本文内容基于 2025 秋季《计算机网络》课程讲述,如有差错,欢迎指正
拥塞控制概述#
- 端系统观察什么:传统 TCP 主要通过丢包(超时或 3 个重复 ACK)来感知拥塞,不同的系统可以观察不同的拥塞信号, 如 RTT 变化, 主动发送报文探测等
- 端系统改变什么:通过调整拥塞窗口 (cwnd) 来限制发送速率
拥塞控制改进#
慢启动优化#
主要优化目标:CWND的初始化
随着网络流量变得越来越大,从一个MSS开始增长,可能增长得不够快
- 演进:
- Tahoe:初始 cwnd = 1 MSS
- Linux 2.6:根据 MSS 动态调整
- Linux 3.0 / Google (2010):初始 cwnd = 10 MSS
TCP New Reno#
TCP Reno 收到一个新的 ACK 后,立即退出快速恢复,进入拥塞避免阶段。但如果窗口内有多个数据包丢失了, 此时仍然应该停留在快速恢复阶段,继续重传丢失的数据包。
定义:Partical ACK,确认了重传包但未确认所有已发数据的 ACK
TCP New Reno 改进了快速恢复阶段。
- 当收到 Partial ACK 时,推断有多个包丢失,继续停留在快速恢复阶段,并重传下一个丢失的包
- 直到收到确认所有已发数据的 ACK,才退出快速恢复
SACK#
TCP New Reno 虽然改进了快速恢复,但它一次只能判断并重传一个丢失包,效率仍然不高。
