本文内容基于 2025 秋季《计算机体系结构》双语班课程讲述,如有差错,欢迎指正
NAND Flash 基础特性#
Program & Erase:
- Program 单位: Page。一个 Page 由多个存储单元组成,共享同一 word line (Control Gate line) 。
- Erase 单位: Block。一个 Block 是一组 Page,共享同一衬底 (Substrate)
“先擦后写”特性 (Erase-before-write):
- 一个 Page 一旦写入数据,在其对应的整个 Block 被擦除之前,不能被覆盖写入(即不能就地更新)
在这种限制下,我们怎么实现对某一页的多次更新呢?
Flash Translation Layer (FTL)#
我们只需要让用户认为他们可以就地更新数据即可
核心思想: 用户请求的逻辑地址 闪存上的物理地址
SSD内部维护一套地址映射机制,将用户请求的逻辑地址转换为实际存储数据的物理地址,把数据写入物理地址 实现把就地更新转换为 Out of Place Update
Flash Firmware 中的 Flash Translation Layer (FTL) 负责完成这个功能,此外,FTL 还负责垃圾回收 (Garbage Collection) 、磨损均衡 (Wear Leveling) 、并行化和负载均衡 (Parallelization and load balancing, 不同闪存芯片之间) 、 坏块管理 (Worn-out block Management) 等功能。
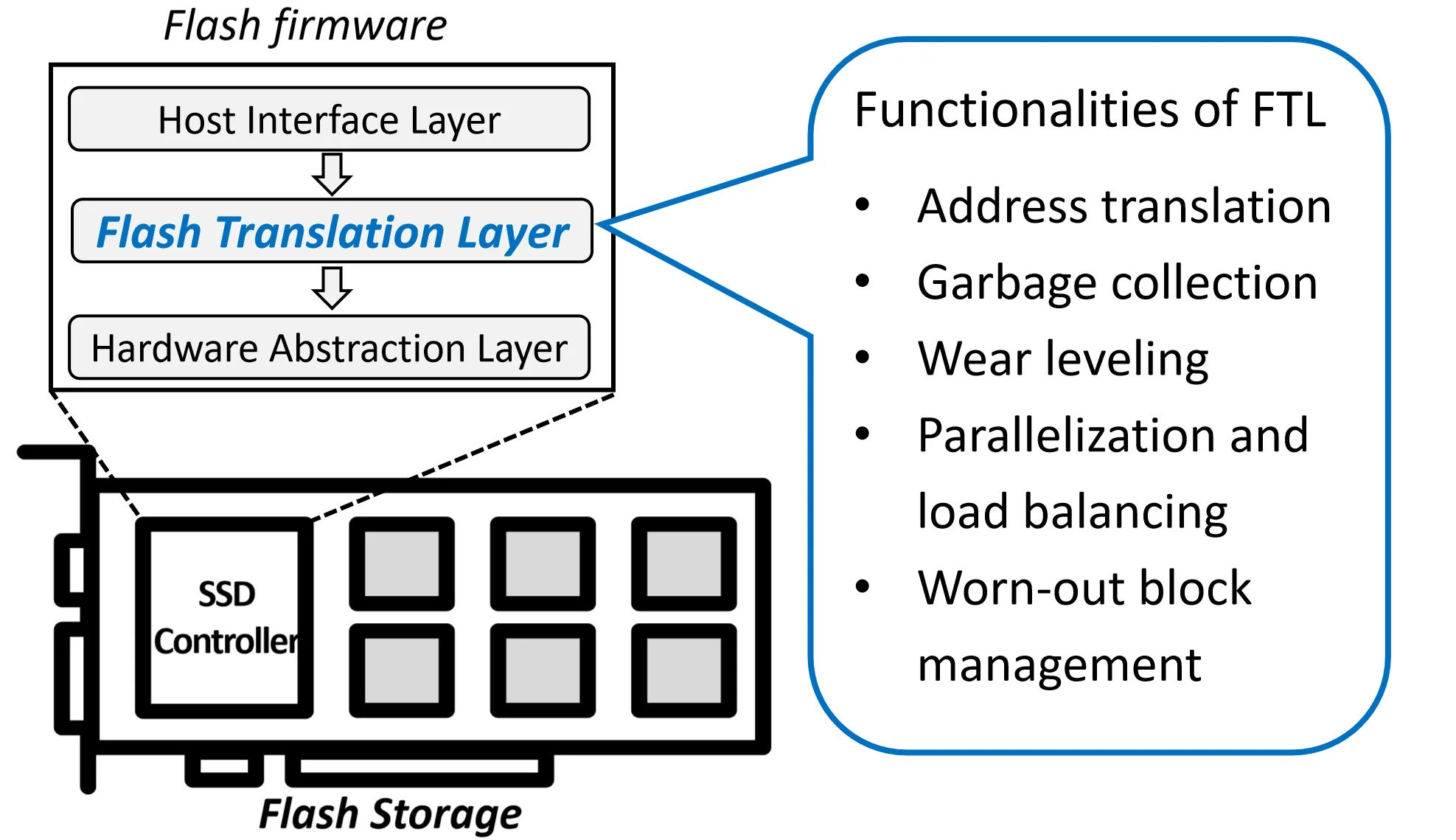
FTL通过维护一张映射表 (Mapping Table) 来实现逻辑地址到物理地址的转换。
- 索引 (Index): 逻辑页地址 (Logical Page Address, LPN) 。
- 值 (Value): 物理页地址 (Physical Page Address, PPN,即 Block# + Page#) 。
SSD 读取数据过程:
- Host 发送读取请求,指定逻辑页地址 LPN 给闪存芯片
- 闪存芯片查找Mapping Table,找到对应的物理页地址 PPN
- 通过 PPN 找到对应的物理存储单元,把数据通过DMA返回给 Host
SSD 写入数据过程:
- Host 发送读取请求,指定逻辑页地址 LPN 给闪存芯片, 并通过DMA把数据送到闪存芯片的DRAM上
- 闪存芯片检查Mapping Table,如果该地址已经存在映射,则将其 Invalid, 再重新分配一个新的物理页地址 PPN, 如果空闲页不够,则触发垃圾回收
- 将数据写入新的 PPN
写一般比读要复杂
Mapping Table#
映射表这么重要的东西,放在哪里呢?
