本文内容基于 2025 秋季《计算机体系结构》双语班课程讲述,如有差错,欢迎指正
Introduction:#
为什么要进行并行计算,一个很简单的理由:为了提高性能
传统上,人写的代码一般都是顺序的,天然适合串行执行:
- CPU: 拥有单个中央处理器
- 程序执行: 程序被分解成一系列离散的指令 ,指令一条接一条地执行
- 时序: 在任何时刻,只有一条指令可以执行
这是在模仿人脑的习惯,于每个时间点执行一条指令。
而并行计算则比较反直觉,同时使用多个计算资源
- CPU: 使用多个处理器(或多个计算核心)
- 程序分解: 程序被分解成可以并发解决的离散部分(子程序)
- 指令执行: 每个部分被进一步分解成一系列指令 ,来自每个部分的指令在不同的计算资源上同时执行
Flynn’s Classification#
根据数据流和指令流的数目,我们对并行进行了大致的分类
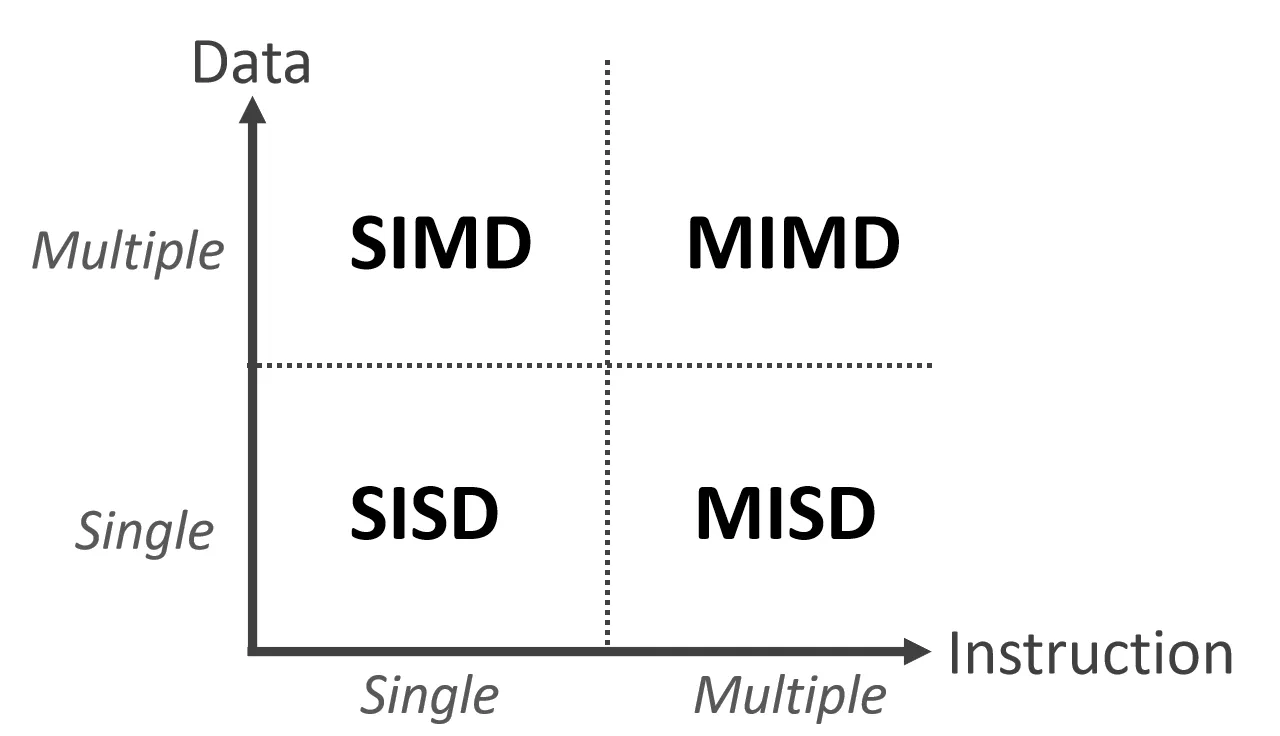
- SISD:处理器每次执行一条指令,这条指令一般处理一条数据
- SuperScaler处理器虽然有多个FU,可以同时执行多条指令,但仍然算是SISD,因为指令来自于同一条指令流
- SIMD:单条指令处理多个数据,如AVX512指令集进行向量化处理,ARM中NEON指令集
- 适合做矩阵运算
- GPU其实也算一种SIMD,自称SIMT(多个线程执行一条指令)
- MISD:多条指令,同时处理一条数据,在极端不可靠场景(如太空)为了避免结果不稳定可能会使用
- MIMD:多条指令流处理多条数据
- 目前最常见的并行计算机类型(大多数现代超级计算机)
那现代CPU到底算是哪种?
- 一个核自然是SISD,如果支持像AVX512这样的指令集那可以是SIMD,多个核组合起来是MIMD
本文重点关注 MIMD 概念,这在如今的超级计算机和多核处理器中非常常见
Mutiprocessor 中的存储结构#
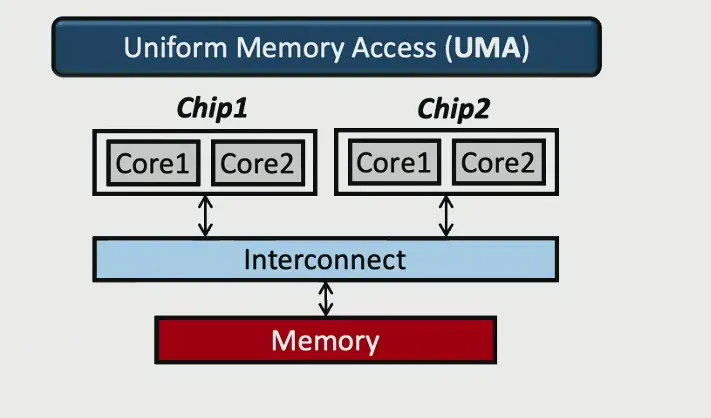
随着核数呈幂律增长,进入多处理器时代 。多处理器中的内存层次结构有不同的访问模型 :
- UMA:最早期的架构,Memeory Controller在CPU外,CPU Core 和 Memory Controller, Memory Controller 和 Memory 之间通过总线相连,访存的延迟相同
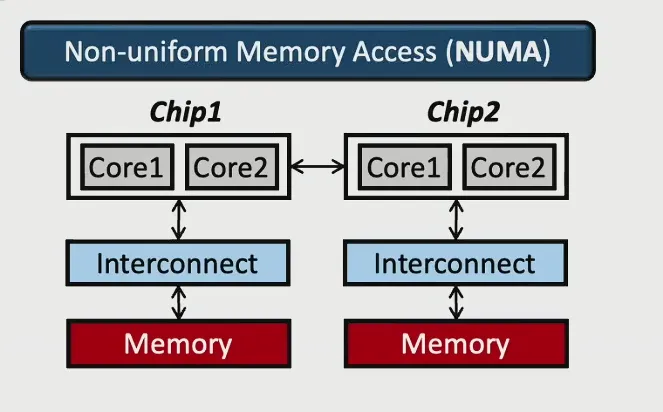
- NUMA:每个 Chip 有自己的 Memory Controller 和自己的内存,但如果访问的数据不在自己的内存中需要进行Chip间通讯访问,导致访存的延迟不同
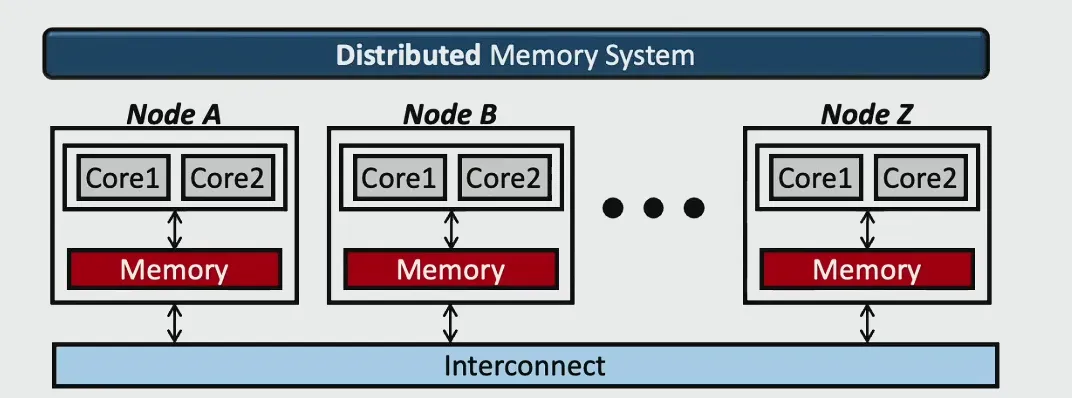