SACK(选择重传)在 TCP 头部 Option 字段中携带 SACK 信息,显式通知发送方哪些不连续的数据块已收到
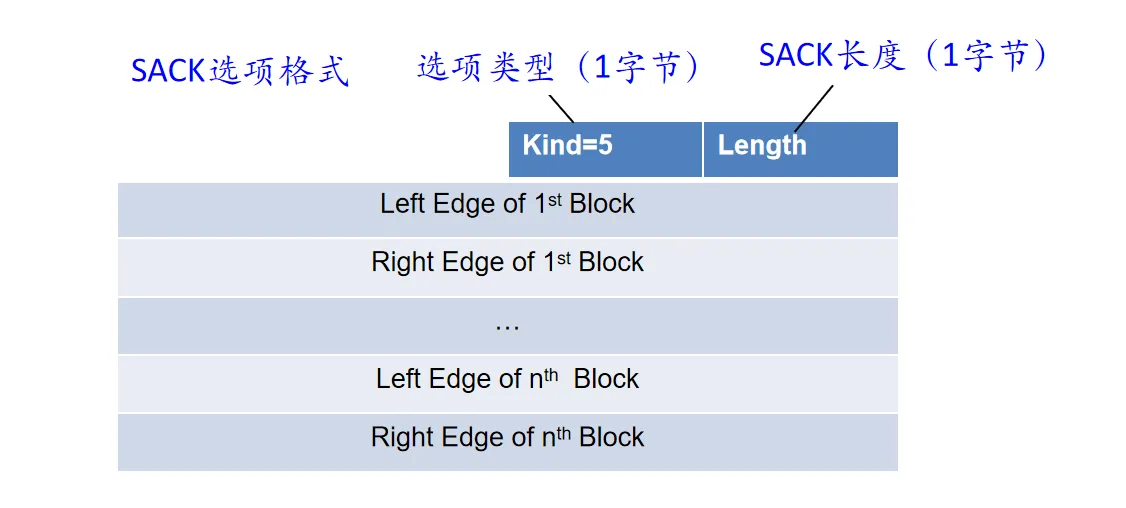 Left Edge表示已收到的不连续块的第一个序号,Right Edge表示已收到的不连续块的最后一个序号+1,即左闭右开区间
Left Edge表示已收到的不连续块的第一个序号,Right Edge表示已收到的不连续块的最后一个序号+1,即左闭右开区间
Option 字段最长是40 字节,每个 SACK 块占8字节,最多携带 4 组 SACK 信息
借助SACK,发送方可以精准重传丢失的数据包,提高了丢包恢复效率
TCP BIC#
对于所有的基于丢包的拥塞控制算法,都想要在拥塞避免阶段尽可能快地找出恰当的cwnd值,本质就是一个搜索的过程, 因此BIC算法的核心思想是使用二分查找来搜索最优窗口值
机制:
- Wmax:上次发生丢包时的窗口大小(上界)
- Wmin:丢包后乘性减后的窗口大小(下界)
- 二分增长:在 Wmin 和 Wmax 之间进行二分搜索(每个RTT通过ACK 判断丢包来确定新的上下限),快速找到一个合适的窗口值
- 对于二分查找的增长值设立一个上下界:
- Smax:最大步长,防止增长过快导致频繁丢包
- Smin:最小步长,防止增长过慢