我们来看一下SSD的结构
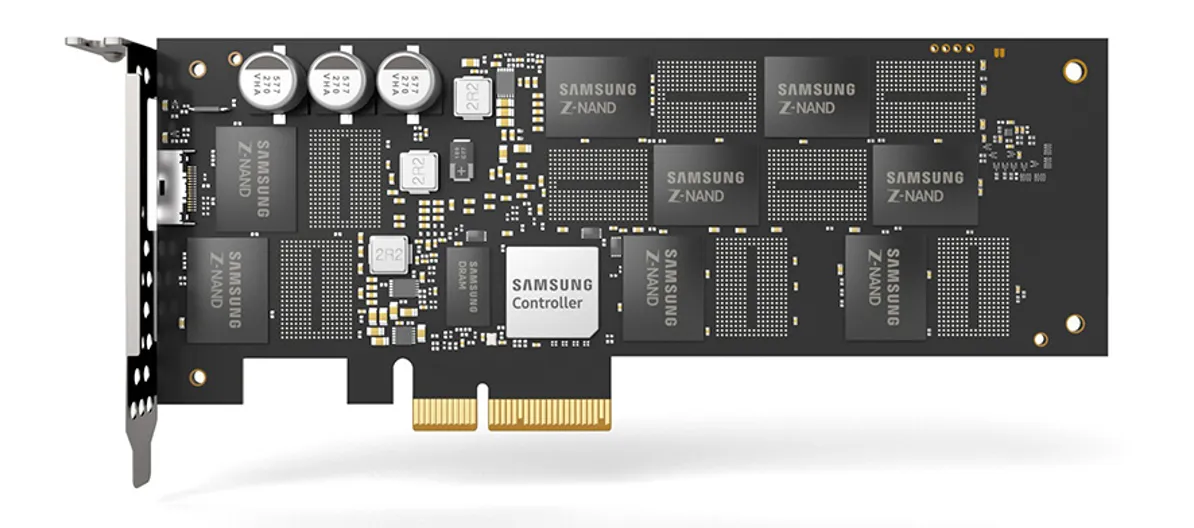
主体黑色的大多是闪存芯片,中间银白色的是控制器 (Controller),其左侧是DRAM芯片,左上角是电容
- 电容可以在断电时为控制器和DRAM提供短暂的电力,进行一些操作以防止数据丢失
在运行时,映射表一般存放在DRAM中,这样能够更快进行查找和更新。与此同时,Mapping Table也在Flash中有备份,以防止断电时数据丢失。
实际实现中,NAND Flash每一页不只是存数据,每一页分为了两个部分: Spare Area 和 Data Area
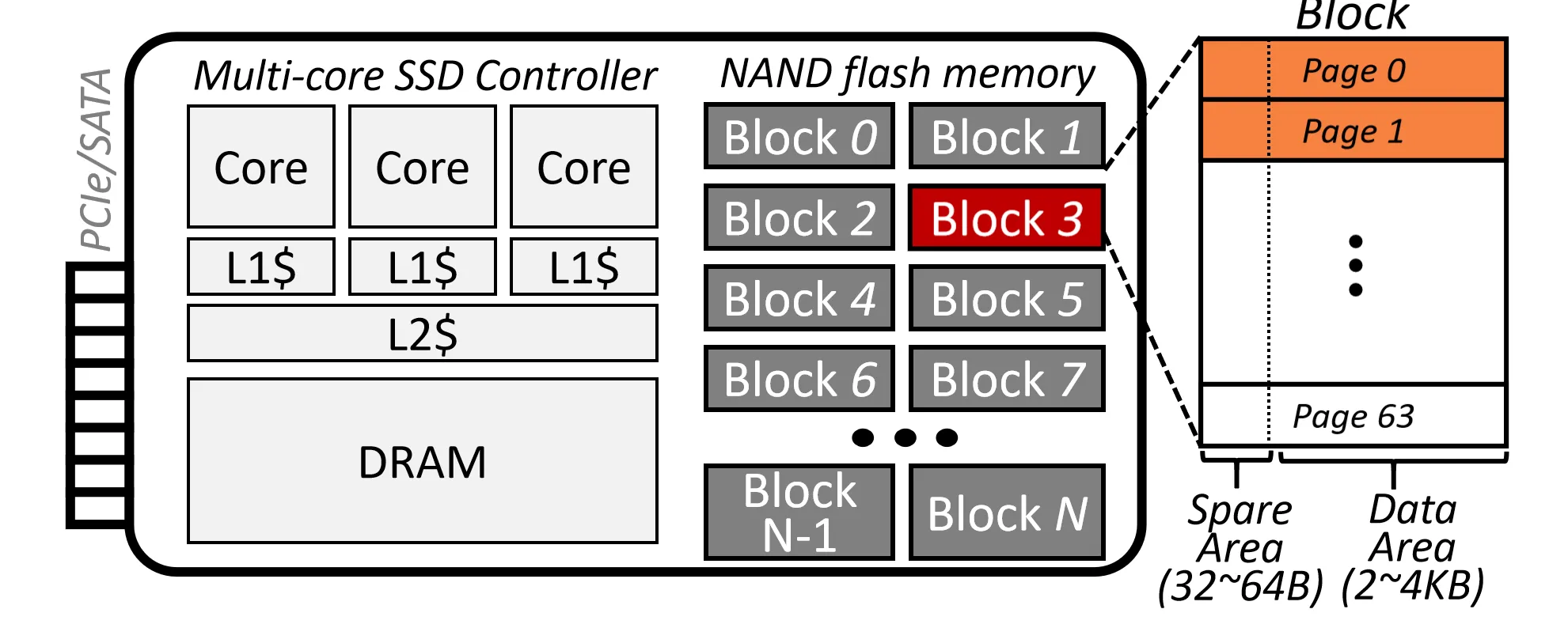
Spare Area 存放一些元数据 (Metadata),包括:
- 逻辑页地址 LPN, 遍历物理页即可构建Mapping Table
- 纠错码 , 用于检测和纠正数据错误
每个Block的前2-3页 也会存放Mapping Table的一部分
其他元数据#
SSD 还需要维护其他一些元数据:
- Invalid Flag: 标记某个物理页是否有效
- Erased: 哪些 Block 已经被擦除,可以被分配
- Sequence Number: Block 中下一个会被写入的 Page
- Valid Page Count: Block 中有效 Page 的数量,用于垃圾回收时选择擦除对象
每个Page要存的:Logical Page Address, ECC, Invalid Flag, etc..
