,输出标签22来自R4,数据返回时获取;输入标签11来自发送方,数据发送时获取
关闭连接时,某一方发起连接释放请求,另一方确认后,路由器删除对应的标签映射
MPLS#
MPLS(多协议标签交换) 在思想上非常类似于虚电路,把网络层基于IP地址的转换改成基于标签的转换,设计初衷是为了提高查找速度。 可以认为它是虚电路的一种实现方式,但应用场景更加广泛
其具体做法是在链路层头部和网络层头部之间插入一个 4 字节的 MPLS 标记,因此MPLS又被称为2.5层协议
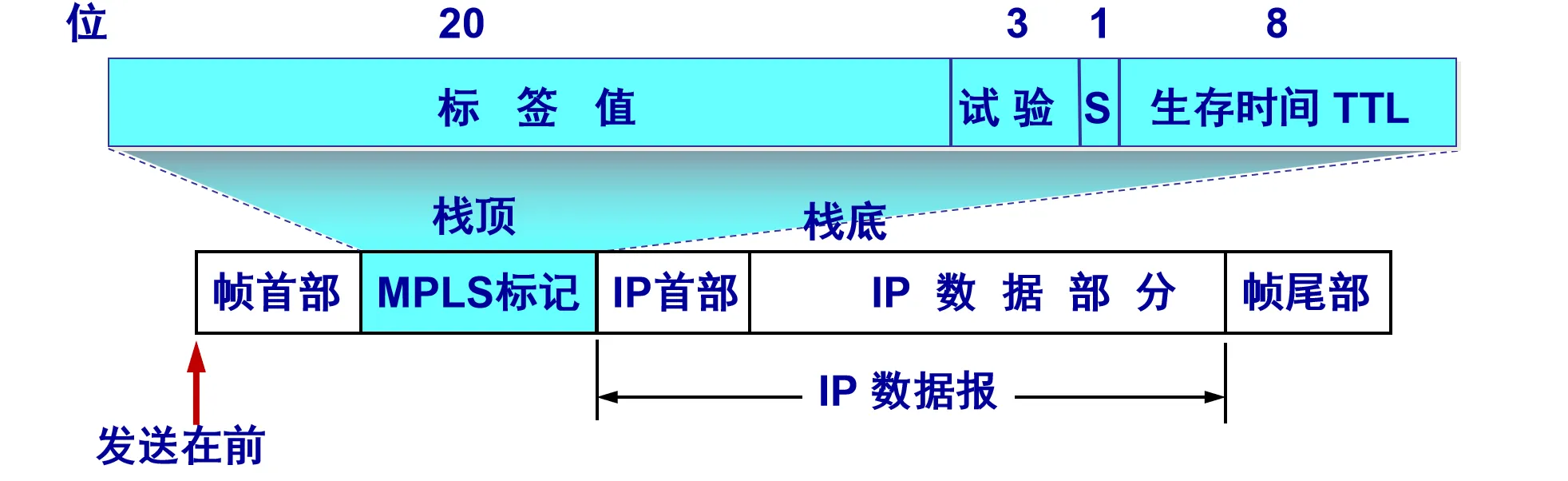
由于基于标签转发的特性,MPLS 上层可以采用多种协议(如 IPv4、IPv6),有时候又被称为网络链路的虚拟化。
因为 MPLS 需要新的操作,故需要一些新的网络设备(LSR)去支持,这种路由器具备标签交换和路由选择功能。 MPLS 与传统的 IP 网络是共存的,由一组相邻的 MPLS 路由器组成的子图称为 MPLS 域。 此外,LSR 之间通过标签分发协议(LDP)交换标签映射信息,建立标签转发表
MPLS 的工作过程分为三个阶段:
- 加标签:在进入 MPLS 网络边缘时,路由器在 IP 头之前插入 MPLS 标记
- 标签交换:核心路由器(LSR)仅查看 MPLS 标签,查找标签转发表,将
(入接口, 入标签)替换为(出接口, 出标签)并转发(类似虚电路) - 去标签:离开 MPLS 网络时,去掉标签,恢复 IP 转发
数据平面上存储能力有限,不可能为一组数据包分配唯一标签,因此 MPLS 将相同操作的数据包归为一类(比如目的IP有相同前缀), 构成一个转发等价类FEC,同一 FEC 的数据包使用相同的标签进行转发