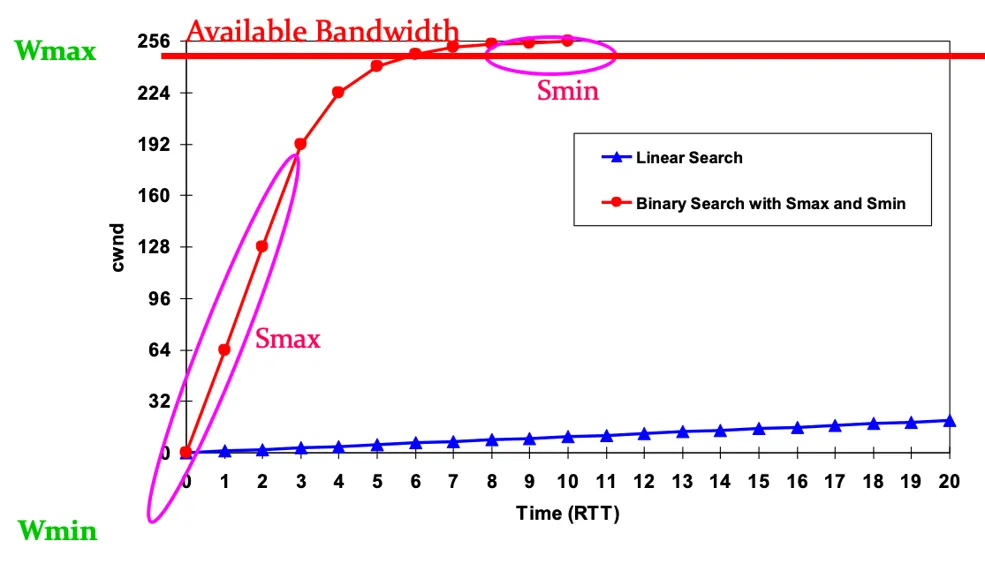
如果可用带宽增大,当cwnd超过了 Wmax怎么办?(二分搜索无法进行)
BIC采取了一种非常简单直接的方法:按照逼近Wmax的路径倒回去,即采用与之对称的方案
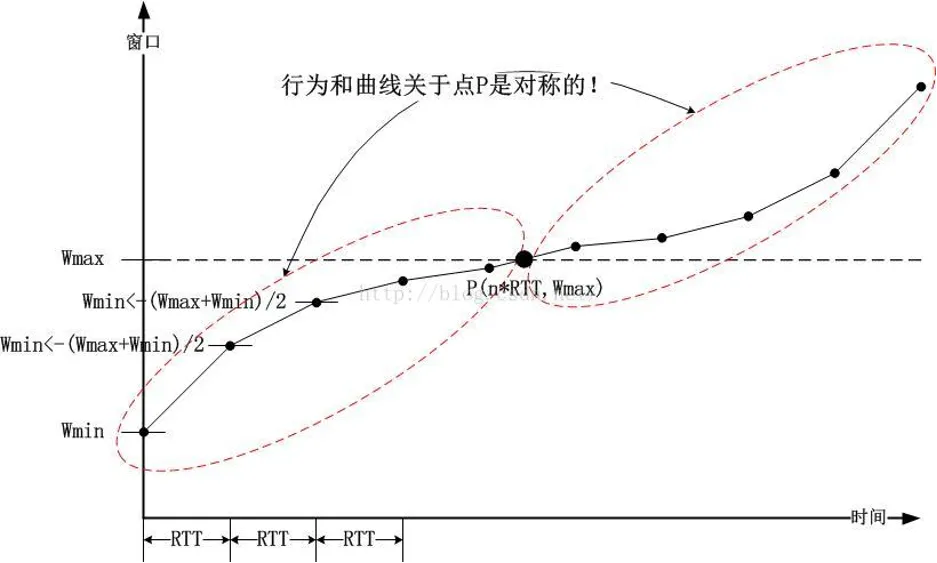
BIC将传统拥塞避免阶段线性增大探查Wmax 的过程转变为二分查找 ,窗口增长速度大大快于线性查找,有效提高了带宽利用率
但是这种ACK驱动的增长方式会导致不同RTT的流之间不公平性:
- 短RTT流增长更快,长期占用更多带宽
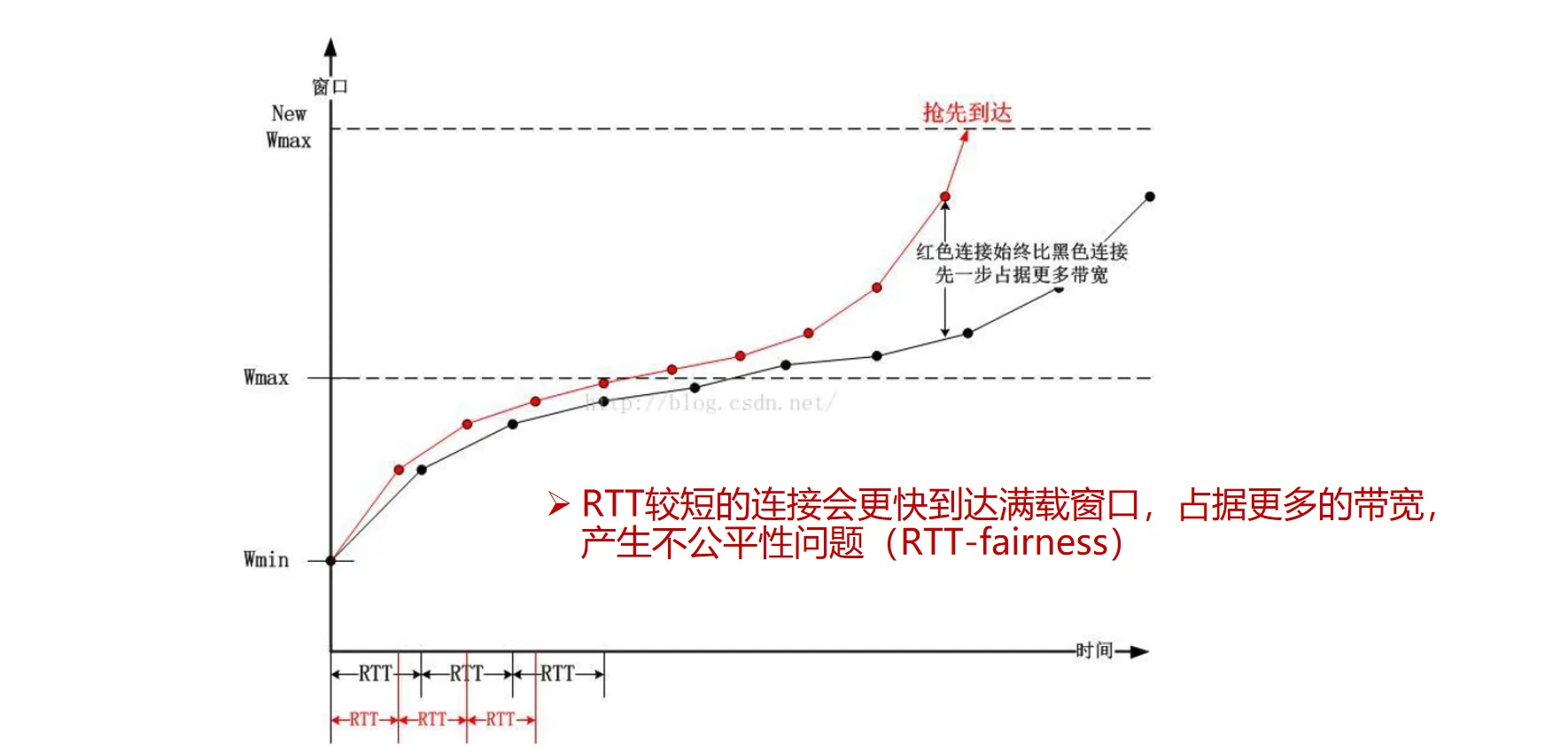
此外,由于ACK延迟到达或丢失的问题,导致BIC算法实际实现要比理论更加复杂
TCP CUBIC#
Cubic对于窗口增长仅取决距离上一次丢包所经过的时间,而不依赖 RTT,这样与网络的时延无关,解决了BIC的不公平问题和复杂性
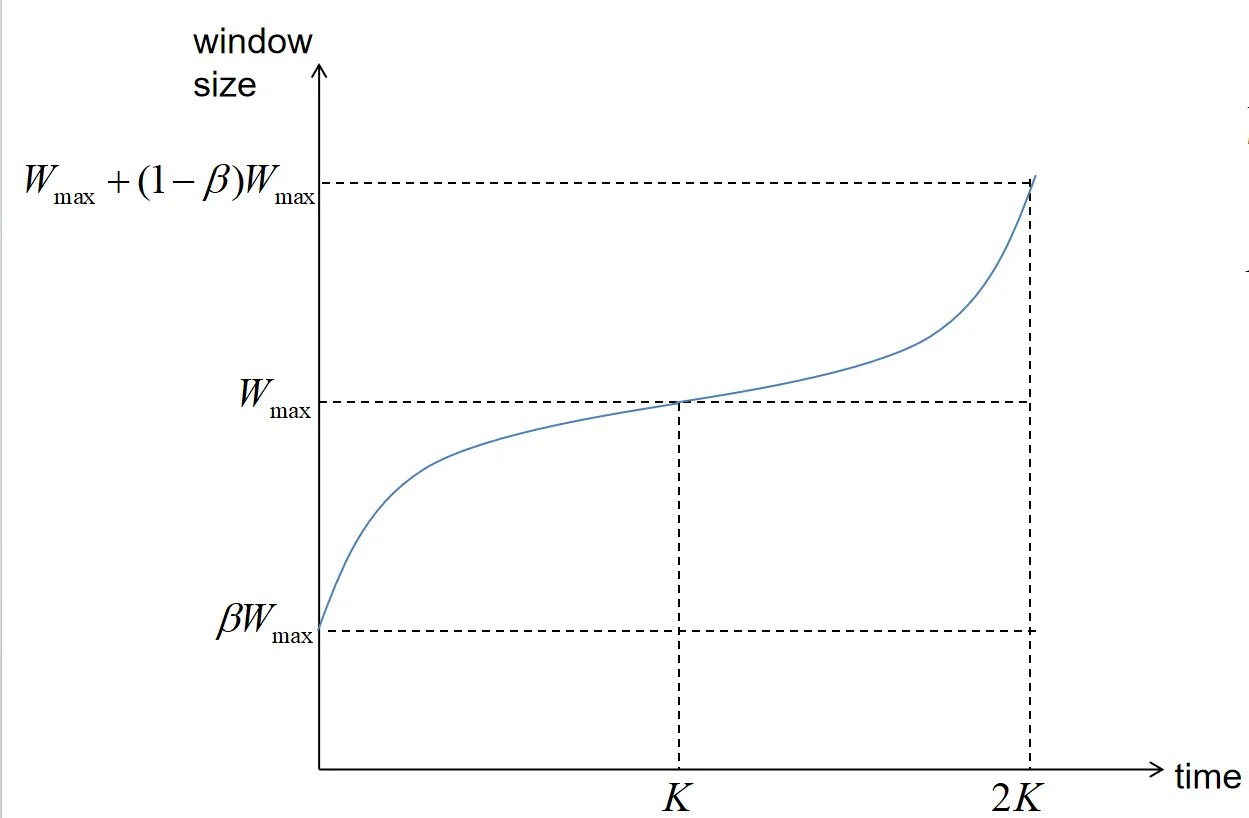
Cubic 沿用BIC的思想,去快速逼近Wmax,使用三次函数拟合 BIC 的二分查找曲线。
- Steady State Behavior阶段:快速逼近 ,然后减缓增长,在 附近停留(稳定区)
- Max probing阶段:若无丢包,越过 后加速探测