- 分布式内存系统:内存位于本地,通过外侧的网络互联,这种互联会导致延迟差距更大
对于Multiprocessor的影响#
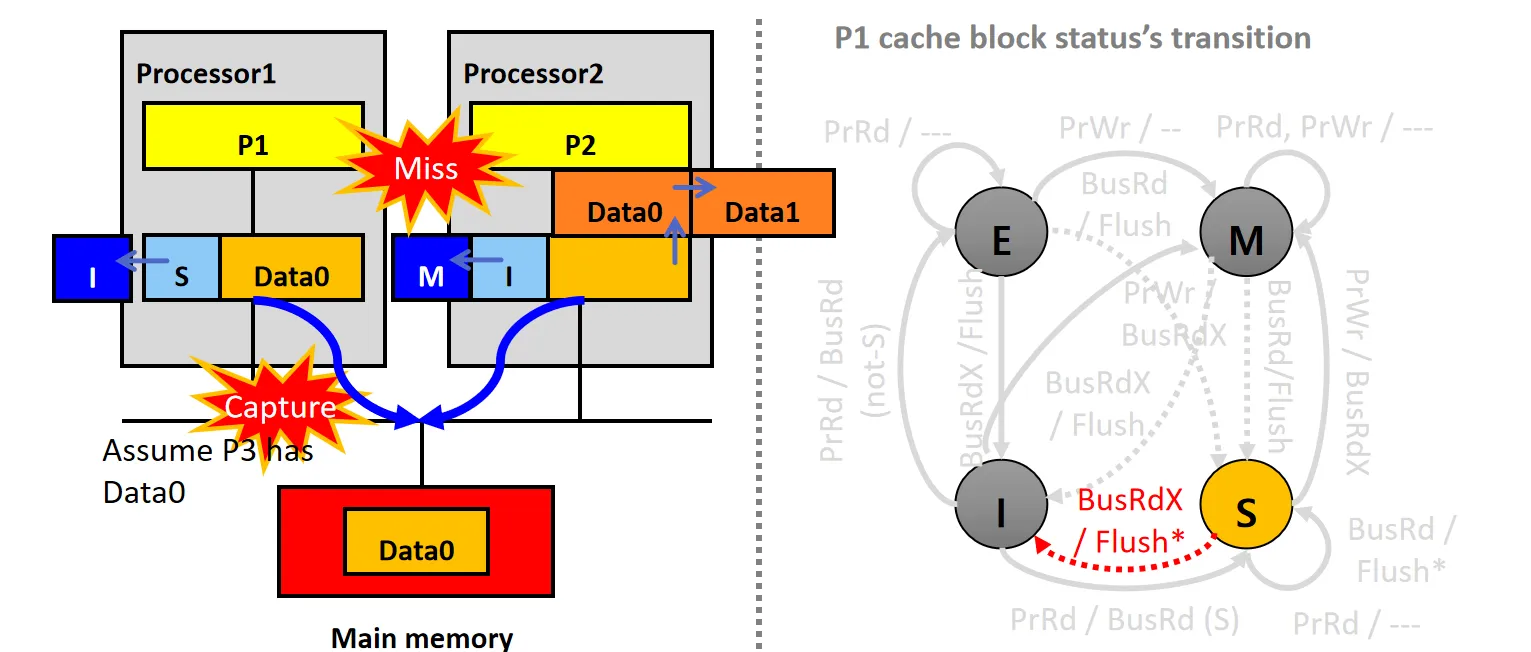
多处理器环境下的主要挑战来自于数据块的“本地副本”(Local copy of data block),即缓存 。这导致了两个核心问题:内存一致性(Memory Consistency)和缓存一致性(Cache Coherence)问题
看下面的例子
- Memory Consistency的问题 : 不同CPU不同内存地址的内存操作的顺序的问题
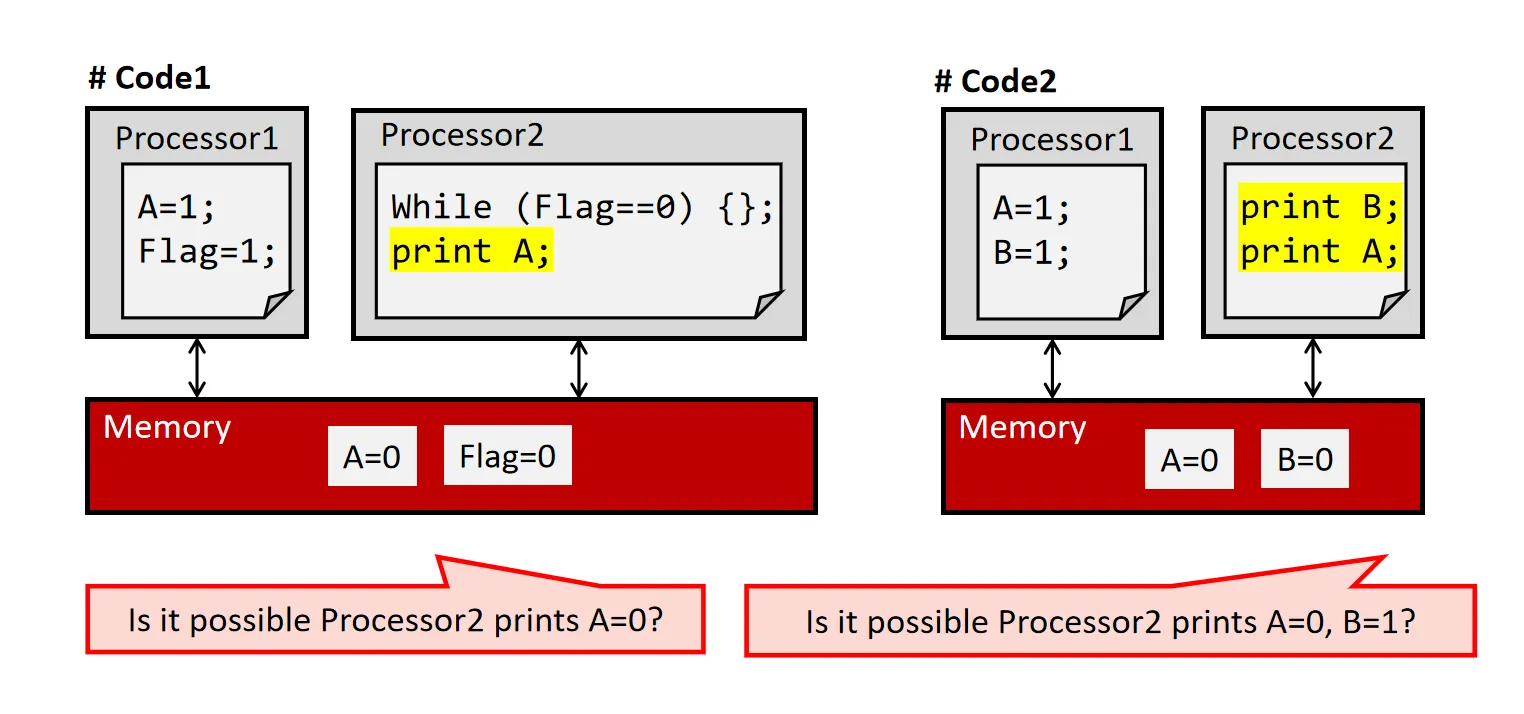
不考虑Cache,对于#Code1 来说,A和Flag的写入内存的顺序不可知,故A = 1可能在Flag = 1之后写入,Processor2可能打印0或1;对于#Code2 来说,两个处理器的执行顺序和写入顺序均不可知,故输出结果有四种可能
- Cache Coherence的问题 : 同一份数据不同Core的Cache副本问题
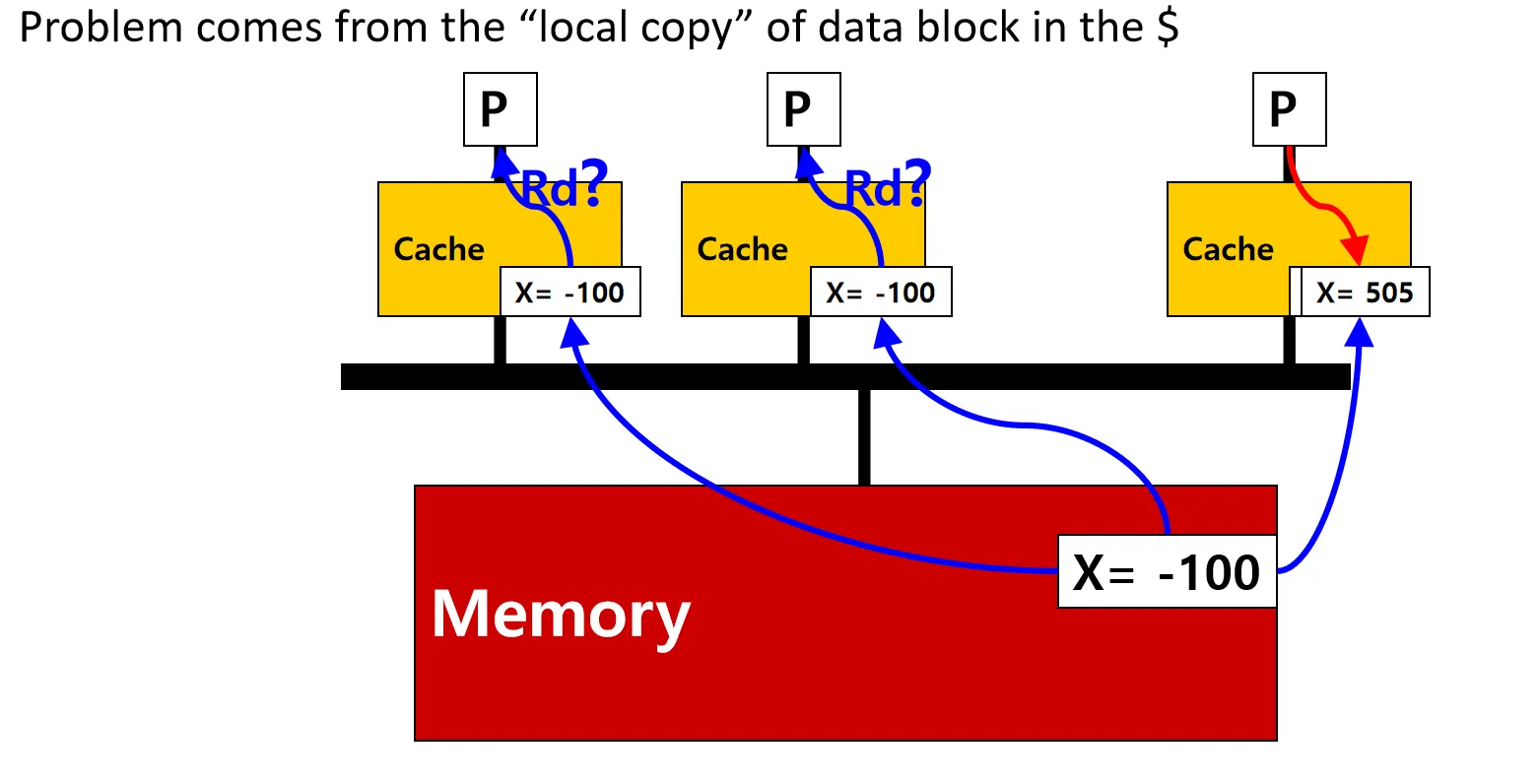
某个Processor更改数据后,其他Processor的Cache上副本可能不一致,其他Processor访问该数据可能会出错
Memory Consistency#
Memory Consistency 主要解决不同CPU不同内存地址的内存操作的顺序的问题
Deffusion 问题#
数据传播的速度未知,导致不同Processor看到的内存状态不一致,操作并不是原子的
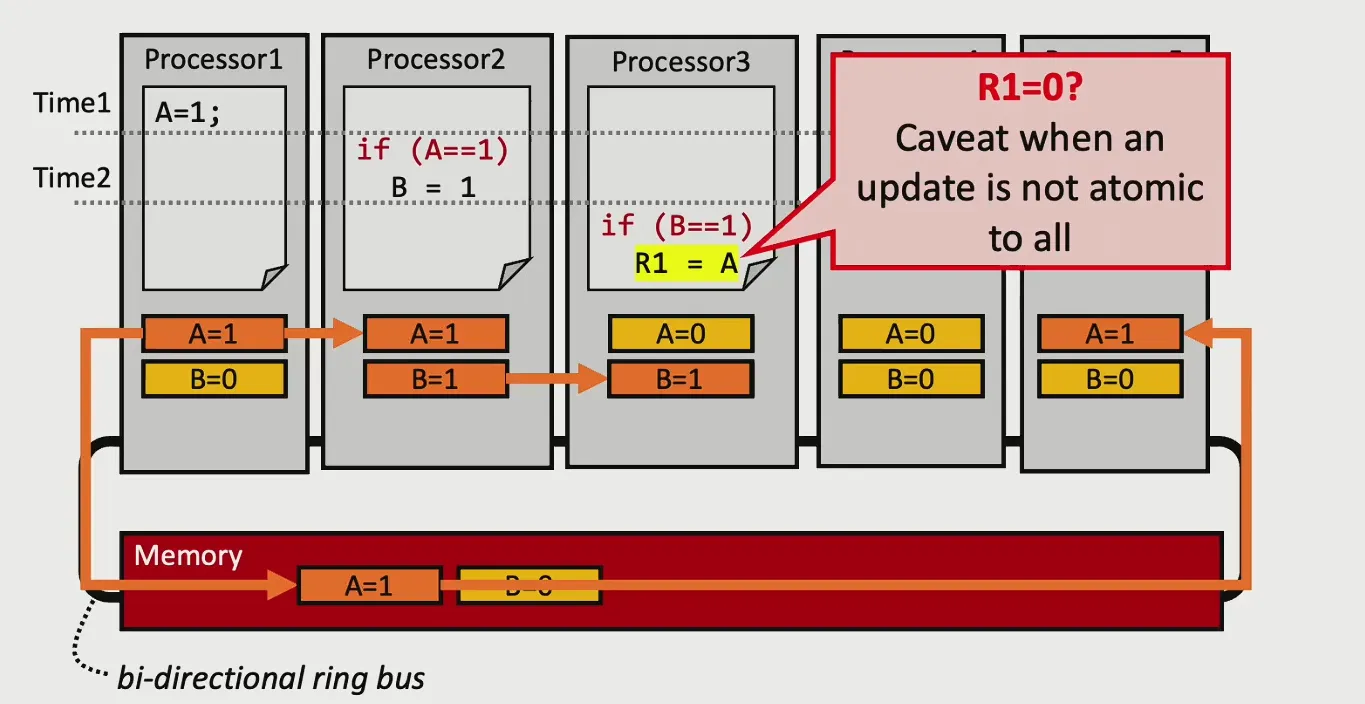
图中所有Processor和内存通过一条Ring Bus相连, B比A先传递到Processor 3,导致 R1的值不是我们想要的
对于这个问题,目前的方法是定义一个规范,硬件按照规范给与支持,软件根据规范写代码
Sequential Consistency (SC)#
按照程序顺序依次发起内存操作(Program Order 和 Memory Order一样)
等效于随机在不同Processor之间进行切换,切到哪个Processor就只执行它的访存指令,其他Processor的访存操作全都Stall
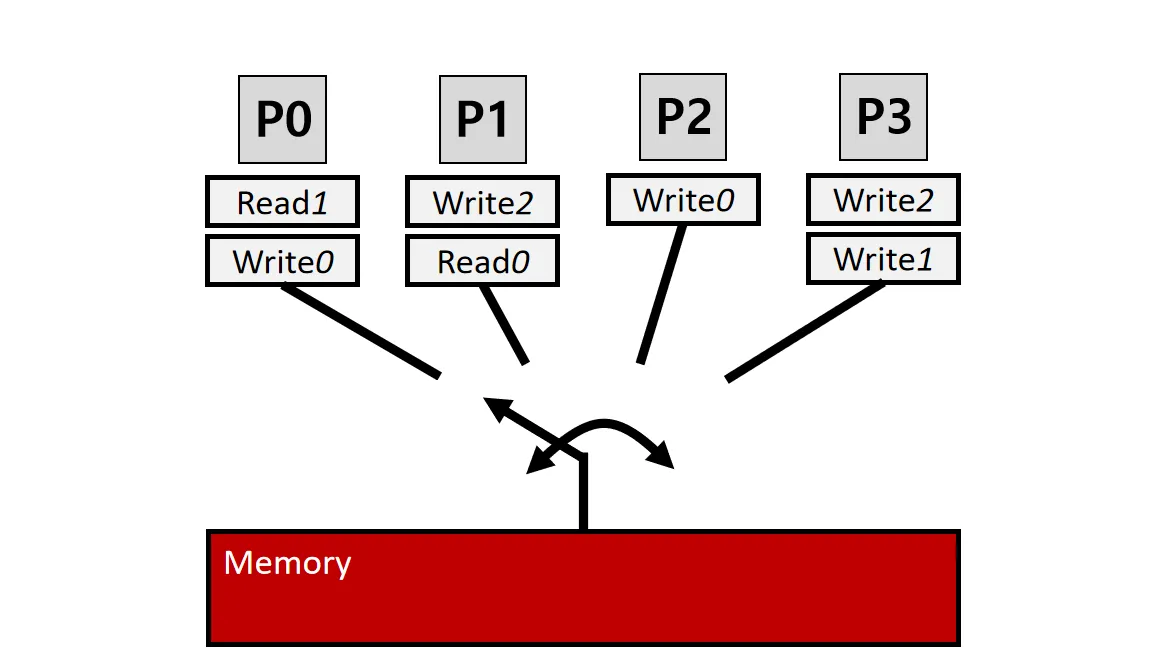
基于这个规则,为保证一致性,处理器的Cache只能是Write through
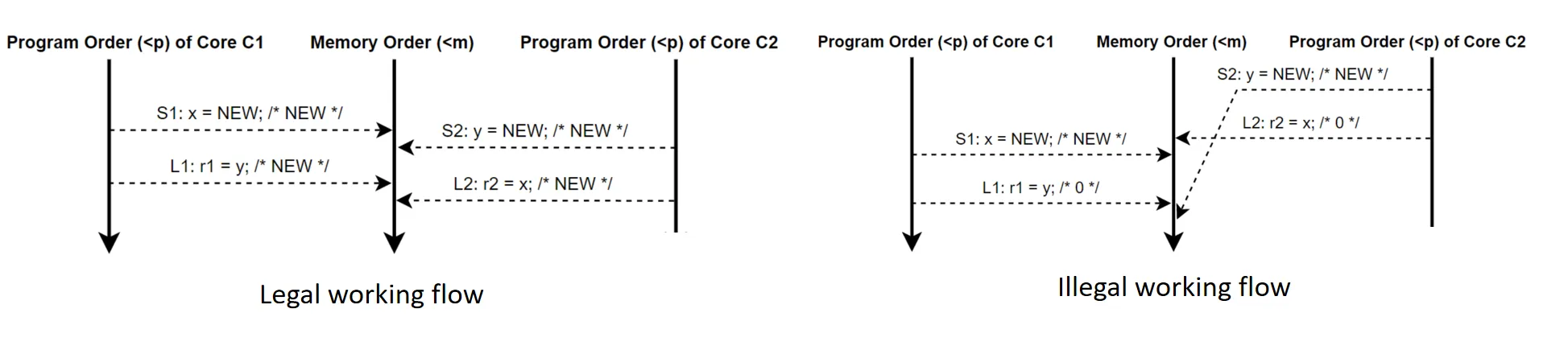
SC保证访存顺序和程序执行顺序一致,但不保证全局程序执行顺序
Total Store Order (TSO)#