MPLS 的一些应用场景
- 流量工程:对流量打上不同标签,使其经过不同路径
- VPN:用标签区分不同VPN的数据,与各自IP地址无关
VPN#
虚拟专用网络(VPN) 是建立在公网上的,通过加密与认证机制,保持逻辑上的隔离的一种专用网络(物理上并未实现隔离)
下面介绍通过隧道技术实现的 VPN
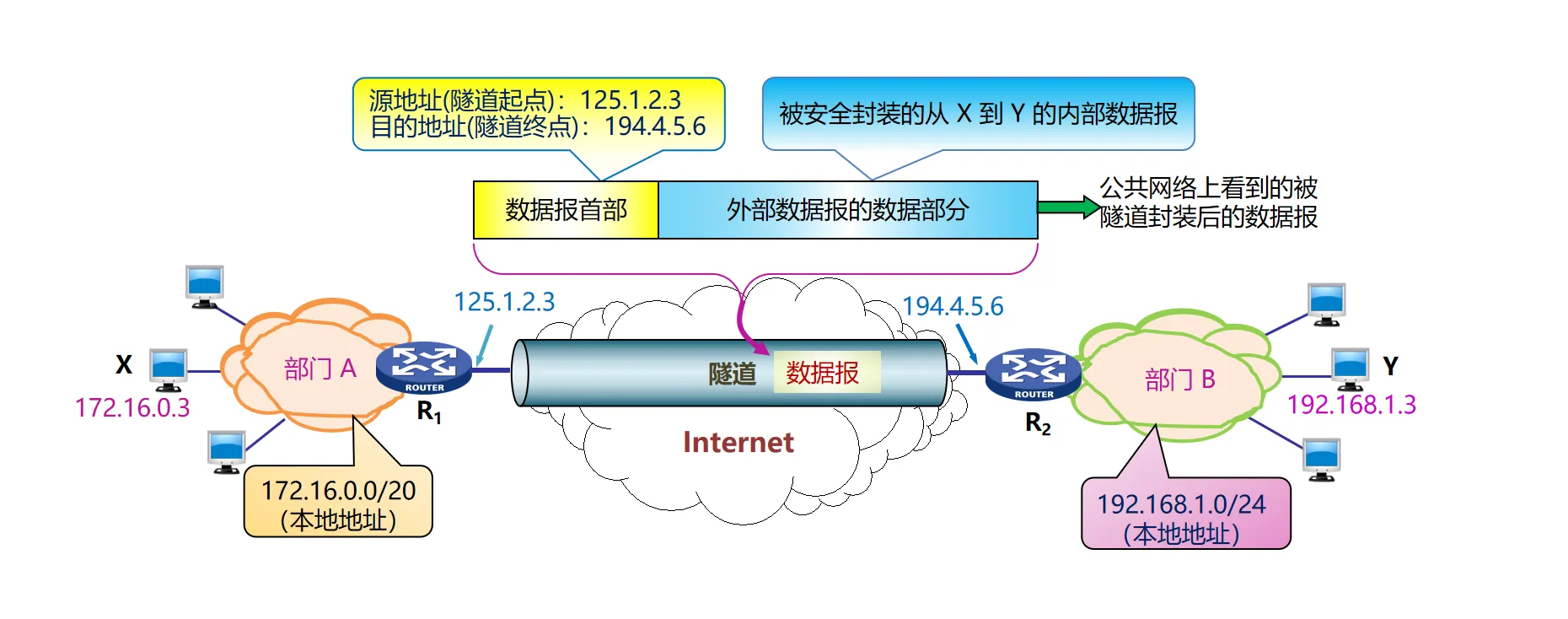
隧道技术:2个相同类型网络的设备,跨越中间异构类型网络进行通信
- 将一种网络的数据包作为另一种网络的数据载荷进行封装
- 在介绍 IPv6 隧道时已经提到这个技术
当数据包到达边缘路由器时,边缘路由器将数据包进行加密与封装,形成新的数据包,然后通过公网上传输。 到达目的边缘路由器时,进行解封装与解密,恢复原始数据包
VPN技术通过加密和认证机制,确保数据机密性与完整性
服务质量增强#
服务质量指在传输的过程中需要满足一系列的性能指标,比如带宽、时延、抖动等
为了保障服务质量,如今有以下几种方法
数据包调度#
在路由器输出端口上决定如何发送数据包,详见数据包调度 ↗
流量工程#
之前讲到SDN和MPLS时提到过流量工程的概念,这里我们简述一下流量工程对于如何分配流量的计算
路径选择:
网络中从源主机到目的主机,一定有很多路径可以传输,我们并不会把所有的路径都放进来考虑,而是事先选择好一些路径
通常有多种策略:
- k-最短路径:选择前k条最短路径
- 链路互不相交最短路
- Oblivious Routing(一种专门的路由技术)