一些参数:
- C:调整曲线陡峭程度的常数,C越大,探测到最大窗口的时间越短
- K:从上次丢包到达到 所需的时间
- 区间起始时刻为最近一次检测到丢包的时间
Cubic因为不依赖于 RTT ,公平性好;还保持了 BIC 快速利用带宽的优点
TCP Vegas#
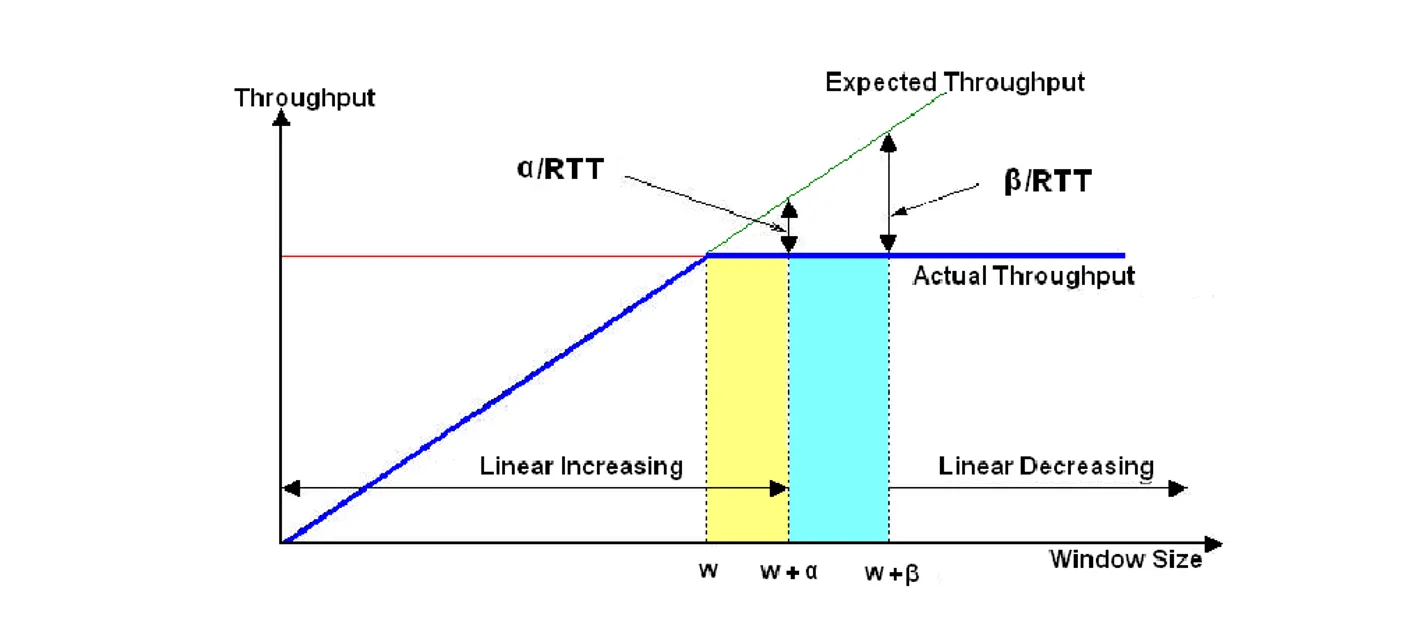
与先前的拥塞控制不同,Vegas利用 RTT 的变化来预测拥塞,而不是丢包。根据实际吞吐量和期望吞吐量之间的差异,去决定窗口的增长
机制:
- 计算 实际吞吐量 () 和 期望吞吐量 ()的差值 Diff
- 若Diff 很大(大于 ),说明排队严重,线性减小 cwnd
- 若Diff 很小(小于 ),说明链路空闲,线性增加 cwnd
- 若Diff 介于 和 之间,保持 cwnd 不变
- 如果计算出来的RTT 大于超时阈值,则直接重传
这个算法没有大规模部署,但在轻量级系统中比较受关注
TCP Westwood#
这个算法主要针对无线网络,考虑ACK的到达速率。根据这个到达速率,他提出了一个公式,对带宽进行估计,并调整窗口大小
因为在无线网络中,丢包会经常发生(比如受到干扰,不是因为排队),如果用丢包估计拥塞,窗口会减小非常频繁
与其采用丢包这种敏感的事件,不如预先对带宽进行估计。
TCP BBR#