只保证Store(写)的顺序和程序顺序一样
对于写操作,不需要直接写到memory上,而是写到一个FIFO的Write Buffer上面(这是之前说过的对Cache的一个优化)
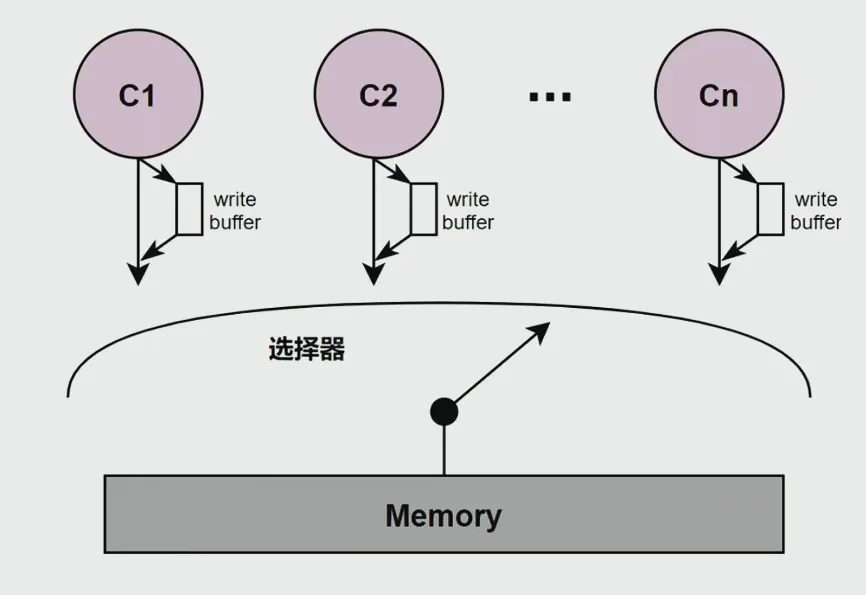
- 与SC的区别:每个Core有一个FIFO的Write Buffer
- TSO的规则:
- 只有写:访存顺序符合程序顺序,Write Buffer FIFO
- 只有读:访存顺序符合程序顺序,直接从Memory读
- 先写后读:不能保证,因为写到Write Buffer中,不能确定什么时候写回Memory
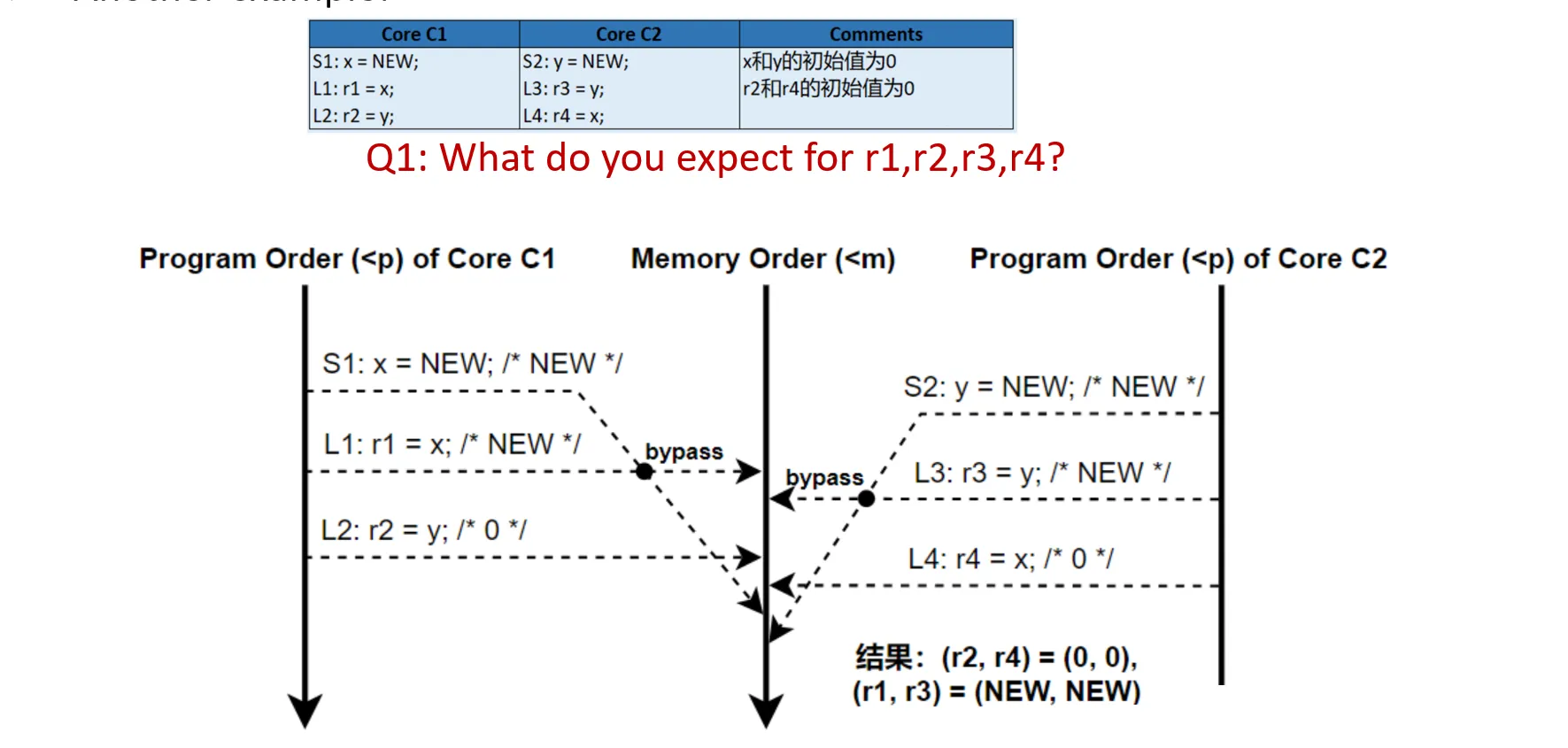
对于上面的例子:r1 == r3 == NEW, 因为会从Write Buffer里面读数据, r2, r4都可能是 0 或NEW
其他更relaxed的规则#
Partial Store Order (PSO)
-
和TSO相似,不过允许对于不同地址的Store顺序改变
-
对应于Write back的Cache
Relaxed Memory Order (RMO)
-
允许 Load->Store、Store->Store、Load->Load、Store->Load 顺序改变
-
需要程序员用一些指令(比如fence)来规范顺序
Weak Consistency (WC)
- 内存仅在同步操作时保持一致,在 barrier 之间操作可以自由重排
Summary#
这种规范是硬件设计者和程序员之间的trade off,规则越Relaxed,硬件性能越好(一些放松的规则可以应用一些硬件的优化),但编程越困难
Cache Coherence#
Cache Coherence 主要解决同一份数据不同Core的Cache副本问题
关键思想:追踪每个Cache上数据块的状态,以保持全局更新同步
新增硬件:
- “bus snooper”,用于监控总线上的数据传输
- cache line 状态寄存器,记录每个cache line的状态
Write through 的规则#
Write through: 当处理器更新本地副本时,同时更新主内存
在这个条件下,处理Cache Coherence问题相对简单
snooper的做法:如果其他处理器更新的数据块存在于本地缓存中,则将其变为invalid
- 原则上也可以将该数据更新到本地,但有可能该数据不会被使用
cache line的状态只有两种:valid 和 invalid
当处理器读取数据时,snooper会检查数据块的状态:
- 如果数据块是valid,则直接从本地缓存读取
- 如果数据块是invalid,则从主内存读取,并将其更新到本地缓存
Write back 的规则#