每个Block要存的:Erased, Sequence Number, Valid Page Count, etc..
在哪里存储?
- Page 级别的元数据存放在每个 Page 的 Spare Area 中
- Block 级别的元数据:
- centralized: 在专门的 Block 中存储 Block Info Table
- distributed: 分散存储在每个 Block 最后一页的 Spare Area 中
对于写操作的模拟 (Page-level Mapping)#
下面假设我们有一个简单的SSD,包含1024个Block,每个Block有1024个Page
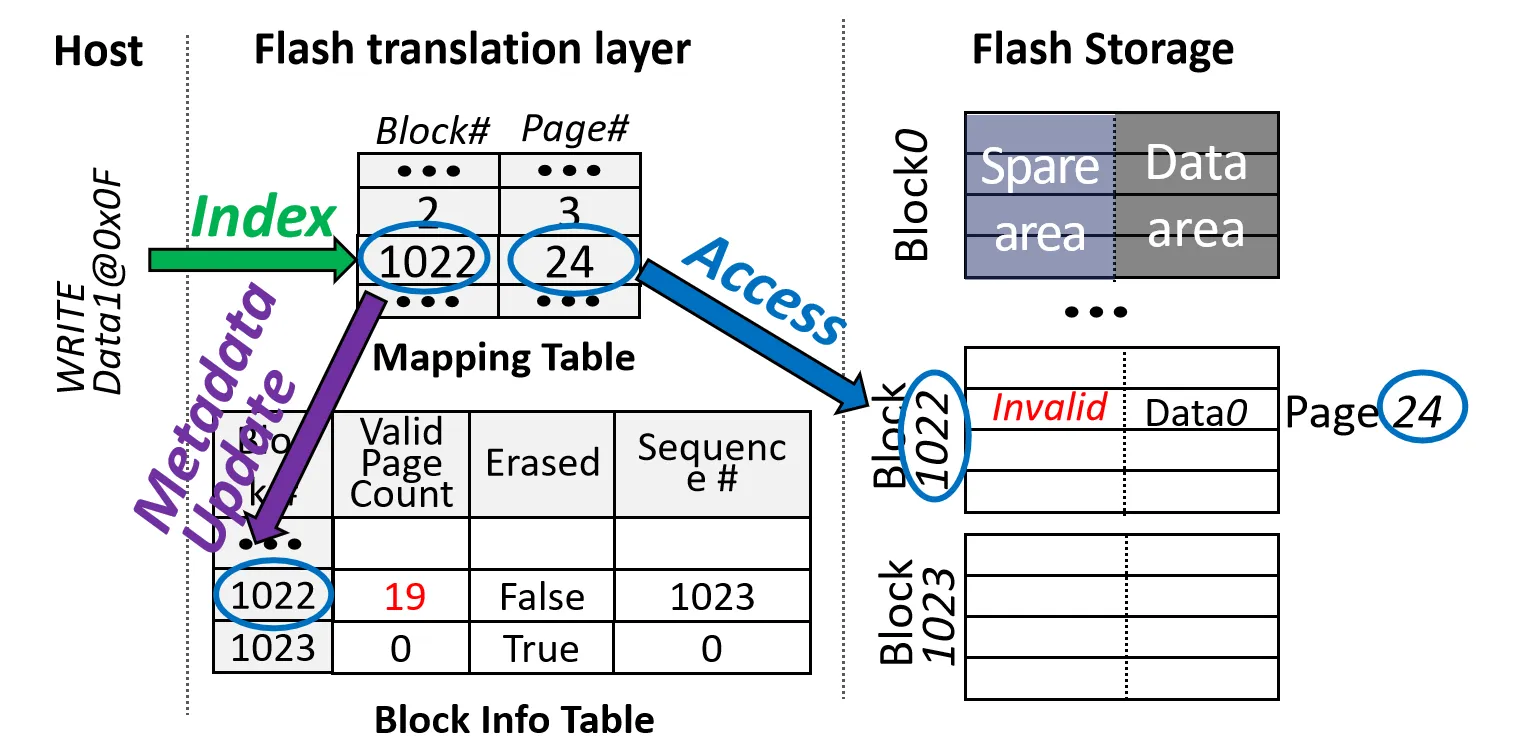
Phase1: Page Invalidation
目标: Invalidate 先前分配的物理页
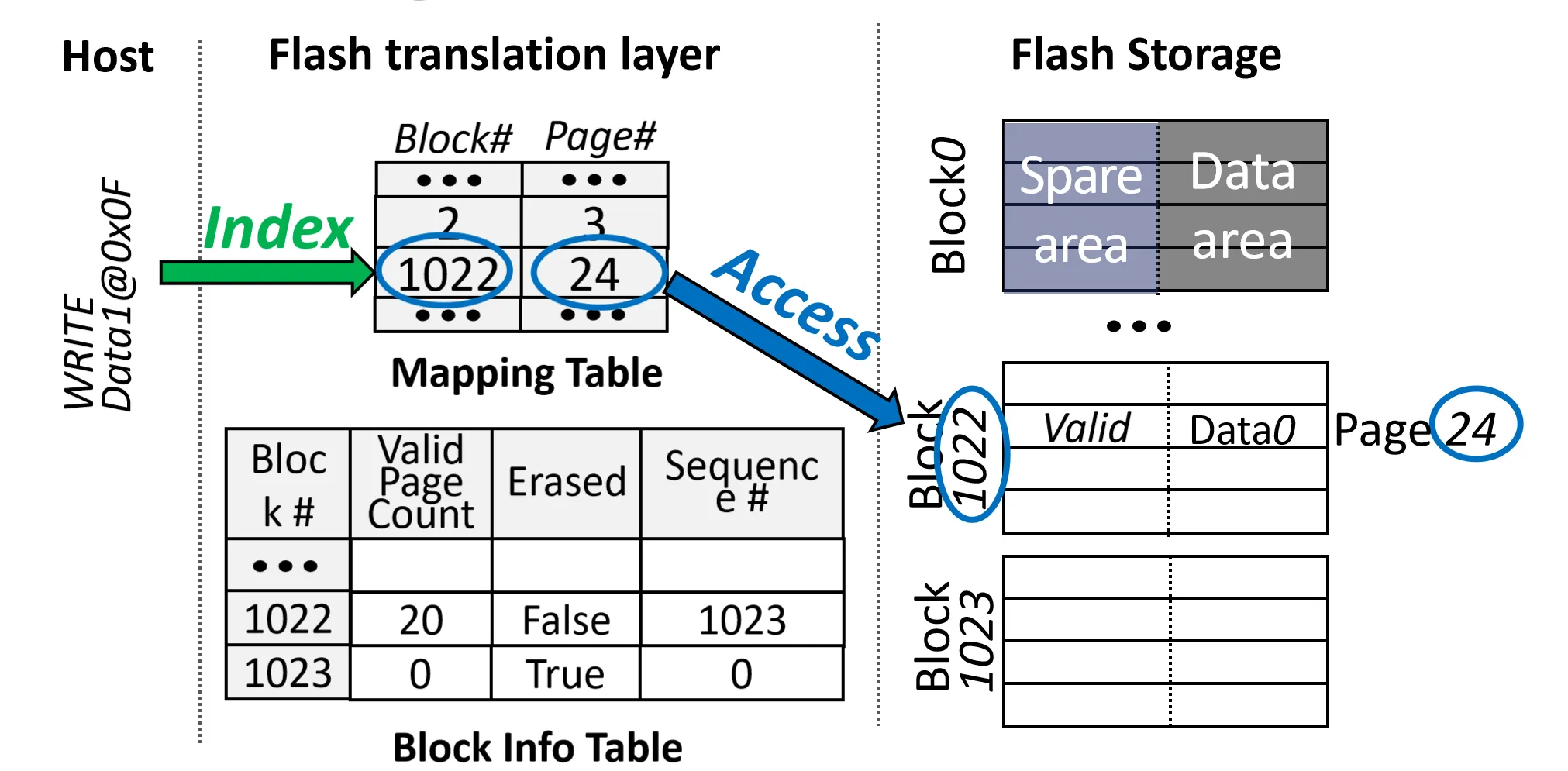
- 根据Mapping Table找到对应的 Block 和 Page (Block 1022, Page 24)
- Invalid 掉该 Page
- 修改 Block Info Table 中的 Valid Page Count, 修改Mapping Table中该地址对应的 Page
Phase2: Free Flash Resource Allocation
目标: 为新的目标逻辑页分配一个新的物理页