流量分配:
有了这些路径,如果知道了各个源和目的之间的传输需求,我们该怎样的把这些需求分配到这些路径上进行传输
这里我们采用线性规划的方法进行计算
输入:
- 网络拓扑:
- : 结点集合(主机、子网、AS、数据中心)
- : 边集合
- : , 每条边的权重
- 流量矩阵 (需求矩阵) :
- :从 s 到 t 所需要传输的流量
- 网络路径:
- : s 到 t 可选路径集合(第一阶段计算结果)
输出: 路径权重 (流量分配): F
- : 将需要传输的流量 分配至 里的各个路径上的比例值
- 是“网络路径 非负值”的映射
约束条件:
- 为每个“源-目的”分配的总比例值不超过1
- 不超过每条边的容量
优化目标:
- 最小化最大链路利用率:
- 最大化总吞吐
- 为传输速率限制
- 最大化满足“源-目的”传输需求
- 为传输速率限制
线性规划的缺点:
- 输入流量依赖经验(如:历史数据)
- 多个目标难以兼容
- 线性规划计算量大,难以支持大型网络
流量整形#
流量整形(Traffic Shaping) 其作用是限制流出某一网络的某一连接的流量与突发,使这类报文以比较均匀的速度向外发送
下面介绍两种常见的流量整形算法:
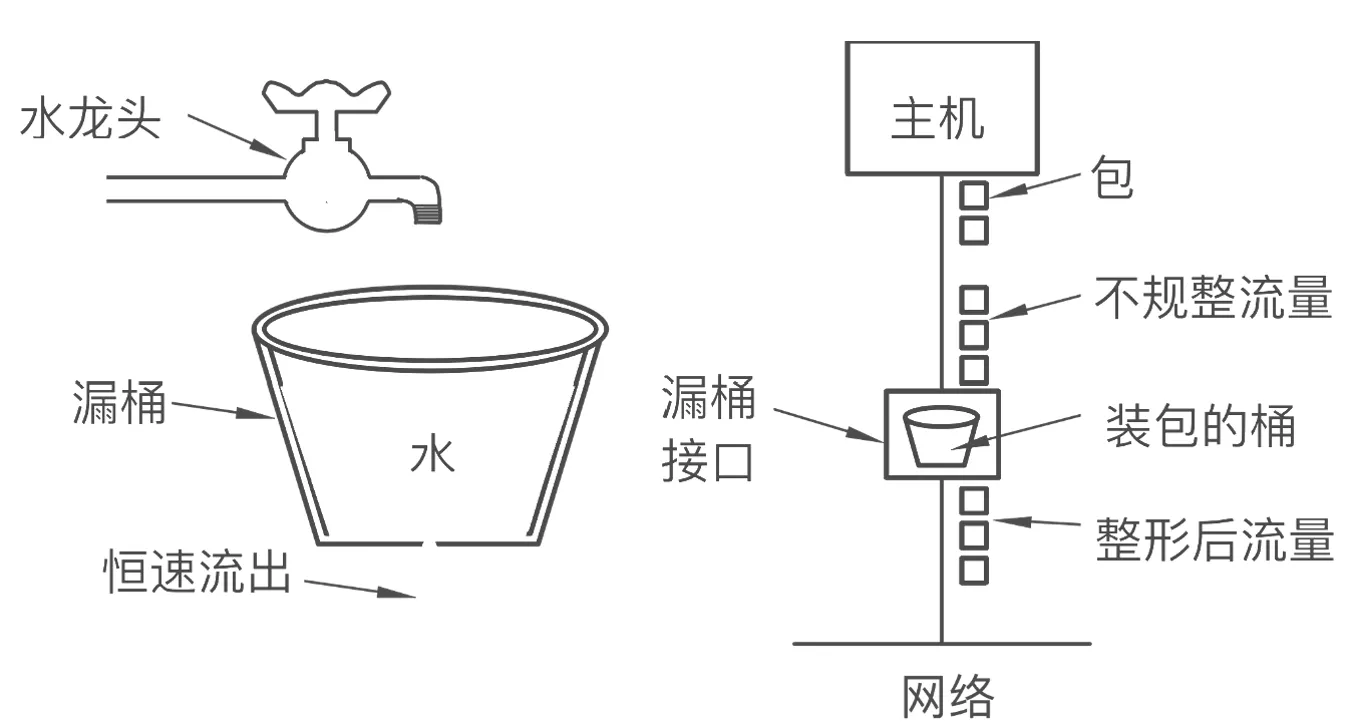
漏桶算法 (Leaky Bucket):
原理:
- 到达的数据包被放在缓冲区(漏桶)中
- 漏桶最多可以容纳个字节。如果数据包到达的时候漏桶已经满了,那么数据包应被丢弃
- 数据包从漏桶中发出,以常量速率(字节/秒)注入网络,因此平滑了突发流量