Write back: 当处理器更新本地副本时,不立即更新主内存,而是将其标记为dirty
snooper需要让其他处理器知道该数据块已被更新
MESI#
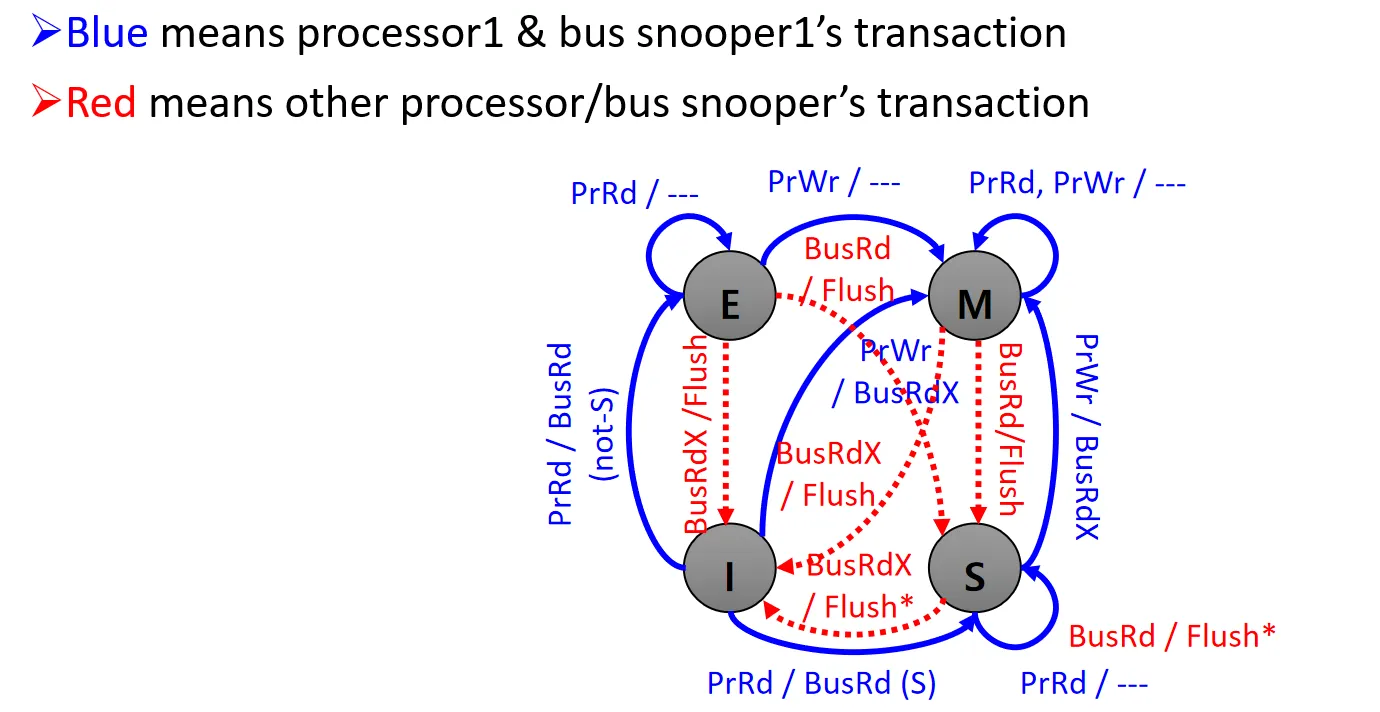
MESI Protocol 是最经典的缓存一致性协议,它定义了每个cache line有四种状态:
- Modified(M):数据块已被修改,内容与内存不同
- Exclusive(E):独有的副本,内容与内存相同
- Shared(S):非独有副本,与其他处理器共享
- Invalid(I):数据已被其他处理器更新
MESI 中定义了一些操作,这些操作会触发状态转换:
- 处理器自身发起的操作: PrRd / PrWr (读/写)
- 三种通过bus感知到的操作:
- BusRd: 其他processor进行读操作,发生cache miss
- BusRdX: 其他processor进行写操作,需要先从其他地方把数据读过来,再进行写(其他processor需要invalid自己的副本)
- BusWB: 其他processor将数据写回内存
- 两种snooper操作:
- Flush: 把数据放到总线上,供其他processor使用
- Flush*: 把数据放到总线上,同时告知有相同副本的processor不需要再Flush
下面我们逐步拆解,看状态转换图:
下述情景假设有两个processor P1,P2,我们只关注P1
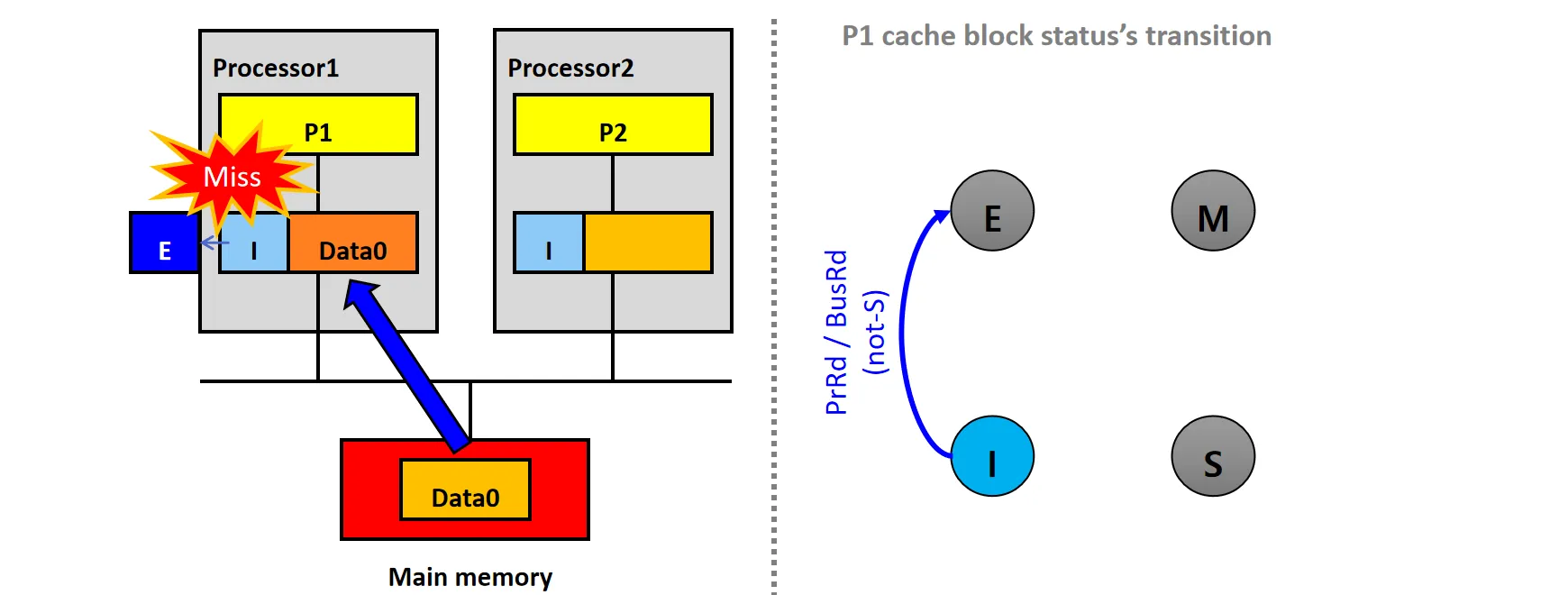
情景1:Cold Miss(not-S)
设P1和P2的Cache Line都为I状态
- P1和P2的Cache都没有数据块X,P1发起PrRd请求,发生Cold Miss
- P1的snooper发送BusRd请求,从内存读取数据Data0,数据块状态从I变为E
如何判断应该设为E状态?
- 因为P1的snooper没有接受到其他processor的Cache对数据Data0的响应,只接受到Memory的响应
- Cache的响应应该比Memory更快
情景2: Reads Local Copy(E)
设P1的Cache Line状态为E
- P1发起PrRd请求,从本地Cache读取数据Data0
- 数据块状态不变,仍为E
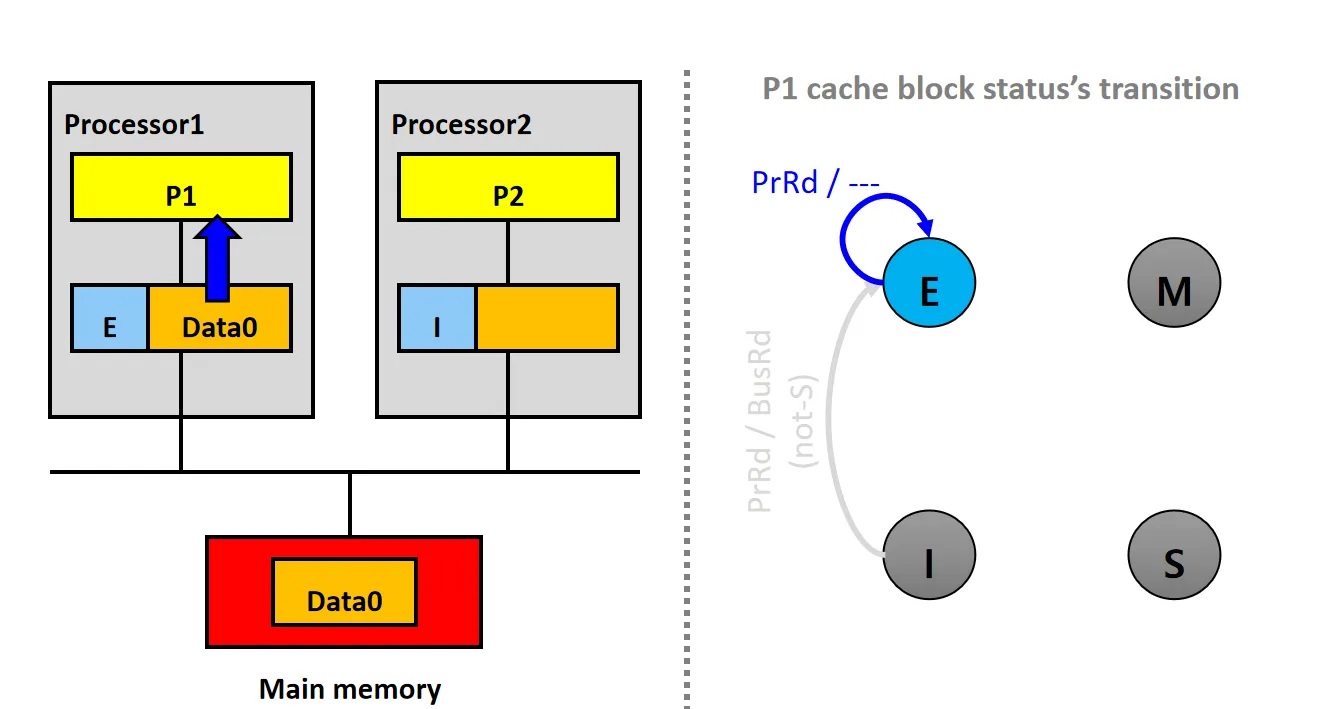
情景3:Updates Local Copy(E)
设P1的Cache Line状态为E
- P1发起PrWr请求,修改本地Cache上的数据Data0
- 数据块状态从E变为M
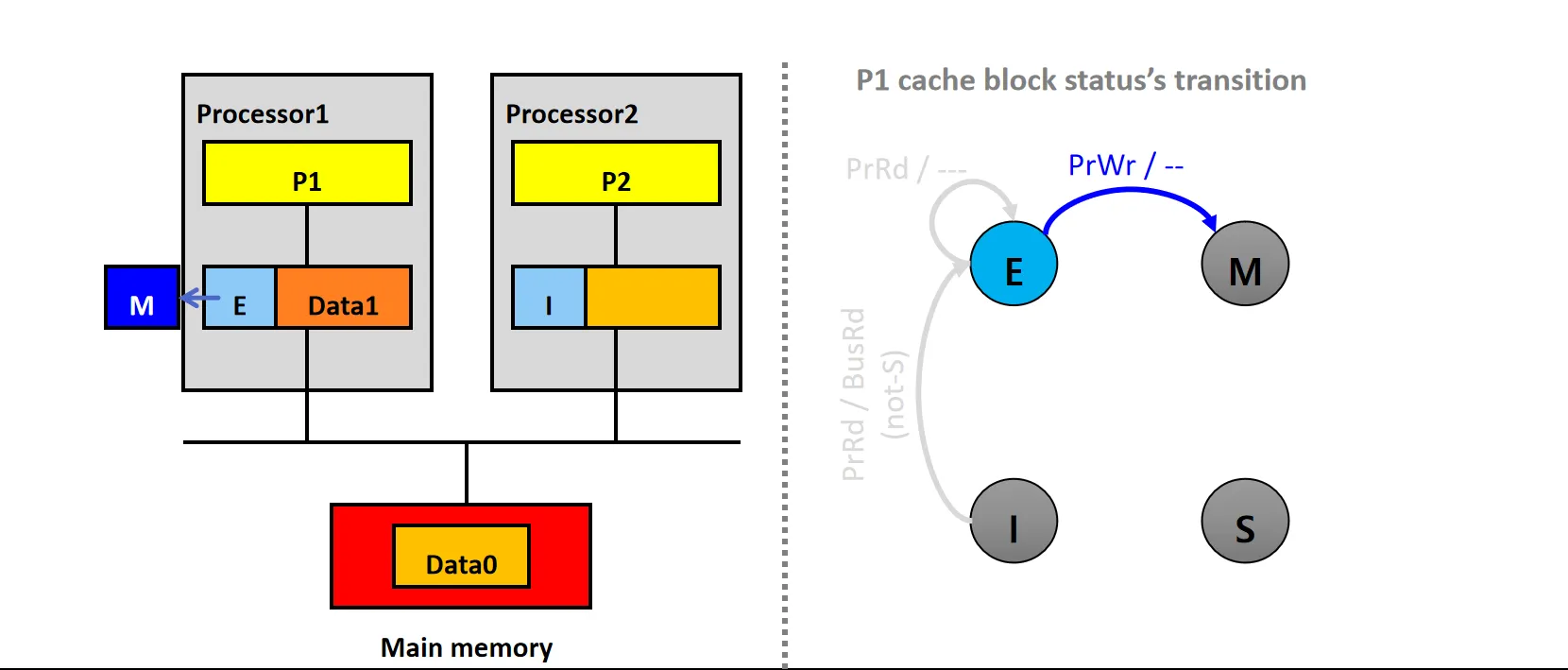
情景4:Local Copy (M)