Step1: 写Data1 到逻辑页地址 LPN=0x0F
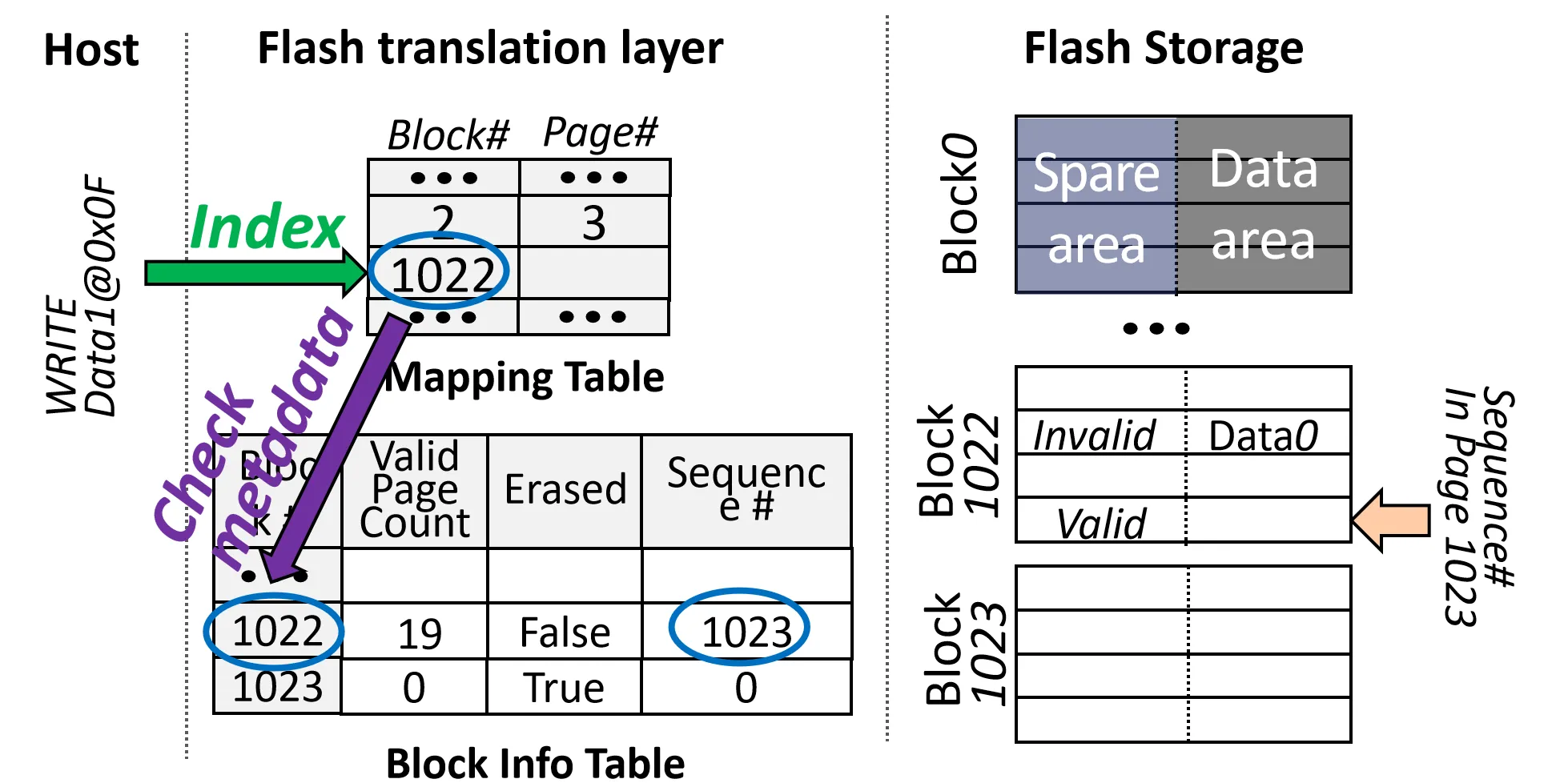
- 根据Mapping Table找到对应的 Block (Block 1022)
- 根据 Block Info Table 中的 Sequence Number 找到下一个可用的 Page(1023表示下一个可用的Page是1023)
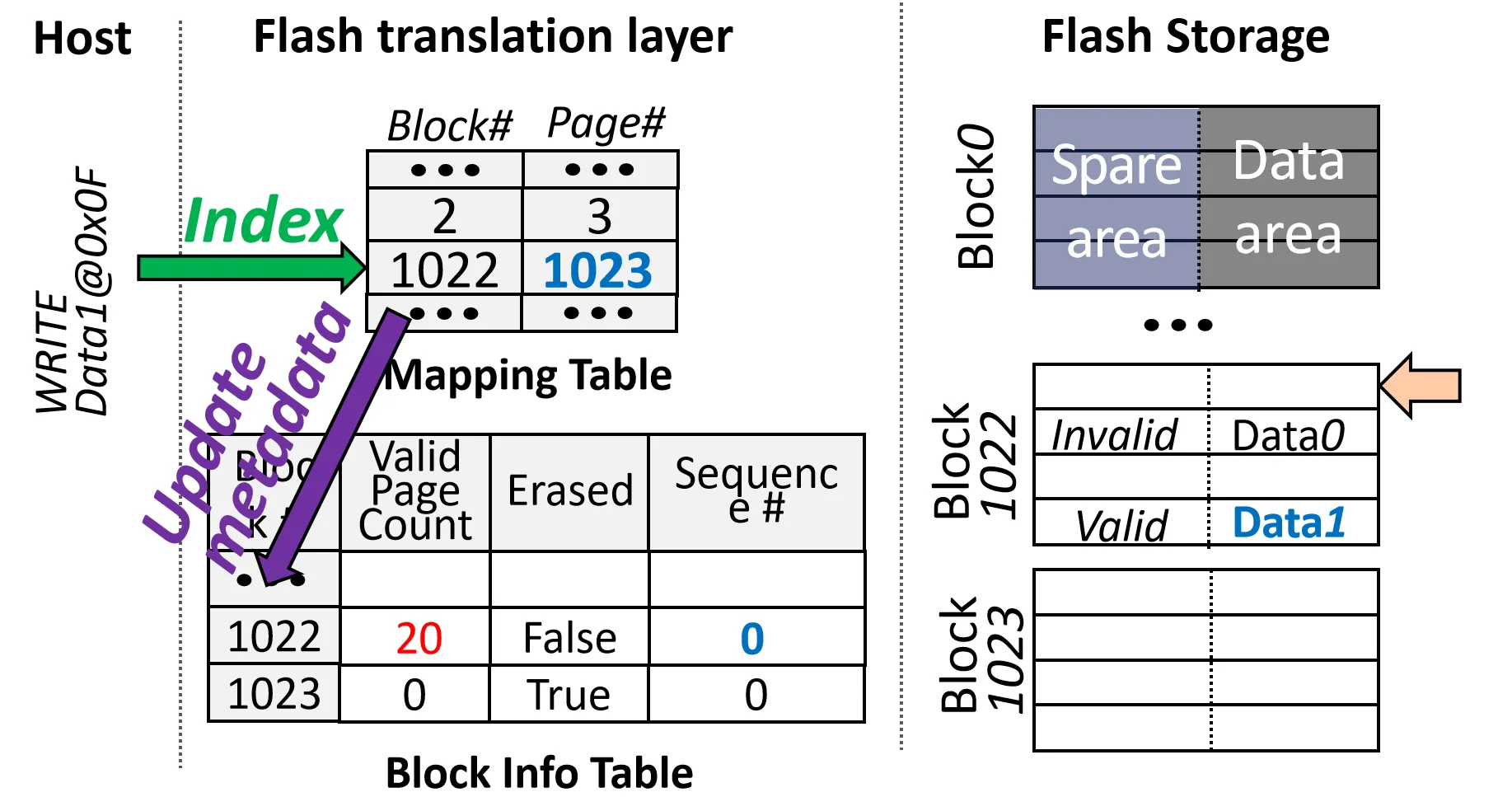
- 修改Mapping Table中该地址对应的 Page, 把结果写入新的 Page
- 修改 Block Info Table 中的 Sequence Number 和 Valid Page
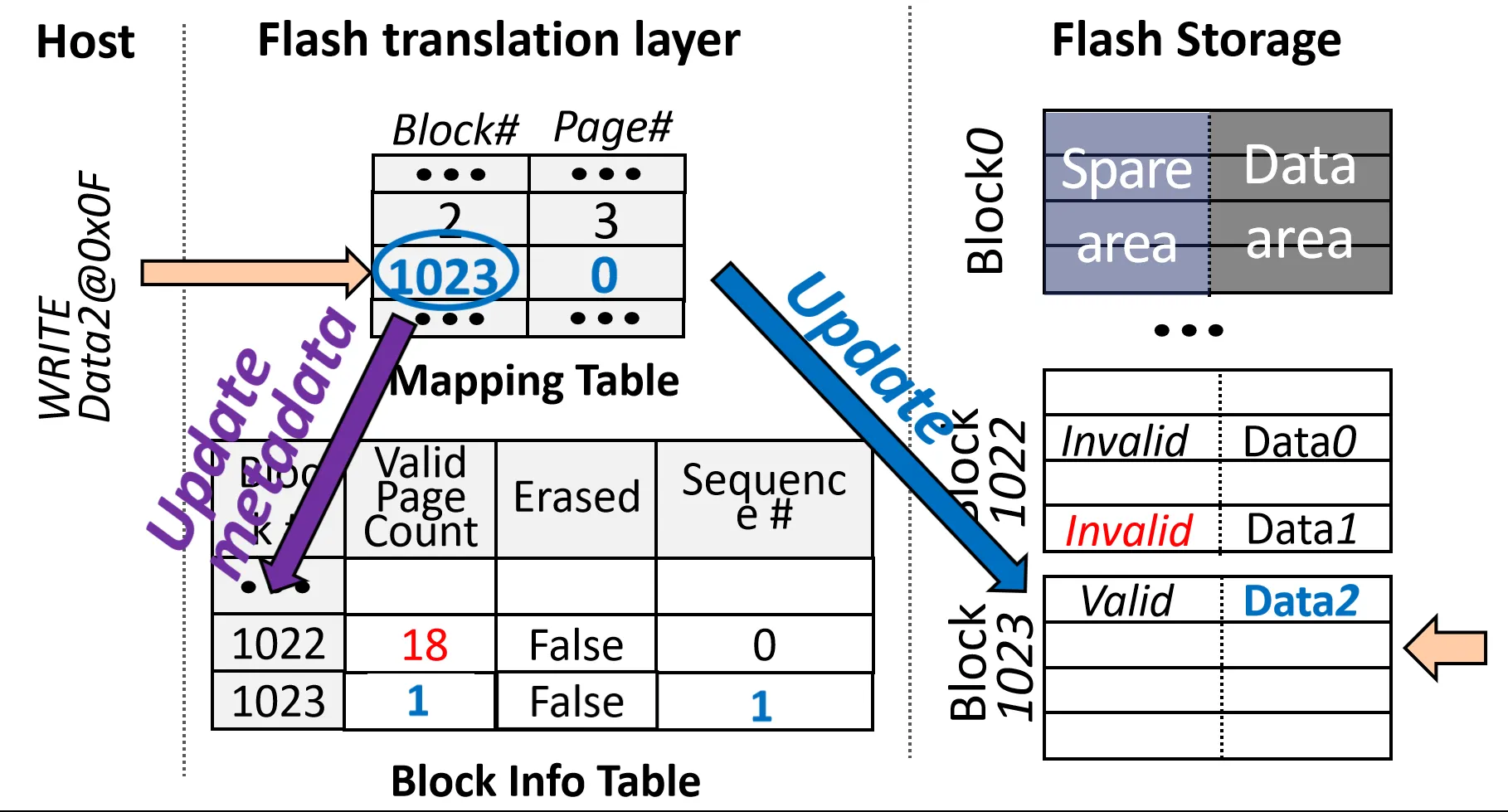
Step2: 写Data2 到逻辑页地址 LPN=0x0F
此时由于该地址已经被写过了,需要先 Invalidate 先前的 Page。 再查Block Info Table 中的 Sequence Number,发现该Block已经被写满了。 于是寻找有没有被Erased的Block(Block 1023),把该Block分配给该逻辑页地址, 此后过程和上面类似。
Phase3: Garbage Collection
目标:找到恰当的 victim Block 并 Erase 他们
触发条件:free Block的数量低于某个预先设定的阈值时(这只是一种方式,实际上很复杂)
如何选择 victim Block?