回顾传统的TCP拥塞控制,大多数是基于丢包的,BBR(Bottleneck Bandwidth and Round-trip propagation time)对这个机制进行了反思
如果网络上发生了拥塞,大多数情况是存在一个瓶颈,当报文数量大于该瓶颈的处理能力后,就会产生排队,严重时会导致丢包
如果我们从瓶颈链路的角度来考虑拥塞控制问题,可以推断出我们到底往网络中发送多少数据是合适的
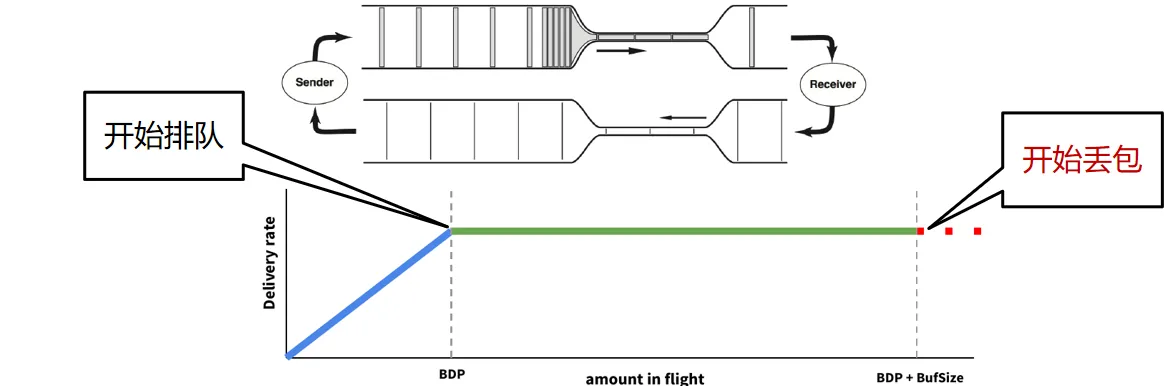
这里面有一个延迟带宽积 (BDP, Bandwidth-Delay Product) 的概念(时延带宽积 ↗)
在这个场景下,BDP=瓶颈链路带宽BtlBw 路径往返时间Rtprop (链路的带宽就是瓶颈带宽)
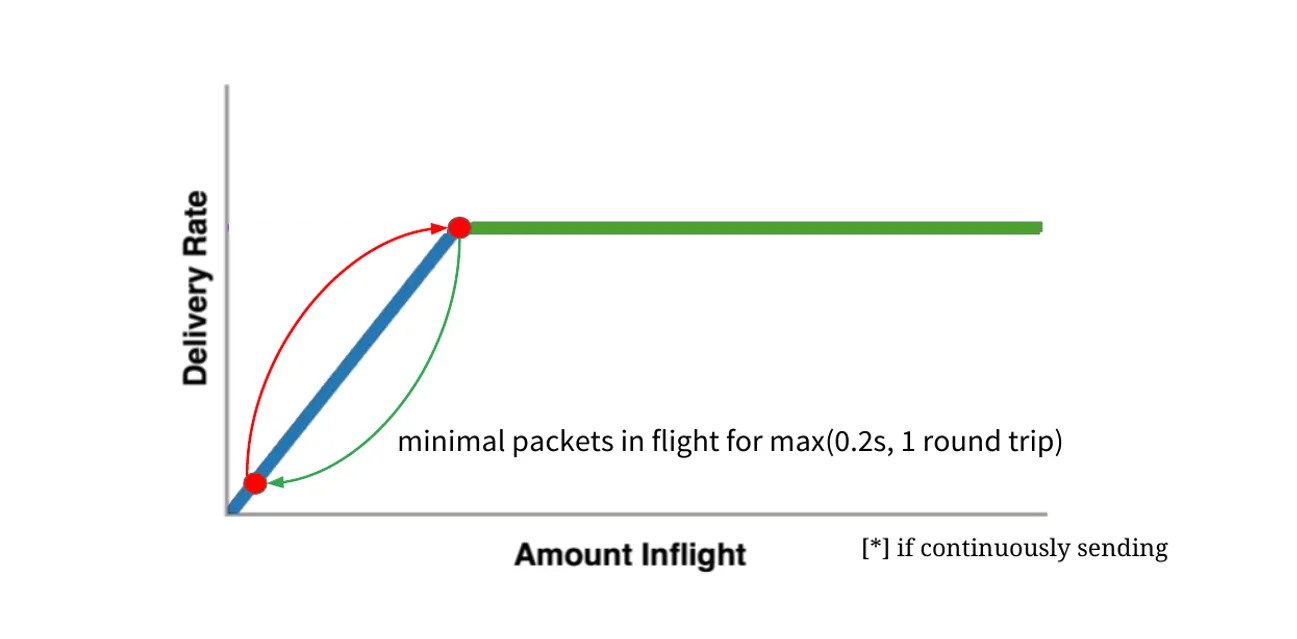
刚开始注入网络的数据量小于BDP时,数据包在网络中流动,没有排队,RTT较小,交付率等于注入速率(蓝线); 当注入网络的数据量到达瓶颈链路BDP时,在瓶颈链路处形成排队,导致RTT延长,交付率却不再增长(绿线); 而瓶颈链路处的缓冲区有限(大小设为BufferSize),不断被填满,当数据量持续增加到BDP + BufferSize时,就开始丢包(红线)
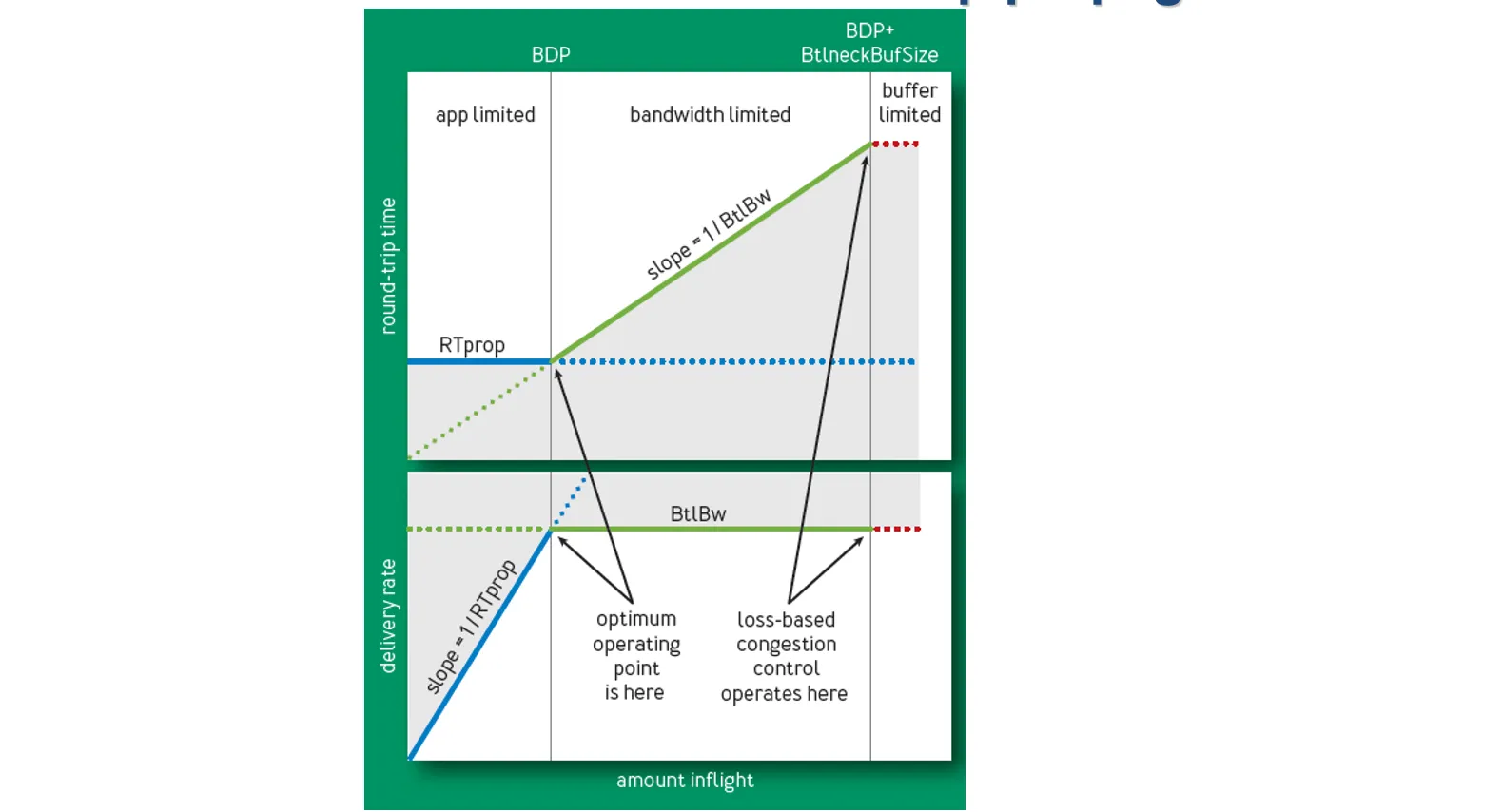