设P1的Cache Line状态为M
- P1发起PrWr/PrRd请求,修改/读本地Cache上的数据Data1
- 数据块状态不变,仍为M
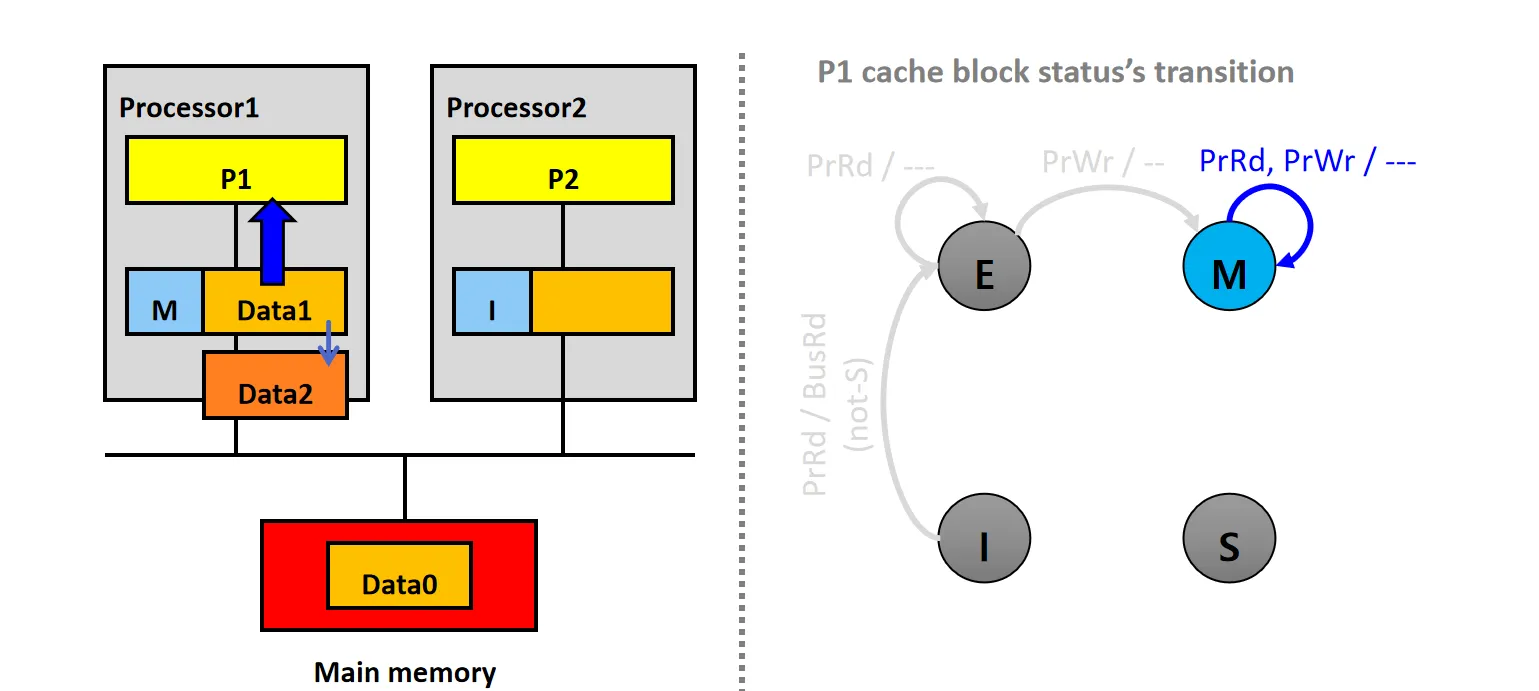
情景5:Write Miss
设P2有状态为E的本地副本,P1的Cache Line状态为I
- P1发起PrWr请求,发生Write Miss,但P2有数据
- P1的snooper发送BusRdX请求,P2的snooper接收到请求
- P2的snooper将数据Data0通过Flush放到总线上,同时将自己的Cache行状态从E变为I
- P1从总线读取数据Data0,更新本地Cache,修改数据为Data1,并将状态设为M
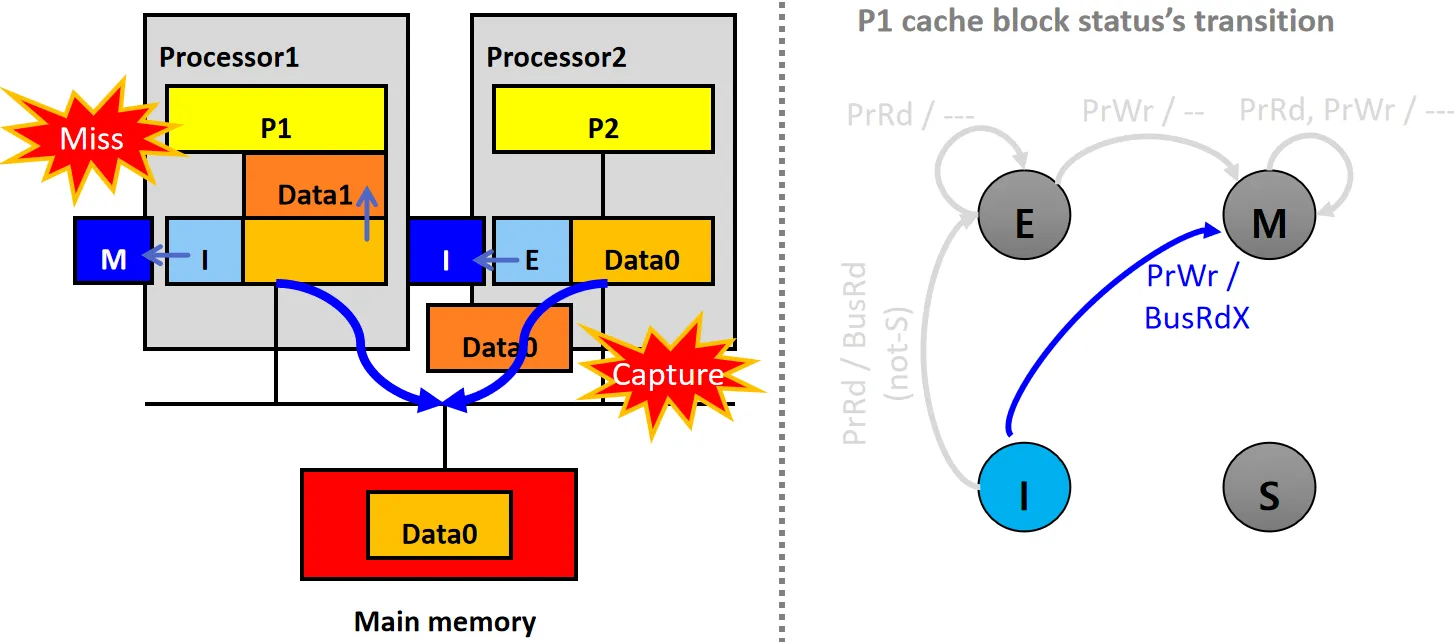
情景6:Cold Miss(S)
设P2有状态为E的本地副本,P1的Cache Line状态为I
- P1发起PrRd请求,发生Cold Miss,但P2有数据
- P1的snooper发送BusRd请求,P2的snooper接收到请求
- P2的snooper将数据Data0通过Flush放到总线上,同时将自己的Cache行状态从E变为S
- P1从总线读取数据Data0,更新本地Cache,并将状态设为S
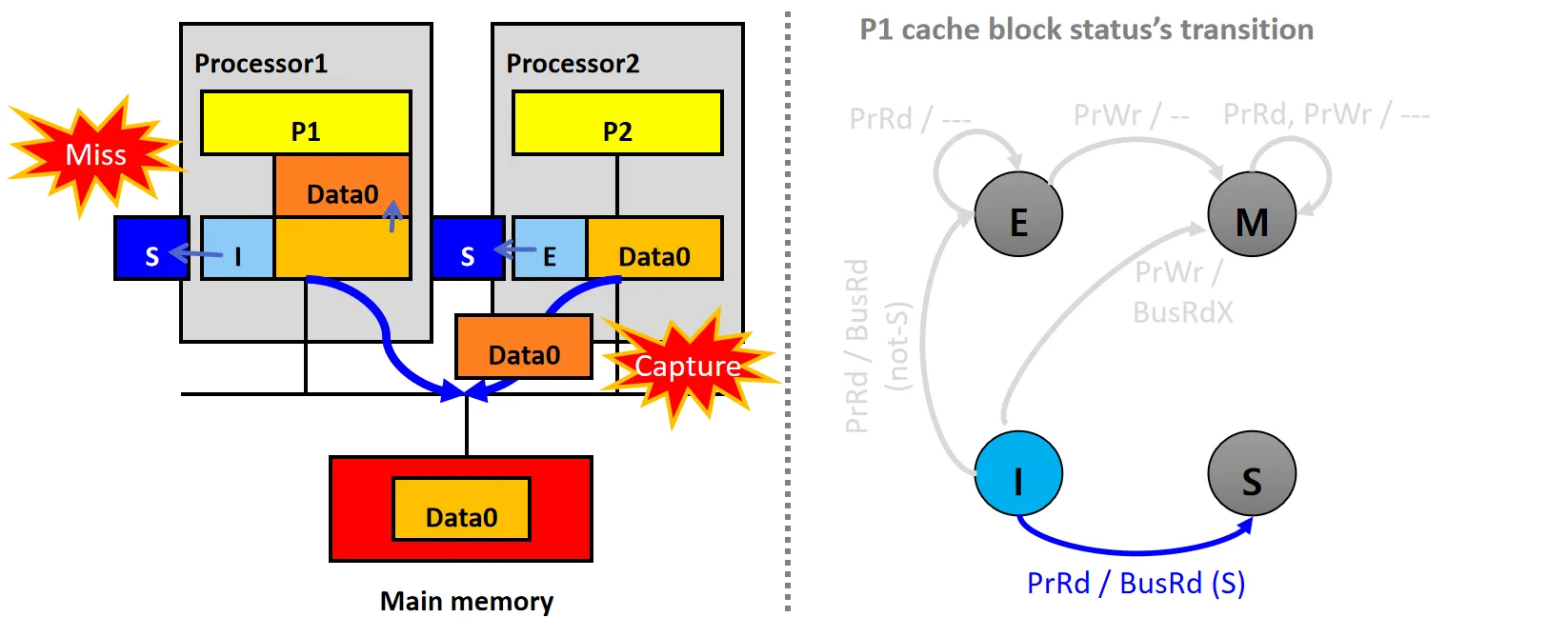
情景7:Reads Shared Copy
设P1和P2的Cache Line状态均为S
- P1发起PrRd请求,从本地Cache读取数据Data0
- 数据块状态不变,仍为S
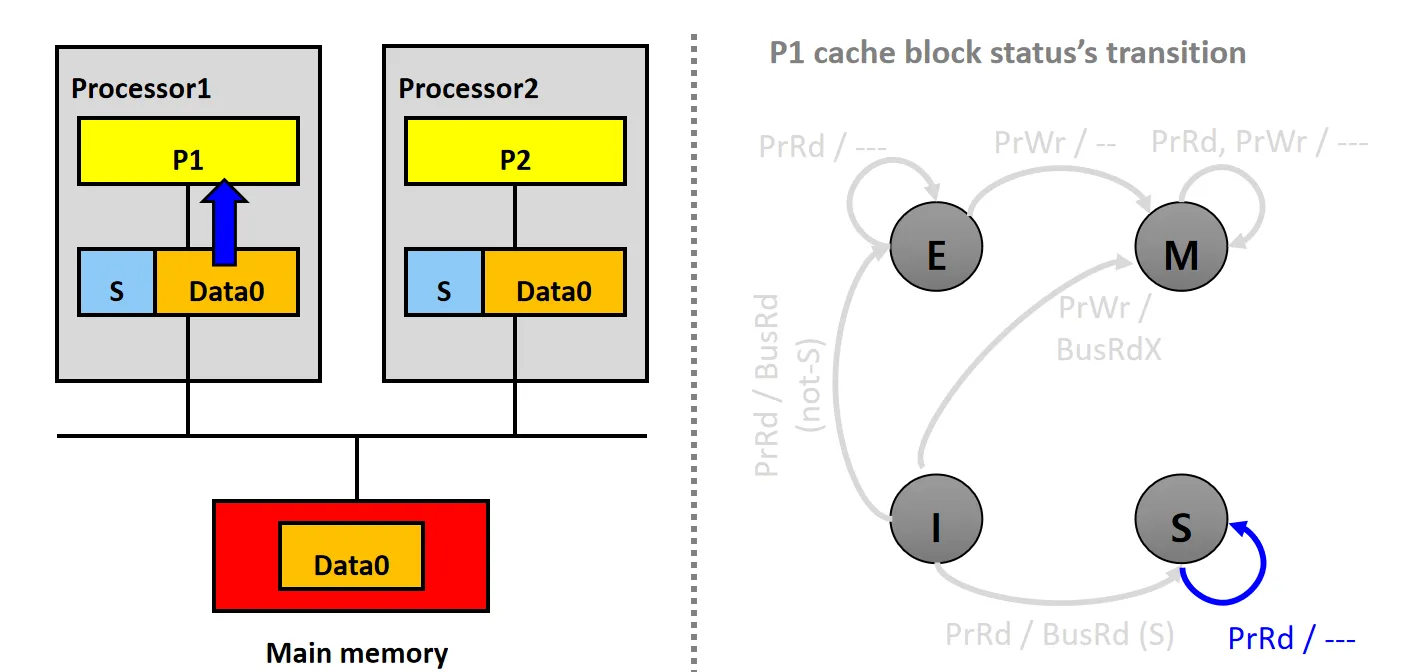
情景8:Updates Shared Copy
设P1和P2的Cache Line状态均为S
- P1发起PrWr请求,修改本地Cache上的数据Data0
- P1的snooper发送BusRdX请求,P2的snooper接收到请求后,将自己的数据块状态从S变为I
- P1将数据块的状态设为M
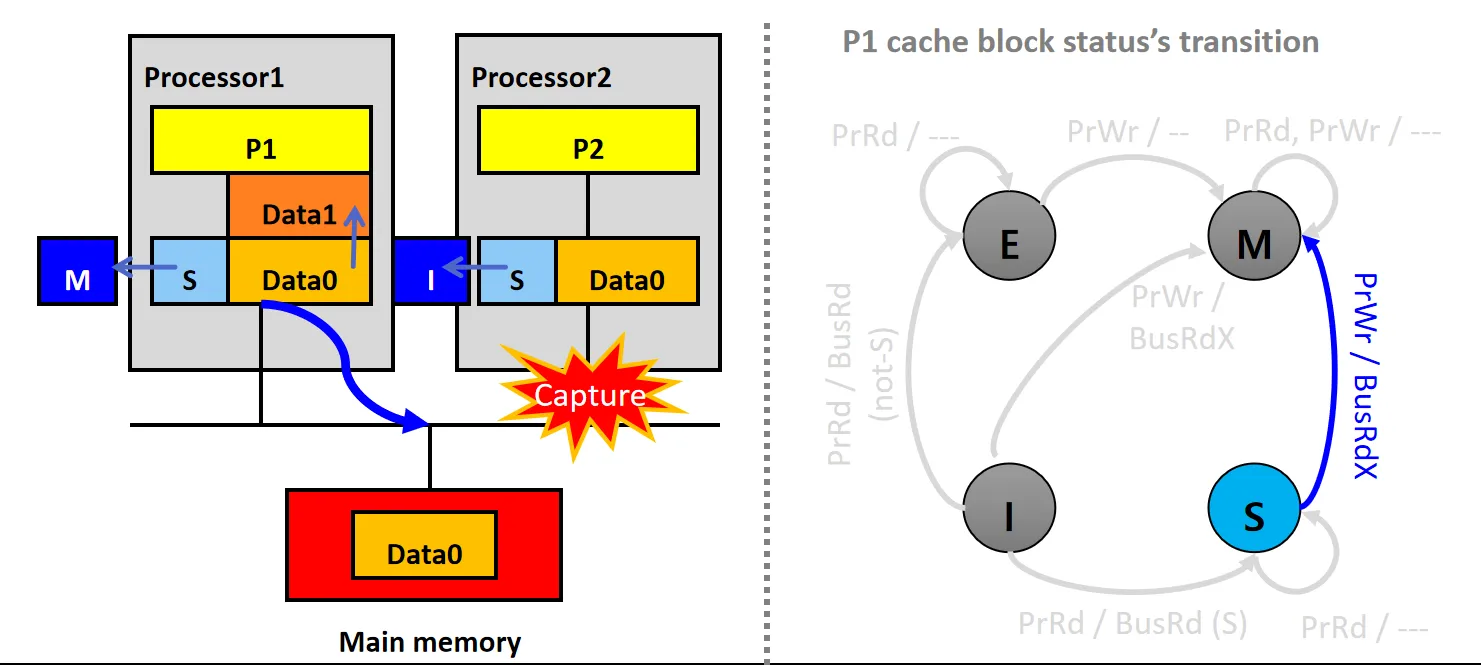
情景9:Capture BusRd (S)
设P1的Cache Line状态为S,P2的Cache Line 状态为I
- P2尝试读数据,但发生Cache Miss,P2的snooper发起BusRd请求
- P1的snooper接收到请求后,将数据Data0通过Flush放到总线上
- P1数据块状态不变,仍为S,P2从总线读取数据Data0,更新本地Cache,并将状态设为S
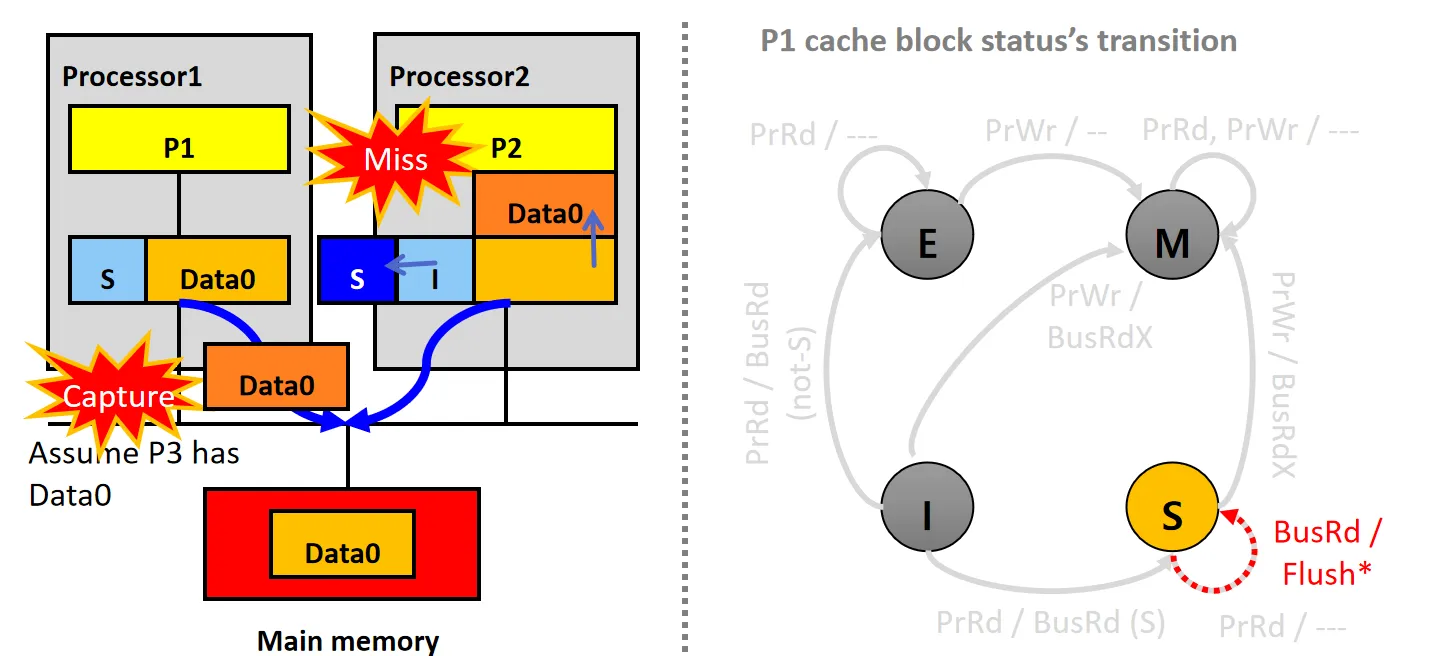
情景10:Capture BusRd (E)