- 选择有效页数量最少的 Block,这样需要copy的Page数量最少 (一个naive的策略,实际上还有很多种方式)
Step1: 选择 victim Block
Step2: 选择合适的 free Block 进行数据迁移
Step3: 把 victim Block 上的有效页 migrate 到 free Block 上,同时更新Mapping Table和 Block Info Table
Step4: Erase victim Block, 并更新 Block Info Table
Complexities of FTL#
这里介绍的是非常简化的 FTL 机制, 实际上 FTL 的实现非常复杂,下面是一些更复杂的机制:
- In-page valid/invalid bits are insufficient for efficient random access and garbage collection
- Reverse Mapping Table with valid/invalid bitmap
- Enables quick logical to physical address translation in FTL
- Facilitates faster identification of invalid data for optimized garbage collection
- Wear Leveling Considerations
- Recording P/E cycles for each block to monitor the wear level
- A dedicated data structure is employed in FTL to sort blocks based on the wear level
关于掉电时可靠性(fault tolerance) 的一些问题:
- GC进行 Migration(Step3) 时掉电
- 可以先进行Migration,再更新Mapping Table和 Block Info Table
- GC进行 Erase victim Block 时掉电
元数据的重建:
如果重建元数据时需要遍历所有的 Page 和 Block, 那么重建时间会非常长, 影响系统的可用性
- 我们可以周期性把元数据 dump 到 Flash 上, 这样重建时只需要读取最近的元数据即可
- 可以记录上一次 dump 之后的操作日志
其他映射方式#
Page-level Mapping 的不足:
- Mapping Table 太大, 需要大量的 DRAM 空间
- 掉电后重建 Mapping Table 需要很长的延迟
直观的解决方案: 使用更粗粒度的映射,比如 Block-level Mapping(和操作系统中的大页类似)
Block-level Mapping#
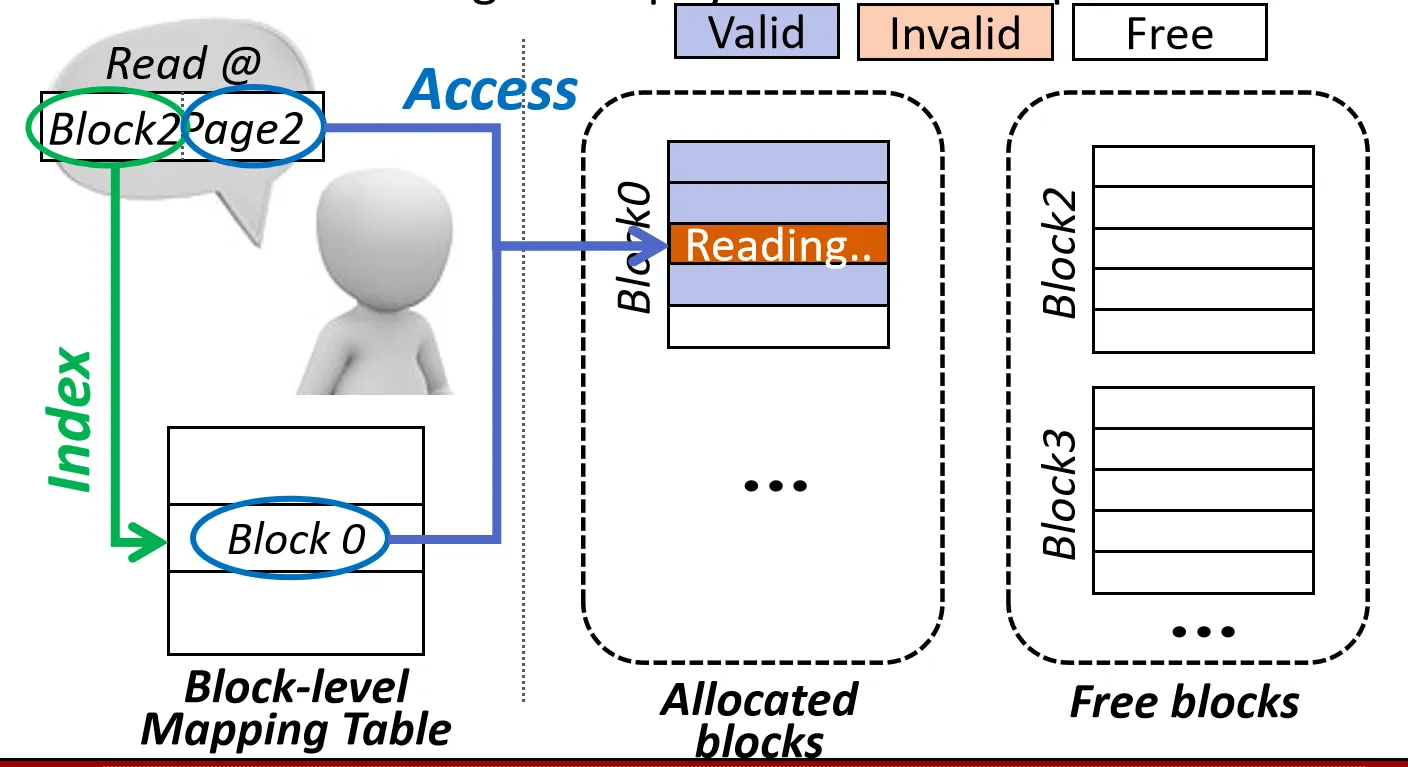
Read Operation
和 Page-level Mapping 不同,page Number 未被映射,作为 Block 内偏移量, 只有 Block Number 会从逻辑地址映射到物理地址
Write Operation