BBR认为,网络中最佳的注入数据量应该是 BDP,而不是 BDP + BufferSize(传统 TCP 的做法,丢包时调整),这样既保证了交付率又降低了时延。 同时,使缓冲区保持比较空的状态,也能更好应对突发流量
因此,BBR的核心思想是通过测量瓶颈带宽 (BtlBw) 和最小往返时间 (Min RTT) 来估计 BDP,从而使cwnd去接近这个值
但是 BtlBw和Min RTT 不能同时测量:
- 要测量最大带宽,就要把瓶颈链路填满,此时buffer中存在排队分组,延迟较高
- 要测量最低延迟,就要保证链路队列为空,网络中分组越少越好,cwnd较小
实际中,BBR 周期性(每隔十秒)测量一次 BtlBw 和 Min RTT,把它当作下一段时间的估计值
测量分为若干个阶段:
- 启动阶段(START_UP)
- 类似TCP的慢启动,指数增加发送速率,尽可能快地占满管道
- 如果连续三次增长发现交付率不再增长,认为已经达到 BtlBw,进入下一阶段
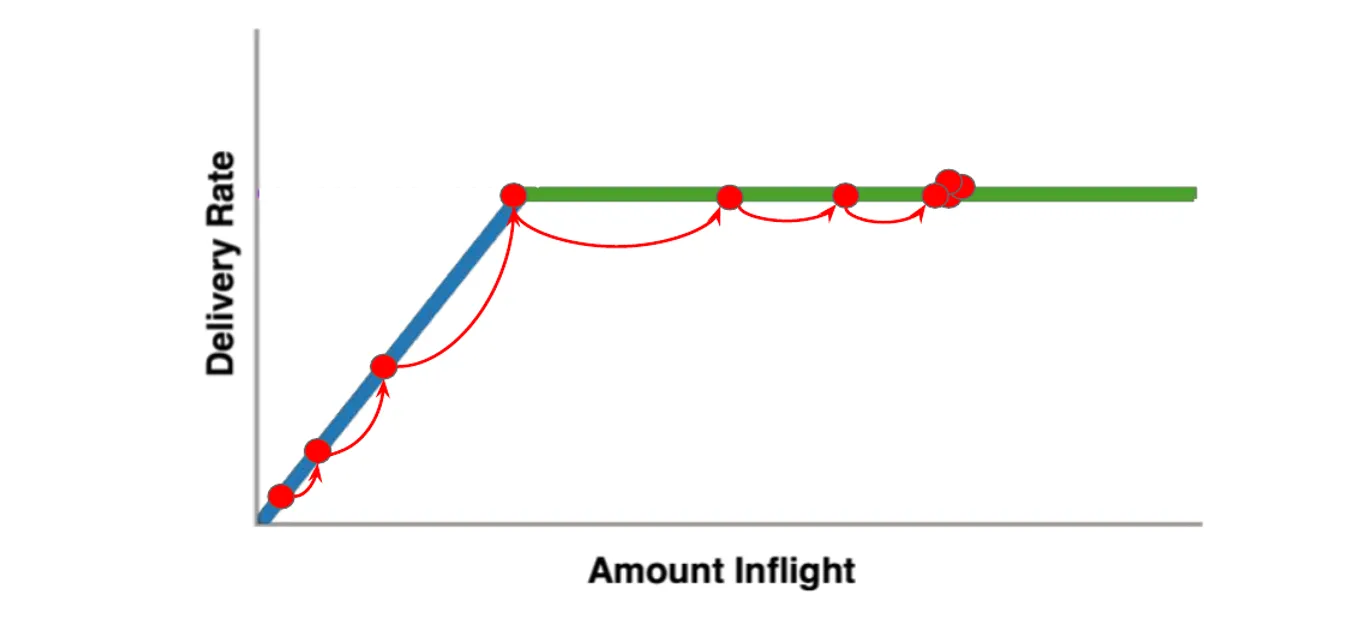
- 排空阶段(DRAIN)
- 指数降低发送速率(相当于是startup的逆过程),将多占的数据慢慢排空
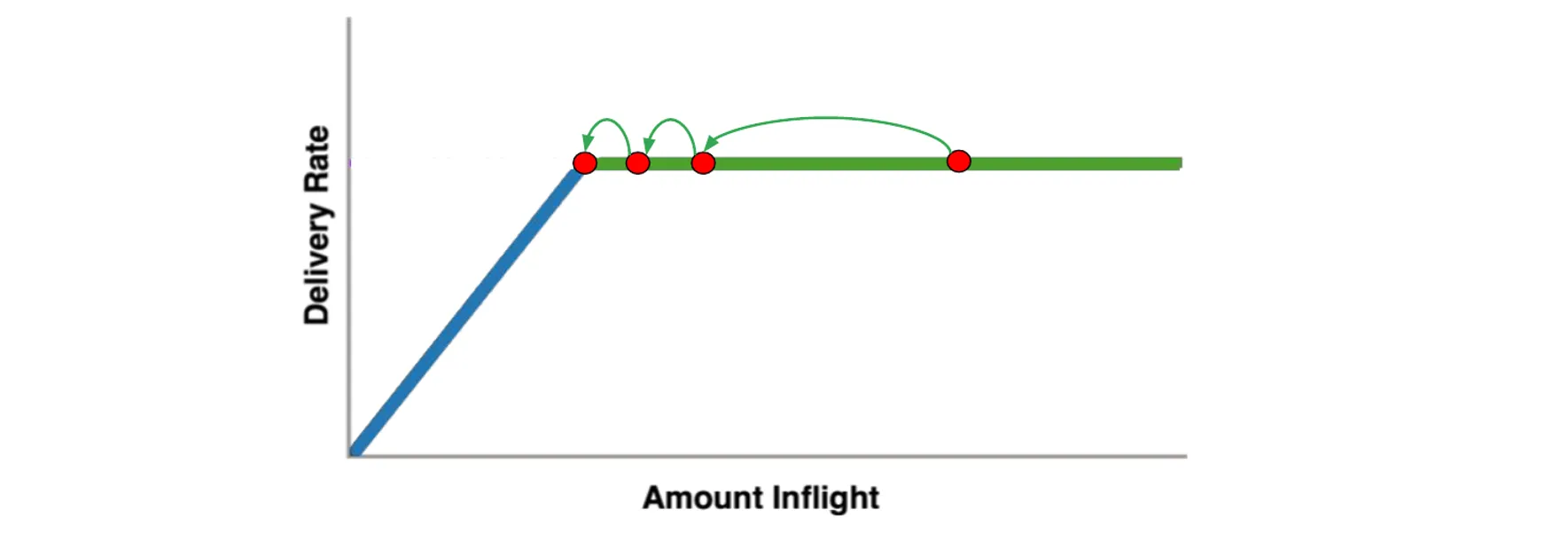
- 瓶颈带宽探测(PROBE_BW):
- 进入稳定状态后, 先在一个RTT内增加发送速率,探测最大带宽