设P1的Cache Line状态为E,P2的Cache Line 状态为I
- P2尝试读数据,但发生Cache Miss,P2的snooper发起BusRd请求
- P1的snooper接收到请求后,将数据Data0通过Flush放到总线上
- P1数据块状态从E变为S,P2从总线读取数据Data0,更新本地Cache,并将状态设为S
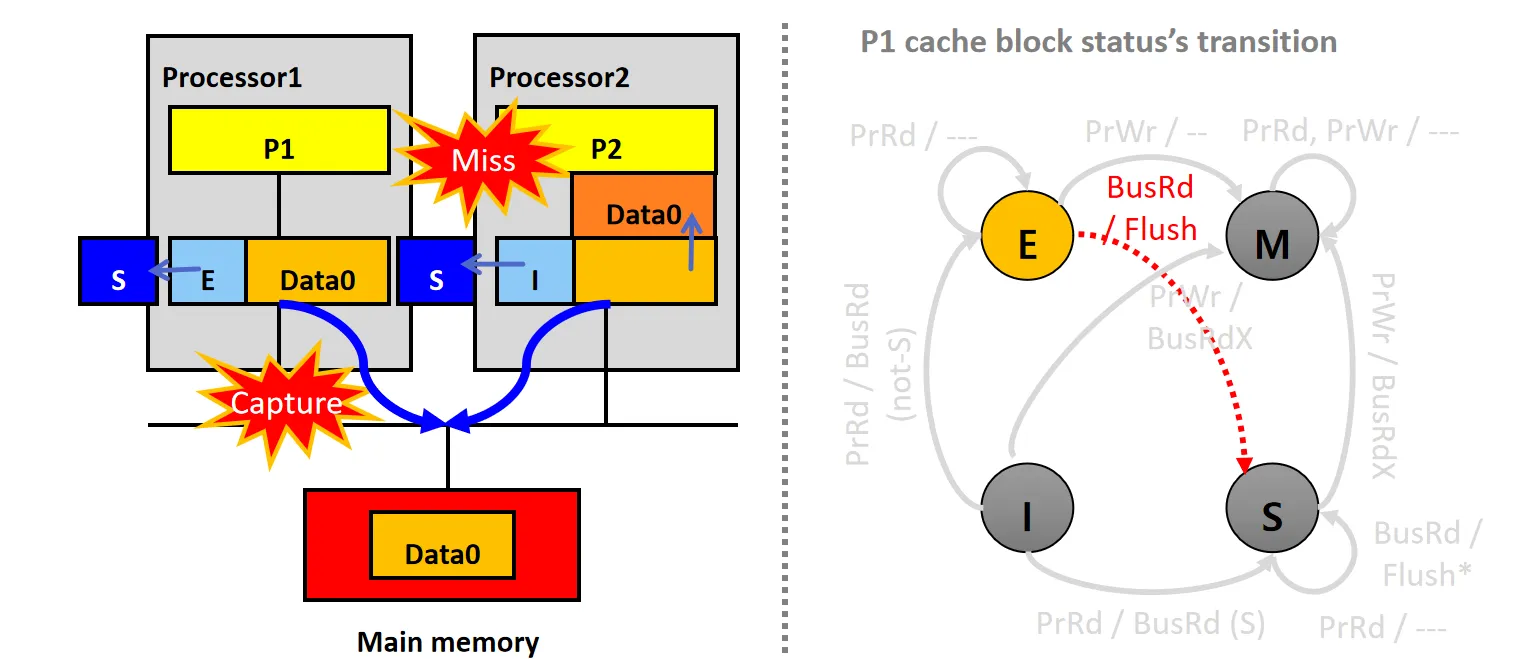
情景11: Capture BusRd (M)
设 P1的Cache Line状态为M,P2的Cache Line 状态为I
- P2尝试读数据,但发生Cache Miss,P2的snooper发起BusRd请求
- P1的snooper接收到请求后,将数据Data1通过Flush放到总线上
- P1数据块状态从M变为S,P2从总线读取数据Data1,更新本地Cache,并将状态设为S
- 内存更新为Data1
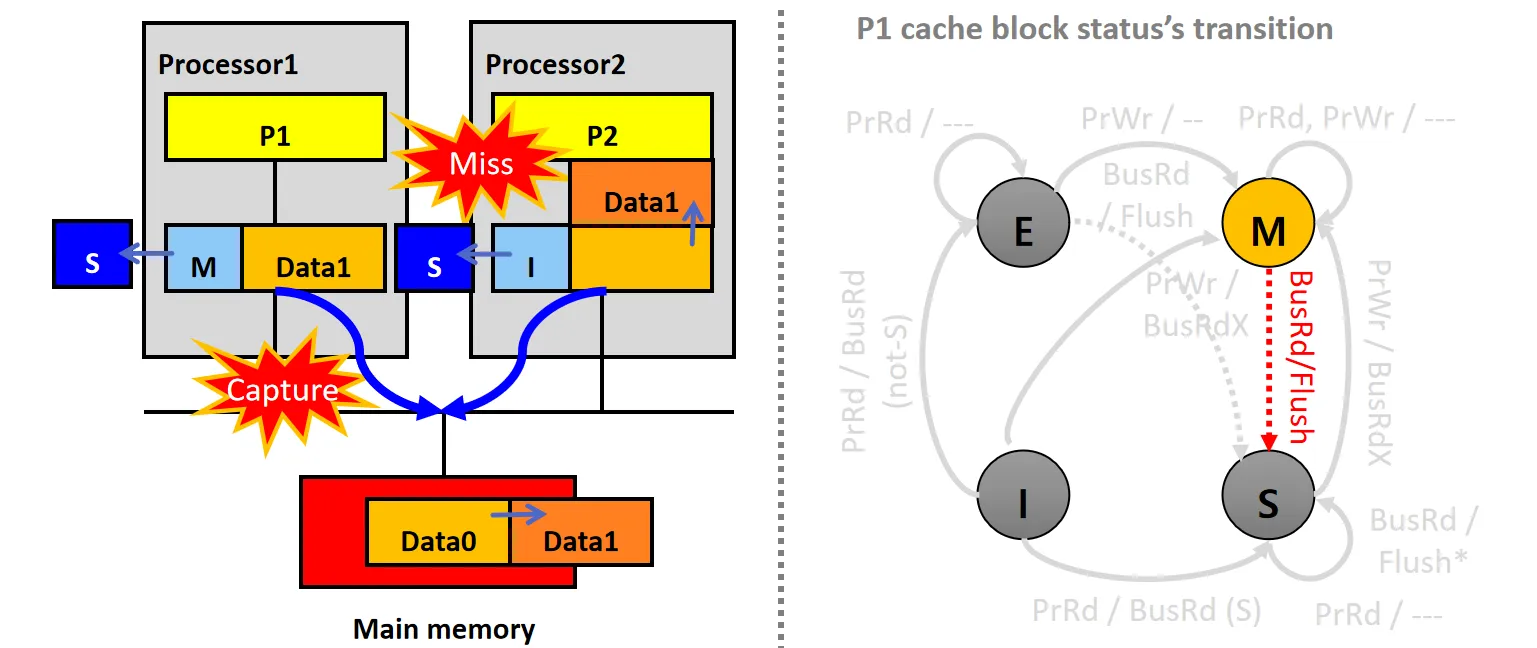
情景12:Capture BusRdX (E)
设P1的Cache Line状态为E,P2的Cache Line 状态为I
- P2尝试写数据,但发生Cache Miss,P2的snooper发起BusRdX请求
- P1的snooper接收到请求后,将数据Data0通过Flush放到总线上,同时将自己的Cache行状态从E变为I
- P2从总线/内存读取数据Data0,更新本地Cache,修改数据为Data1,并将状态设为M
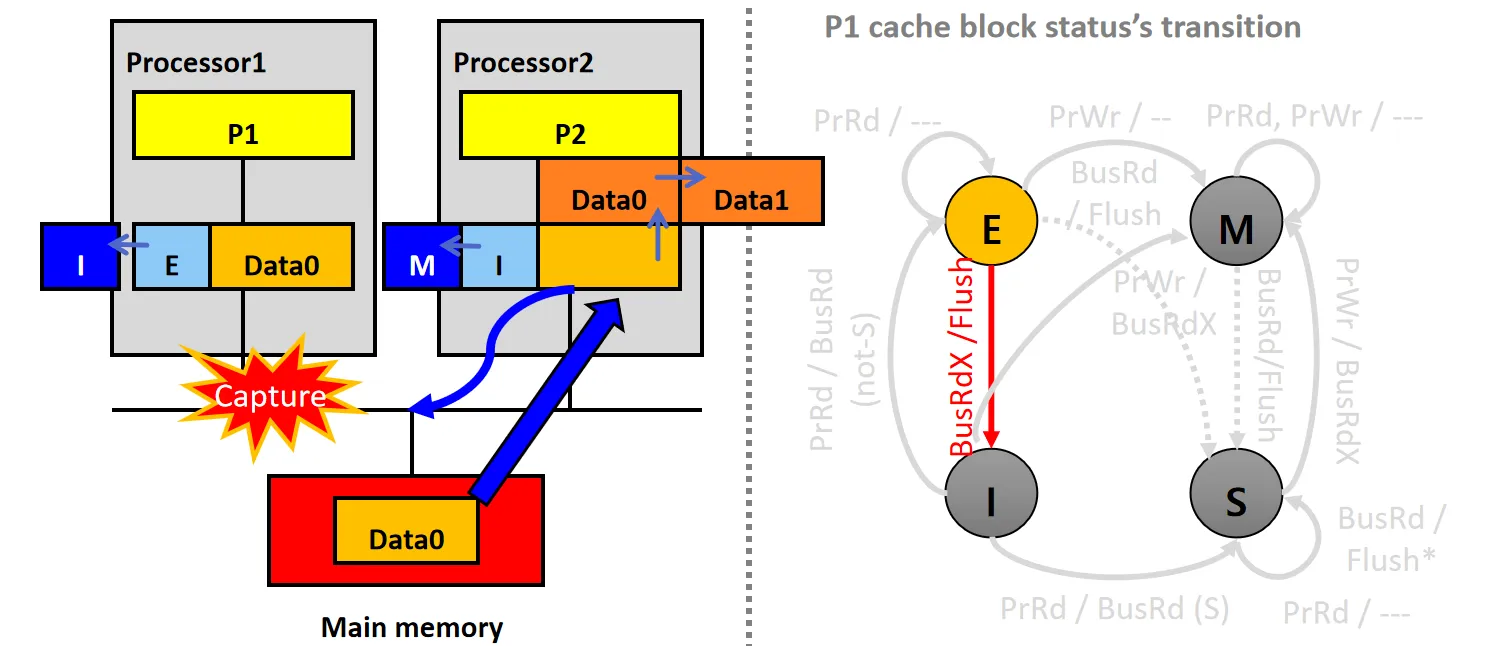
情景13:Capture BusRdX (M)
设P1的Cache Line状态为M,P2的Cache Line 状态为I
- P2尝试写数据,但发生Cache Miss,P2的snooper发起BusRdX请求
- P1的snooper接收到请求后,将数据Data1通过Flush放到总线上,同时将自己的Cache行状态从M变为I
- P2从总线读取数据Data1,更新本地Cache,修改数据为Data2,并将状态设为M
- 内存更新为Data1
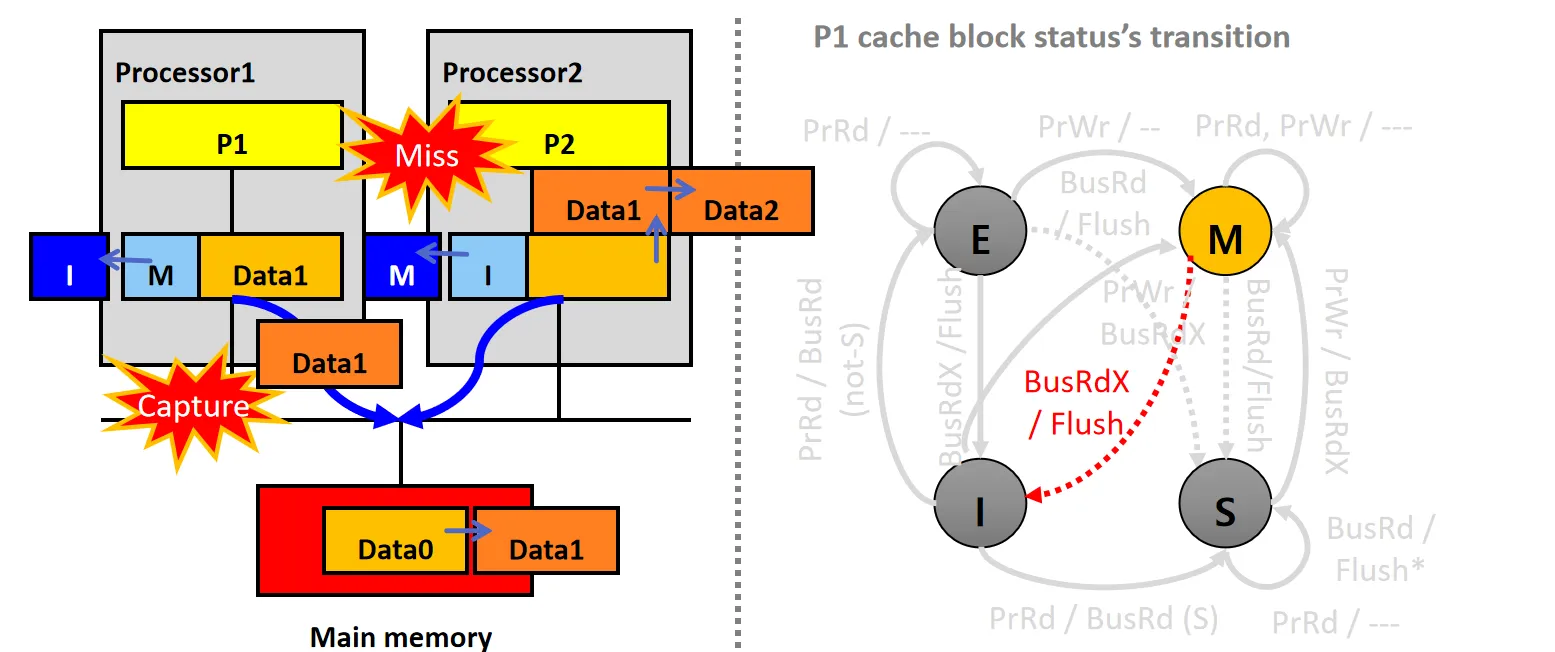
情景14:Capture BusRdX (S)
设P1的Cache Line状态为S,P2的Cache Line状态为I
- P2尝试写数据,但发生Cache Miss,P2的snooper发起BusRdX请求
- P1的snooper接收到请求后,将数据Data0通过Flush*放到总线上,同时将自己的Cache行状态从S变为I
- P2从总线读取数据Data0,更新本地Cache,修改数据为Data1,并将状态设为M