由于 Block-level Mapping 只能映射到 Block 级别, 所以无法分配单个 Page, 只能对整个 Block 进行更新(分配一个新的 Block),需要拷贝该 Block 所有有效 Page 到新的 Block 上
- 先Invalid 对应的页
- 分配一个新的 Block, 修改Mapping Table 中该地址对应的 Block
- 把旧 Block 上的有效 Page 和要写的新数据 迁移到新 Block 上
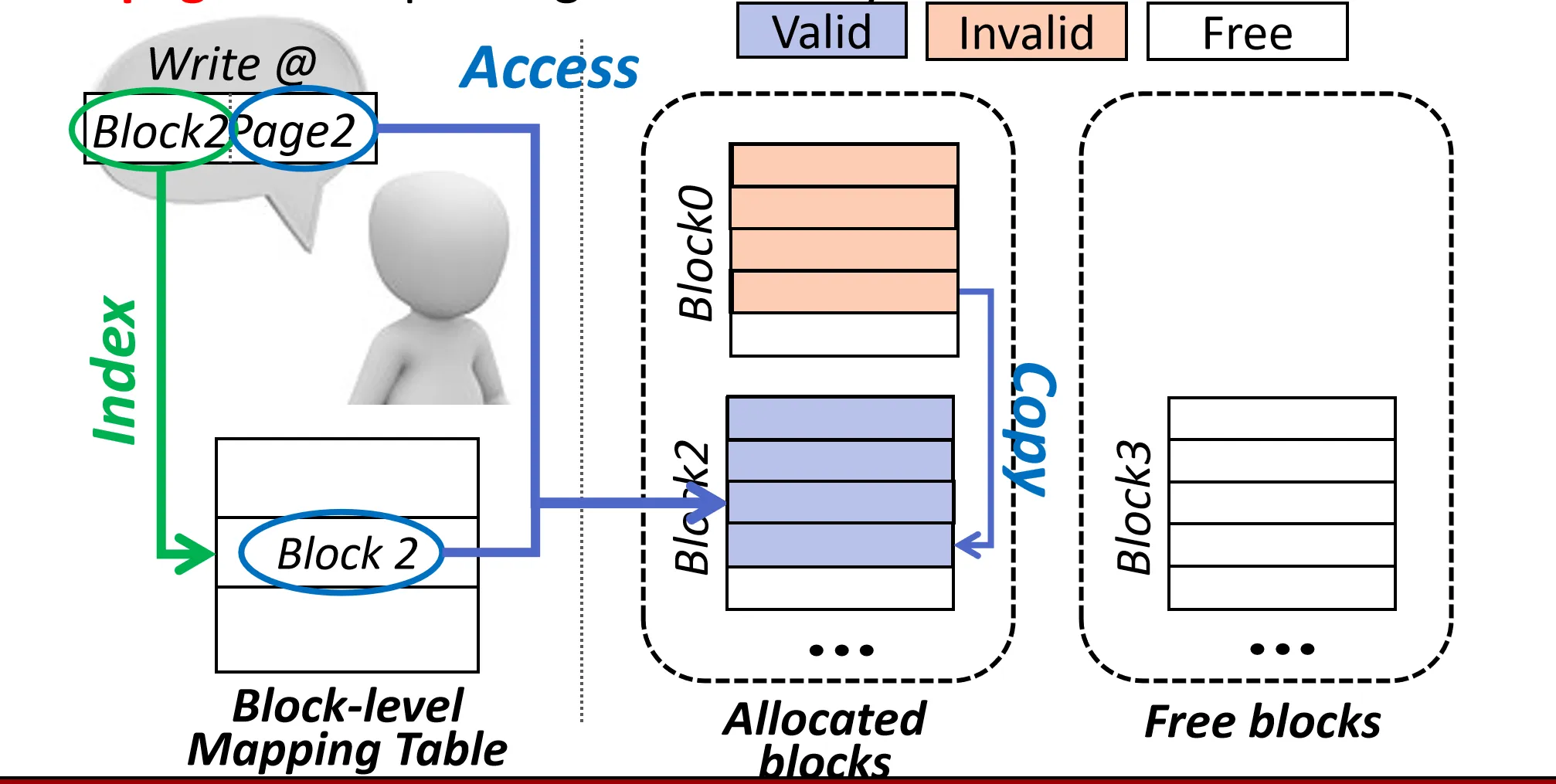
在这之后一定会触发GC, 因为旧 Block 上的 Page 都被 Invalid 了
缺点:
- 写操作的代价太大, 需要拷贝大量的 Page
一个优化方案:
Replacement Block Scheme
如果有更新,不copy 旧Block的有效Page,直接把新数据写到一个Replacement Block上 数据认为是一串Replacement Block + 原Block 组成的链表
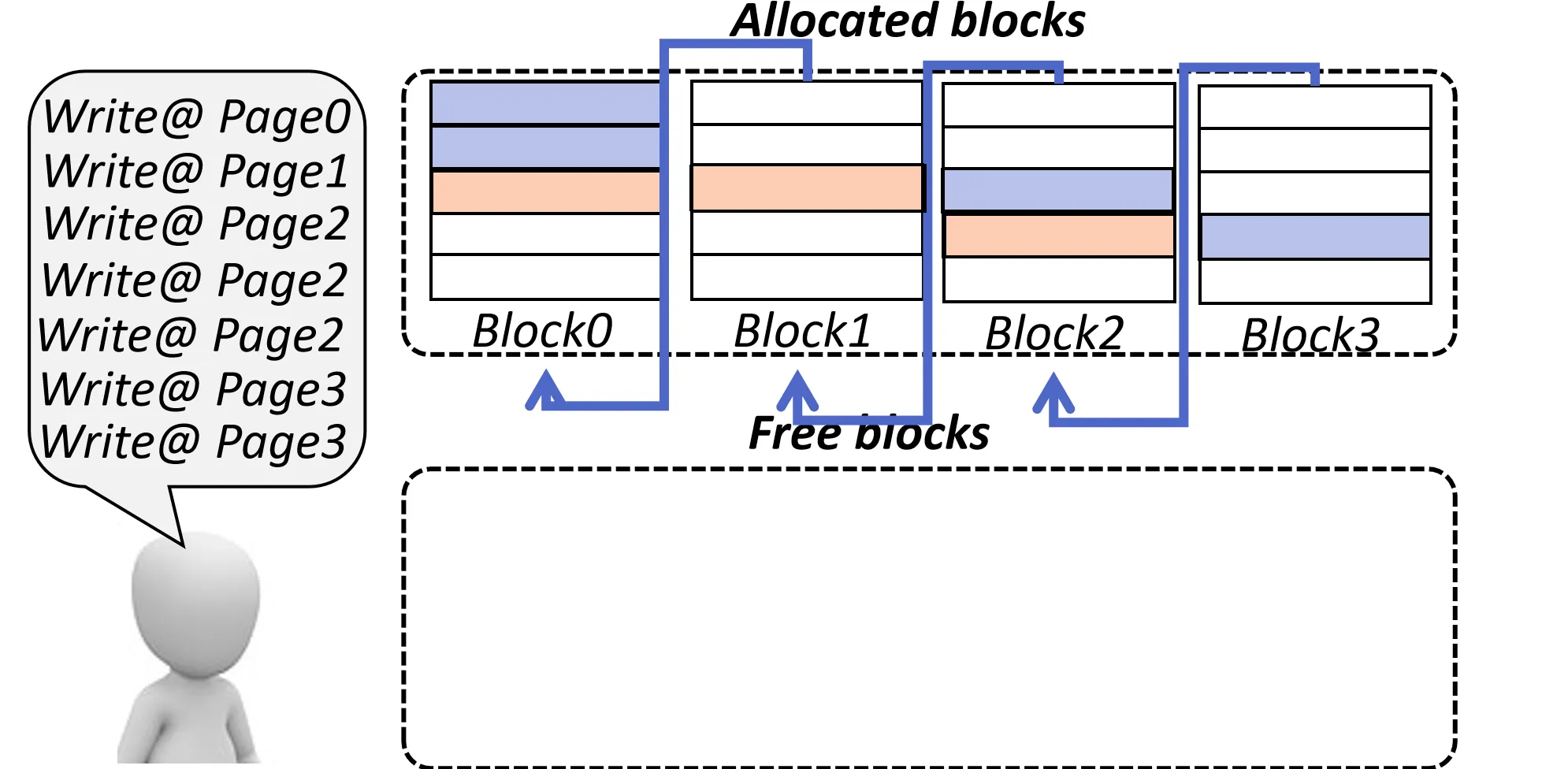
Merge 操作: 当Replacement Block数量超过某个阈值时, 把这些Block的数据合并到 最后一个 Replacement Block(或allocte 一个新 Block)上,释放掉其余的 Block
缺点:
- Block 利用率太低了
- 读写操作需要顺序遍历多个 Block, 延迟较高
- 没有考虑到对同一页数据的多次更新(中间的Replacement Block可能没有数据)
Hybrid Mapping#
Block-level Mapping 和 Page-level Mapping 各有优缺点, 那么我们能不能把两者结合起来呢?
Page-level Mapping 的 Block利用率很高,适合小规模的写操作,但是Mapping Table 太大; Block-level Mapping 的 Mapping Table 小,适合大规模的写操作,但是写代价太大,GC频繁
Hybrid Mapping 结合了两者的优点:
- 对于小规模的写操作, 使用 Page-level Mapping
- 对于大规模的写操作, 使用 Block-level Mapping
Hybrid Mapping 把 Block 分为两类:
- Data Block: 使用 Block-level Mapping,适合用来只读和大规模写入
- Log Block: 使用 Page-level Mapping, 作为小尺寸写入的临时存储区
我们认为大部分块都是 Data Block
第一次写入某个逻辑块时, 直接把数据写入对应的 Data Block 上 如果后续有对该逻辑块的小规模更新, 则把更新的数据写入对应的 Log Block 上
关于 Hybrid Mapping 有很多方案,很多都聚焦于log block的管理(Data Block 怎么分配 log Block)
BAST: Block-level Addressing Sector Translation
一对一映射, 每个 Data Block 分配一个 Log Block