- 如果RTT增大(发生排队),再减小发送速率,排空前一个RTT多发出来的包
- 后面6个RTT使用更新后的估计带宽发送
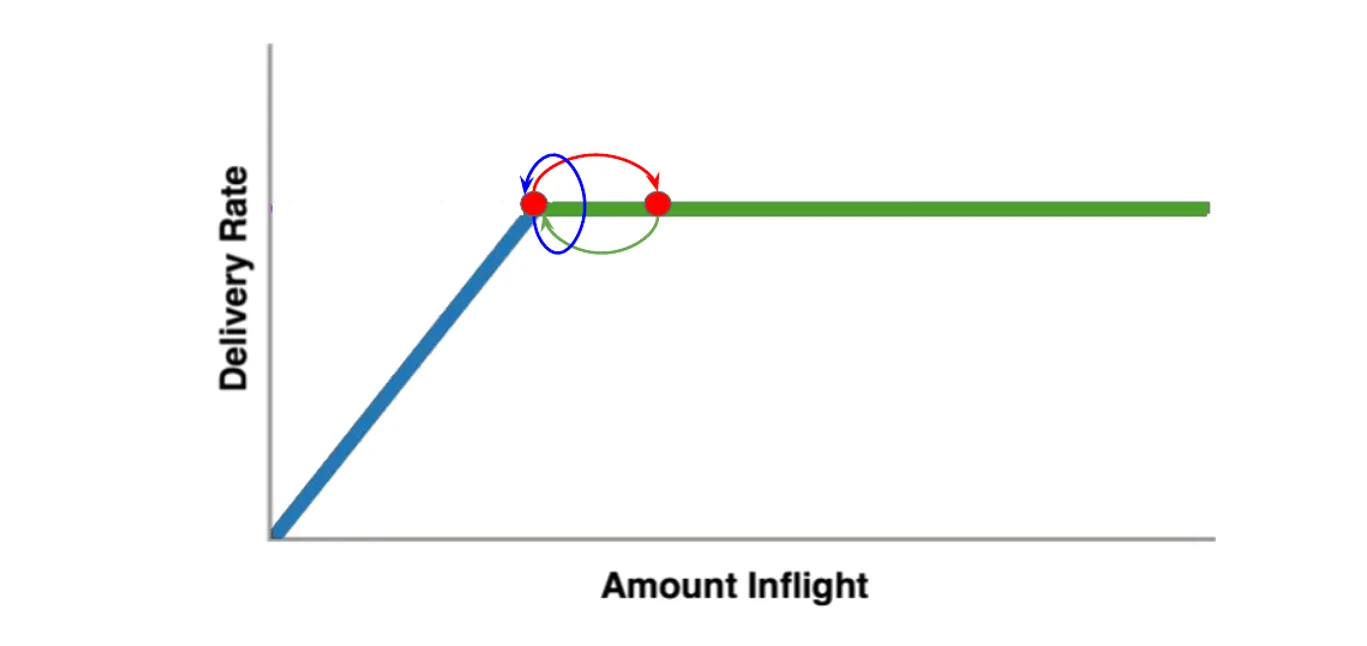
- 时延探测(PROBE_RTT):
- 每过10秒且RTT未更新,就进入时延探测阶段
- 在这段占200ms(全过程2%的时间内),cwnd固定为4个包
- 测得的RTprop作为基准,在瓶颈带宽探测阶段判断是否发生排队
BBR的性能比传统的TCP提升的非常明显,在相同吞吐率的情况下,时延和丢包都更少
但与此同时,BBR不断探测可用资源并控制窗口的策略会导致它与传统TCP不公平竞争,长期占用更多带宽(流氓算法)
DCTCP#
DCTCP是针对数据中心的TCP拥塞控制算法
与一般网络中流量不同,数据中心流量有一些特点
- 混合流量:
- 短流(延迟敏感):用户操作、查询
- 长流(吞吐敏感):数据传输、备份
- 长流的流量占据缓冲区会导致短流发生丢包或高延迟
- 突发流量(Incast):
- 许多计算任务同时完成,导致大量数据同时返回
- 交换机缓冲区瞬间被挤满,导致丢包
因此,数据中心的传输协议需要容忍高突发流量、低延迟、高吞吐.想要保持这些特性,只需要维持交换机队列长度尽可能低即可,这就是DCTCP的做法