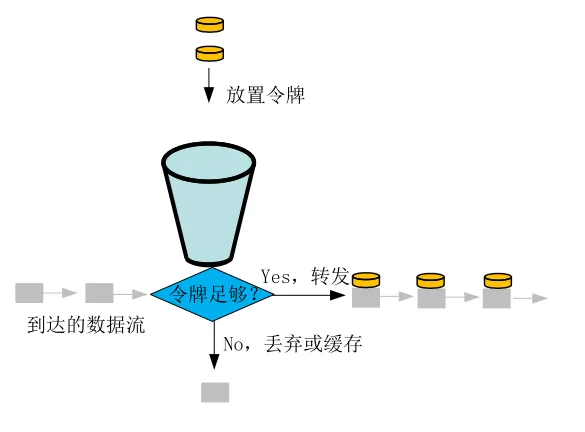
令牌桶算法 (Token Bucket):
原理:
- 系统以恒定速率向桶中放入令牌,桶中令牌达到上限时,丢弃多余令牌
- 每个数据包到达时,必须从桶中取出一些令牌,才能发送该数据包,取出令牌的数量与数据包大小有关,一般数据包越大,取出的令牌越多
- 如果桶中令牌满足需求,则将数据包发送,否则丢弃
综合服务与区分服务#
综合服务:类似电路交换,建立连接,预留资源,保证服务质量。但是现实中难以实现
区分服务:使用IP头部中的区分服务字段(DSCP),对不同类别的数据包进行不同的处理,从而实现服务质量保障
- 网络“公地悲剧”:所有数据包都要求高优先级,导致无法区分
分段路由#
在传统的 IP 路由中,路由器根据目的地址查找路由表,每一跳都独立决定下一跳去哪(逐跳转发)。 而在分段路由(SR)中,发送端(或者网络的入口边缘路由器)在数据包出发前就已经决定好了它要经过的完整路径,因此被称为“源路由”技术
- 源路由:发送端(或入口路由器)在数据包头部直接压入一个有序的指令列表,指定数据包要经过的节点或链路
- 中间路由器不需要维护复杂的流状态,只需根据指令转发
SRv6#
利用 IPv6 的扩展头部来实现的SR技术
- SRH: 分段路由扩展头部
Segments Left:剩余的路由段数,即在到达最终目的地之前仍需访问的显式列出的中间节点的数目,每经过一个节点减1Segment List:一组 IPv6 地址,表示数据包要经过的路径。Segment List[0]包含路径的最后一段。