- 如果Log Block 都分完了,有一个没有Log Block 的 Data Block 需要更新, 则需要 选择一个Log Block 作为 victim, 把其数据 Merge 回对应的 Data Block 上, 释放该 Log Block 并分配给该 Data Block
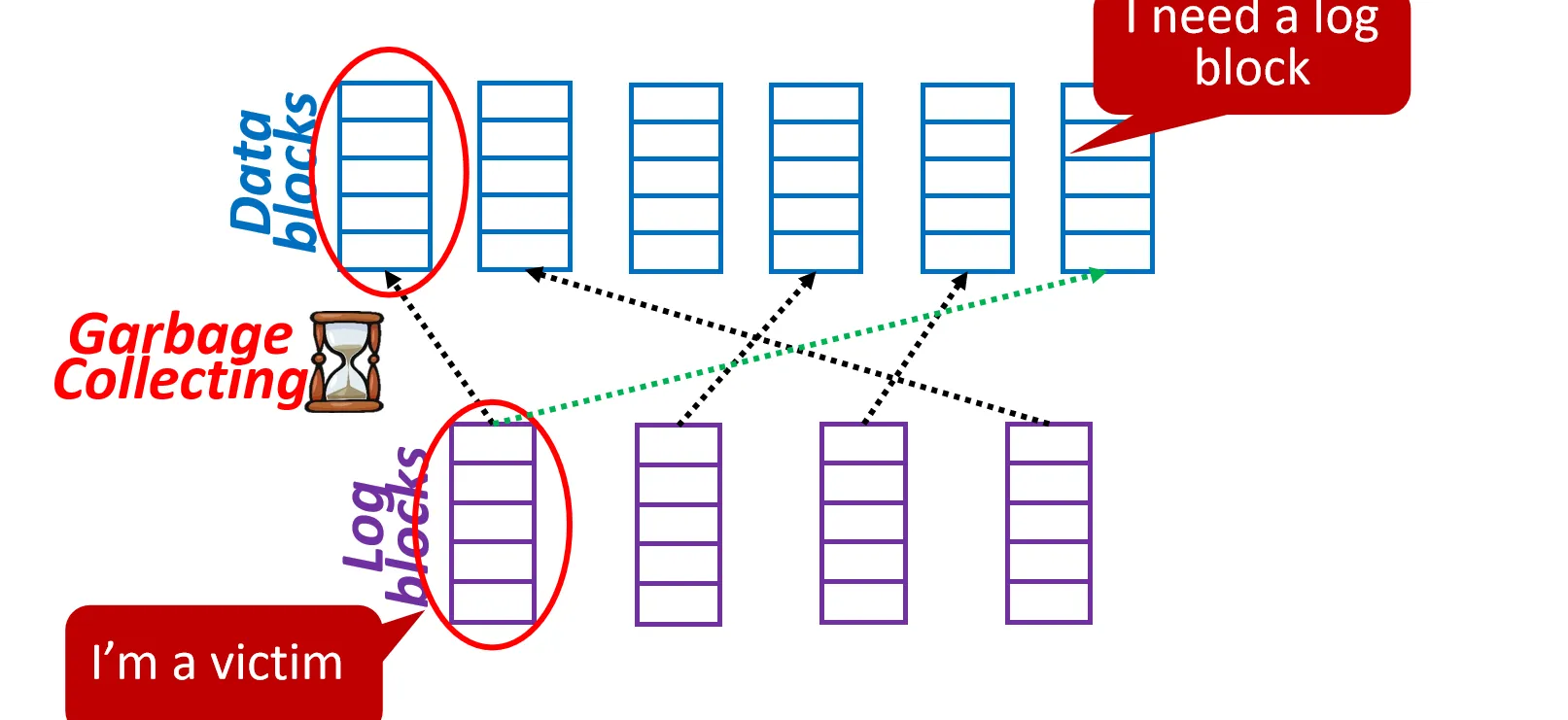
元数据管理会更加复杂:
- Data Block map
- 逻辑 Block 地址(LBN)-> 物理 Data Block 地址(PDBN)
- Log Block map
- 物理 Data Block 地址(PDBN) -> 物理 Log Block 地址(PLBN)
- 逻辑 Page Offset(LPN) -> 物理 Log Page Offset (PPN)
- Block Info Table
- 和Block-level Mapping & Page-level Mapping 一样,保存 Block 级别的元数据
BAST的Merge操作是代价较高的操作,但是BAST经常会对于没有充分利用的Log Block进行Merge (Log Block 不够用),例如Log Thrashing Problem
原因是BAST使用一对一映射, 即一个Log Block 只能对应一个 Data Block
思路:类似Cache一样,做全相联,N对N 映射
FAST: Fully Associative Sector Translation
一个Log Block 可以对应多个 Data Block
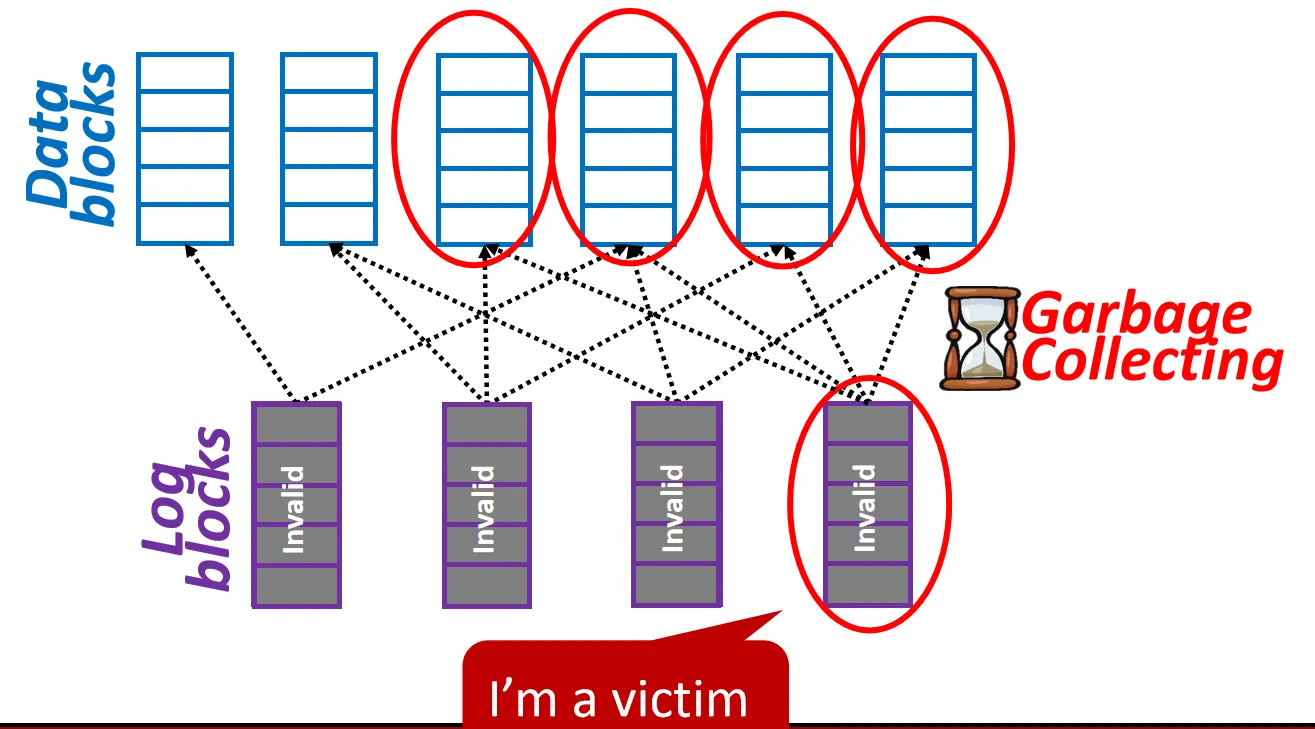
优点:
- 提高 Log Block 的利用率, 减少 Merge 频率
缺点:
- GC时规模变大,需要Log Block对应的所有Data Block 都进行Merge,Data Block 利用率不高
Superblock Scheme
采用N-k映射(cache里面的组相联):N个Data Block 对应 k 个 Log Block,这一个组叫做 Superblock
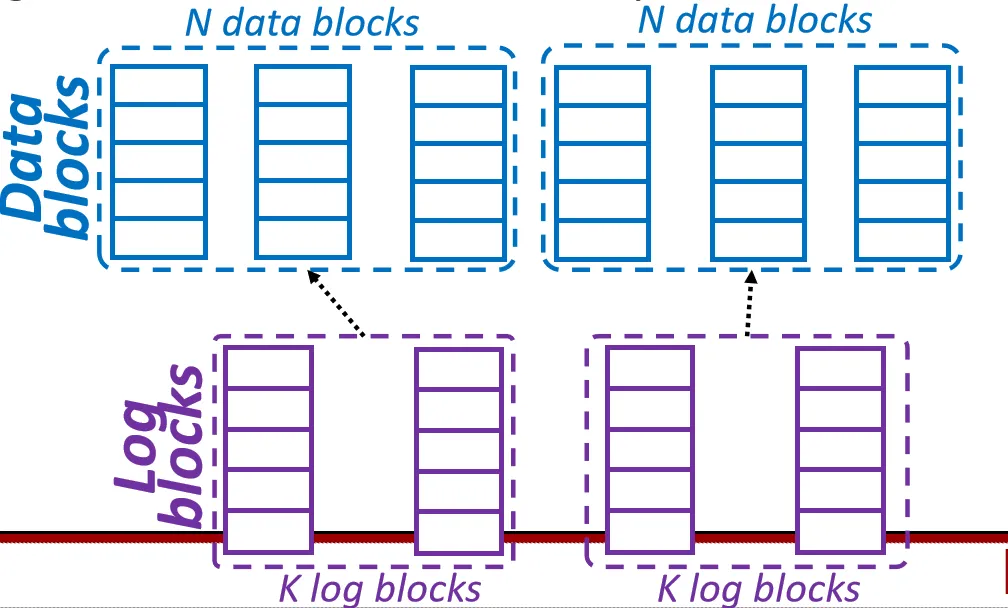
关于SSD还有其他方面的优化,比如访存模式,MLC的支持,Flash可靠性等
Garbage Collection Algorithms#
为什么需要垃圾回收? 因为 Out of Place Update
每次写操作会invalid 旧页, 分配新页,时间长后,必须要通过垃圾回收以确保有充足的新页可用
垃圾回收的基本步骤:
- 选择 victim Block
- 选择合适的 free Block 进行数据迁移 (比如通过Wear Leveling选择)
- 把 victim Block 上的有效页迁移到新的 Block 上
- 擦除 victim Block, 并更新元数据
垃圾回收的开销很大
- GC 期间SSD控制器被占用,用户请求可能被阻塞,Page Copying (页复制) 和 Block Erase (块擦除) 都会带来长延迟 。
- GC 引入了额外的写入操作,导致 Write Amplification (写入放大, WA),缩短了闪存寿命 。
的部分表示额外的写入开销
GC是必不可少的, 那么我们如何优化GC呢?