不同于广域的传统网络,数据中心网络通常可以由管理员进行更加细致的配置和控制,操作网络内部交换机完成一些功能
- 核心思想:利用交换机的 ECN (显式拥塞通知) 进行细粒度拥塞控制
- 机制:
- 交换机:当队列长度超过阈值 时,给包打上 ECN 标记
- 接收端:仅当ECN报文出现或消失时才立即发送ACK,否则采取延迟发送ACK的策略
- 发送端:根据 ECN 标记的比例 (反映拥塞程度),精细化调整 cwnd:
- 每个RTT更新一次发送窗口
- , g是一个加权系数
- 如果发生拥塞,则,否则
总结#
| 算法 | 核心驱动 | 特点 | 适用场景 |
|---|---|---|---|
| Tahoe | 丢包 | 超时后直接进入慢启动 | 早期网络 |
| Reno | 丢包 | 超时后进入快速恢复 | 经典标准 |
| New Reno | 丢包 | 改进多包丢失恢复 | 经典标准 |
| BIC | 丢包 / 时间 | 二分查找上限 | 被cubic替代 |
| CUBIC | 丢包 / 时间 | 三次函数增长 | Linux/Win 默认 |
| Vegas / Westwood | RTT (延迟) | 主动避免拥塞 | 无线网 |
| BBR | 带宽 & RTT 模型 | 主动探测 BDP | 广域网 (Google) |
| DCTCP | ECN (交换机反馈) | 维持极低队列 | 数据中心 |