最终的MESI状态转换图如下:
Other Protocols#
除了MESI,还有其他一些缓存一致性协议:
- MEI:没有S状态,当数据被多个处理器共享时,直接invalidate 其他处理器上的副本
- Cache上只能有一份副本,容易导致乒乓现象
- MSI:RISCV使用的一致性协议
- 如果只有一个副本,MSI位于S状态,发生写时,需要发起BusRdX请求,额外占用带宽
- MESI只需要把E改为M即可
- MOESI:AMD的处理器使用该协议
- 增加了O(Owned)状态,O表示该数据块是脏的,与内存不一致,且共享的
- 当P1上数据是M状态,P2想要读数据时,MESI需要把数据写回内存
- 而MOESI不更新内存,直接将数据提供给P2,并把自身M状态改为O,P2状态改为为S
- 这样可以减少内存访问次数,提高性能(因为AMD的内存做的不好,笑)
- MESIF:Intel的处理器使用该协议
- 增加了F(Forward)状态,F表示该数据块是共享的,但负责将数据提供给其他处理器
- 当P1上数据是S状态,P2想要读数据时,MESI需要广播BusRd请求,所有拥有该数据块的处理器都需要响应
- 而MESIF只需要让F状态的处理器响应请求,获得数据的处理器改为F状态,发送数据的处理器(F)改为S状态
- 减少了总线上的响应数量,提高性能
多层 Cache Coherence#
Naive 的方法:每一层 Cache 都实现 snooper
Intel 的方法:snoop filter
- 因为高级的Cache(L1 Cache)是低级Cache(L2 Cache)的子集,把L2 作为snoop filter
- 有snoop请求到来时,L2替L1检查是否要响应。
- L1必须是Write through
一些Q&A#
Q:Flush*和MESIF有啥区别?
A:MESIF明确了F状态的Cache行负责响应请求,(猜测)而Flush*可能需要某个S告诉其他Cache它不需要响应
Q:如何确定是cache还是memory服务请求?
A:传统的MSI是memory服务请求,MESI优先尝试让cache服务请求
Q:E state的processor为何还要flush data to memory?
A:(没找到具体解释,个人猜测)MESI继承了MSI的设计,同时M和E states比较接近,所以沿用了flush。Memory controller在侦听到flush之后,会进一步判断是否需要进行memory update操作。
Directory Based Coherence#
snooper的缺点:
- 对于大型系统,snooper需要监视来自每个处理器的总线流量,导致总线带宽瓶颈