- 减少GC时迁移的Valid Page 数量
- 垃圾回收调度,什么时候触发GC
- 提高SSD内部的带宽或缩短GC的延迟
- 控制层面的优化,比如GC时出现请求,暂停GC优先处理请求
- Etc.
GC Scheduling#
最简单的方式: 当 free Block 数量低于某个阈值时触发 GC(on-demand GC)
Background GC
在空闲时间段(比如Host没有请求时)进行 GC 操作,减少对用户请求的影响
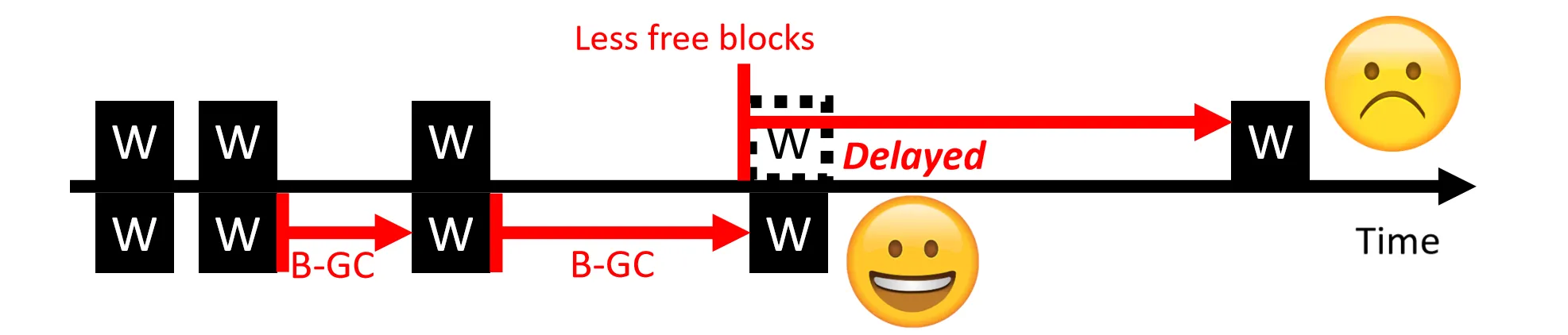
这么做的缺点:
- 空闲时间不好预测 (什么时候会有请求?)
- BGC 时间早于 Demand GC, valid page可能会多于 Demand GC , 导致更多的数据迁移
- BGC 更加频繁, 影响寿命, 且功耗更大
Victim Block Selection#
最直接的方式:选择 valid page 最少的 Block 作为 victim Block (Greedy GC),能最大程度降低 Write Amplification
另一个 naive 的方式: 随机选择 Block 作为 victim Block (Random GC)
这两者相比显然 Greedy GC 的 WA 更低
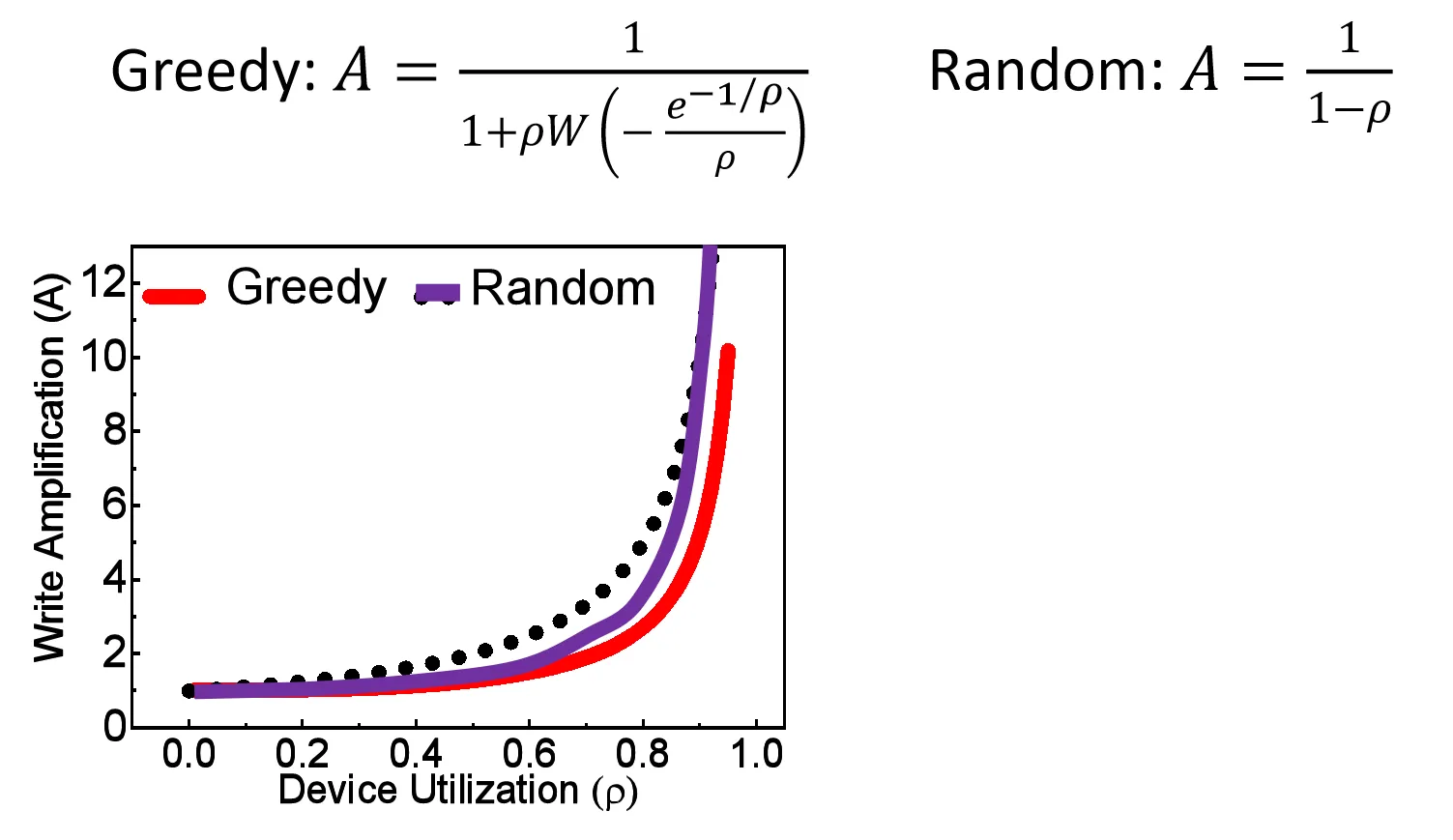
图中的 表示设备利用率 (Device Utilization), 即有效页占总页的比例
但是 GC 时不应该只关注 WA,还要考虑擦除均衡 (Erase Leveling),我们希望 所有 Block 的擦除次数尽可能均匀,避免某些 Block 过早损坏
W越接近1的算法在磨损均衡的视角下越好()
在这种视角下, Random GC 的 W 比 Greedy GC 要好很多
一种折中的方式:
d-Choice, Randomized Greedy Algorithm (RGA)
- 随机选择 d 个 Block, 从中通过Greedy 选择 valid page 最少的作为 victim Block
其他方案以减少 Valid Page count#
TRIM 命令:
- 操作系统通知 SSD 某些逻辑页不再使用, SSD 可以把这些页标记为 Invalid ,从而减少垃圾回收时需要迁移的有效页数量
比如删除某个文件时,文件系统只会删除文件的元数据, 而不会立即擦除文件数据所在的物理页, 这时OS会发送 TRIM 命令给 SSD ,告诉 SSD 这些逻辑页不再使用
随机进行TRIM的收益很小,顺序TRIM的收益较大
TRIM 并不是一个强制性的命令, SSD 可以选择忽略它(比如选择性忽略随机TRIM)
有些SSD对TRIM命令的实现不同
- I-TRIM:只是Mapping Table中标记为Invalid
- E-TRIM:立即擦除对应的物理页,触发垃圾回收
I-TRIM一般性能更好
Over-provisioning (OP, 超额供应)
SSD 预留一部分用户不可访问的物理空间,供给SSD内部使用
- 存储 SSD Firmware
- ECC(Error correction code)
- GC使用 (主要用途)
优点:
- 提高 GC 效率,减少 WA,提高带宽
Conclusion#
GC 三个步骤:
- 选择 victim Block
- 把 victim Block 上的有效页迁移到新的 Block 上
- 擦除 victim Block, 并更新元数据
GC 不仅会降低性能,还会缩短底层闪存的寿命
在各类SSD技术中应用后台垃圾回收面临多重挑战(例如需兼顾使用寿命与空闲状态功耗问题)
降低WA是减轻GC开销的关键,主要可通过以下方式实现:
- Victim Block Selection
- TRIM命令
- Over-provisioning