- 在总线上广播会有信号衰减,限制了系统的可扩展性
一种解决思路:
- 把Cache line的状态信息存储在一个集中式的Directory中
- Directory跟踪每个Cache上数据块的状态,以保持全局更新同步
- 通过查询Directory来确定数据块的位置
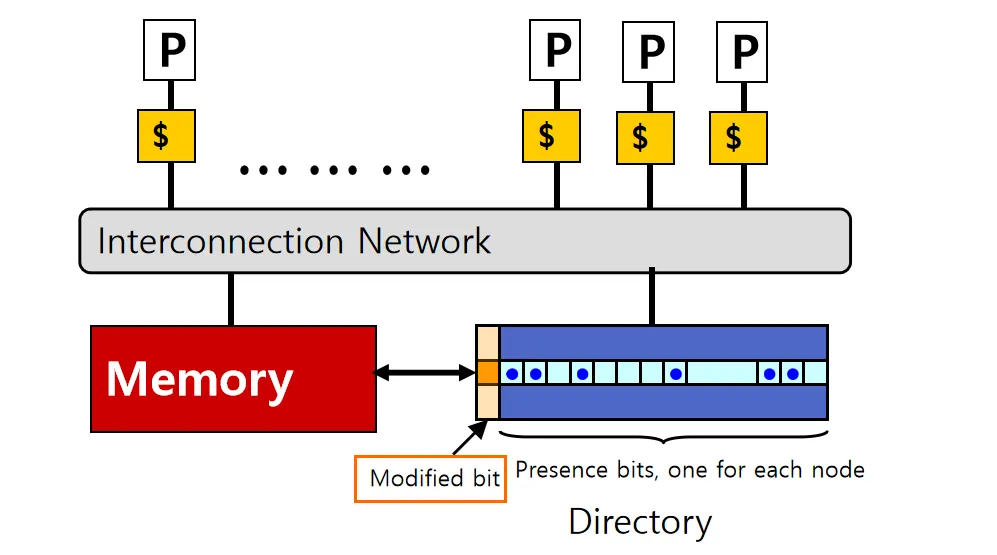
但是,集中式的Directory需要被所有Core访问,可能会成为瓶颈
一种改进思路:分布式Directory(这不就转化成了Directory Coherence了吗啊喂)
分布式Directory#
Directory只负责记录本地memory副本的状态
- 访问数据时一定要知道数据在哪个Home Node(memory&processor)上,可能是通过某种哈希或其他方式
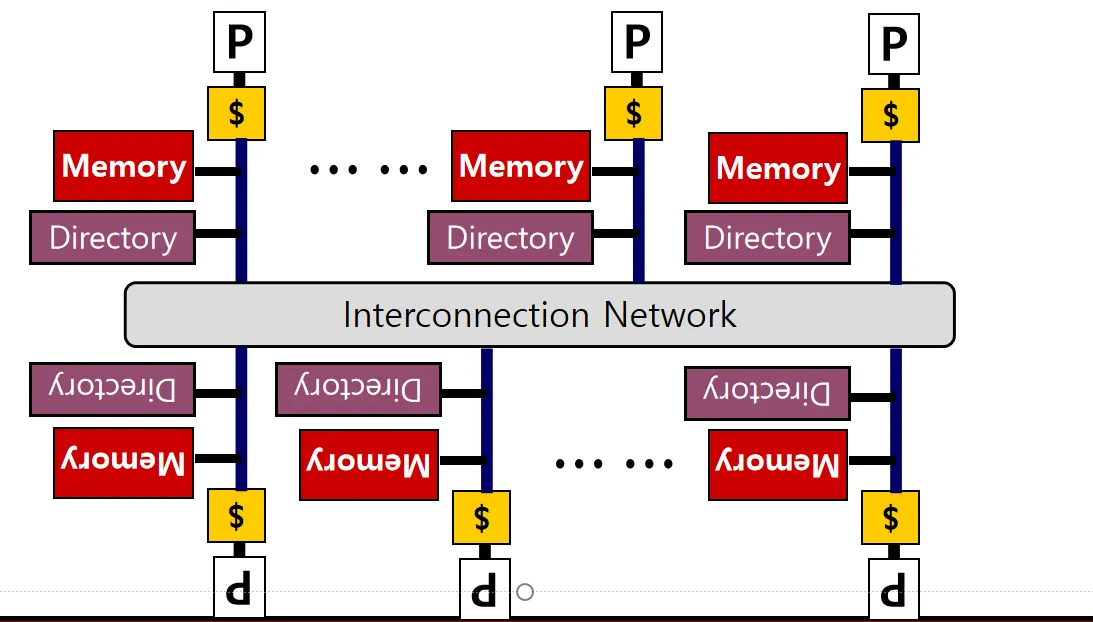
图中的Interconnect可以是总线,也可以是Mesh网络
下面分析几种情形
情景1:Read Miss
Case A:设数据 Z 是共享的(clean但不是modified)
- P0想要访问数据Z,访问HomeNode
- HomeNode 返回数据Z
- 更改数据Z的Directory状态,记录P0有数据Z的副本
Case B:设数据Z是共享的(但是是dirty的)
- P0想要访问数据Z,访问HomeNode
- HomeNode 发现数据Z是dirty的,把数据Z的Owner Node(假设是P1)找出来发给P0
- P0找到P1,P1把数据Z发给P0和HomeNode
- 更新 Directory 状态,no-dirty,P0有副本
情景2:Write Miss
设数据 Z 是共享的
- P0想要写数据Z,访问HomeNode
- HomeNode 发现数据Z是shared的,发送共享者的ID给P0
- HomeNode 更新 Directory 状态,dirty,只有P0有副本
- HomeNode 把数据Z发给P0
- P0给共享者发送 Invalidate 请求
- 共享者Invalidate 自己的副本,并向P0发送ack
- P0 Invalidate HomeNode的副本
- HomeNode 返回 ack 给P0
- P0 修改数据Z
太复杂了图就省略了
Summary#
Coherence 的复杂行取决于 cache的类型
- write back 比 write through 复杂
- 多级 cache 比 单级复杂
- cache是否有包含关系也会影响复杂度
Coherence 两种实现
- snooper-based 适合小规模系统
- directory-based 适合大规模分布式系统
Coherence 协议,重点MESI