本文内容基于 2025 秋季《计算机体系结构》双语班课程讲述,如有差错,欢迎指正
Dynamic Scheduling#
静态调度的核心在于依赖编译器进行优化。编译器在生成代码时,尝试找出可以并行执行的指令序列,并通过技术手段如 Loop Unrolling、Software Pipelining 或Global Scheduling来重新排列指令,以减少流水线停顿
相比之下,动态调度依赖硬件在运行时决定指令的执行顺序。CPU 硬件负责动态地识别哪些指令可以并行执行,并处理指令间的同步
从硬件角度看,动态调度引入了复杂的硬件结构,这些复杂的机制甚至带来了一些安全隐患,但它们仍然是现代处理器不可或缺的部分
在本文中,动态调度特指乱序执行。我们主要关注在顺序发射的的架构下,如何实现指令的乱序执行
关于乱序执行#
考虑一个场景
LOAD R1, 0(R2)
ADD R3, R1, R4
SUB R5, R6, R7
...假设第一条指令发生了Cache Miss,导致流水线停顿。如果处理器采用顺序执行,那么后续的指令必须等待 LOAD 指令完成才能继续执行。但如果处理器能识别依赖关系,发现后续的 SUB 指令与 LOAD 指令无关,那么它可以在等待内存时先执行 SUB 指令,从而缩短整体执行时间
因此,Superscalar结合乱序执行被认为是提升处理器性能的最优解
但同样,乱序执行需要面临Hazard问题。除了传统的 RAW 之外,还需要考虑 WAR 和 WAW 这些在顺序执行中不需要考虑的问题。CPU 需要实现像 Register Renaming 这样的机制来解决这些问题
最后我们看一下要实现乱序执行需要的一些结构:
- 我们不能像以前一个一个取指令并运行,而是要一次性取多条指令放到Instruction Window里
- 在其中进行Hazard的检测并通过比如Register Renaming来解决
- 最后 Schedule 指令来考虑如何把并行度提高
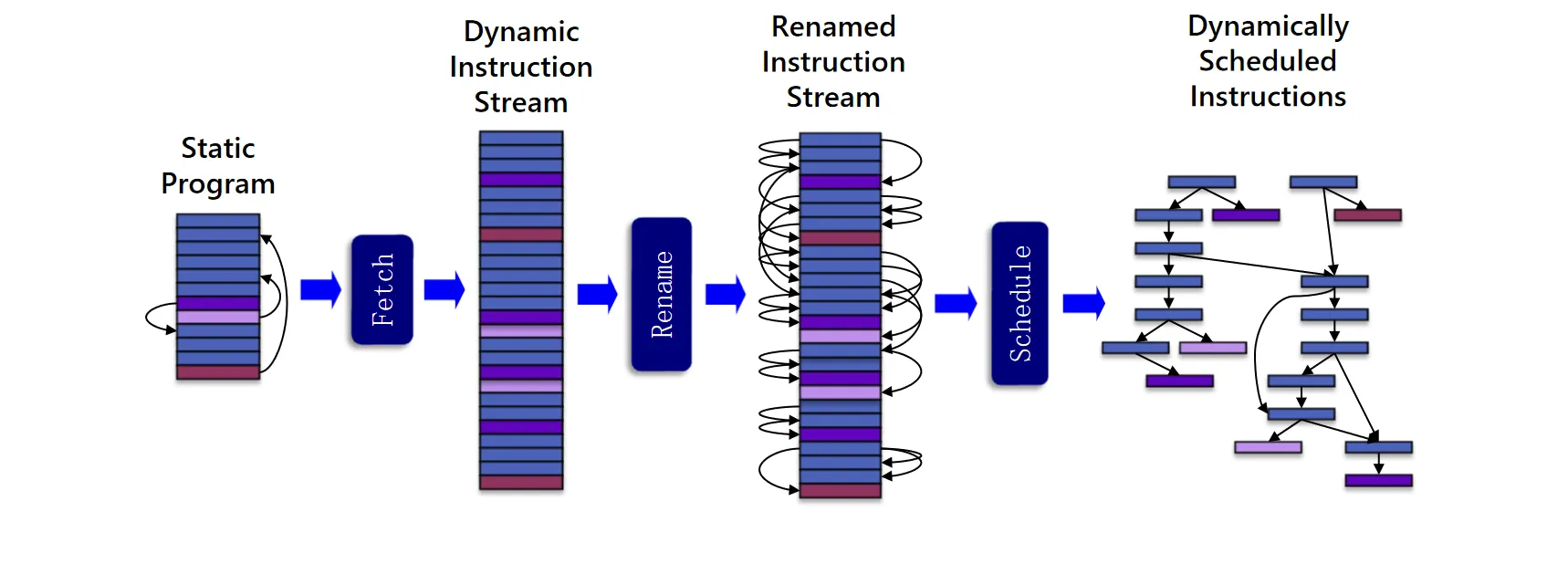
实际Decode阶段被划分为三个子阶段:
- Dispatch:从指令缓存中取指令并放入Instruction Window
- Issue:从Instruction Window中选择可以执行的指令并分配给相应的功能单元
- Read operands:从寄存器读取操作数
Scoreboard#
Scoreboard 是最简单的一种乱序执行实现方式,它没有使用我们之前说的任何优化,它只是通过追踪指令执行状态、FU的占用情况以及寄存器的状态等信息来检测Hazard。且 Scoreboard 仅通过 Stall 的方式来避免Hazard
Scoreboard 的 pipeline:
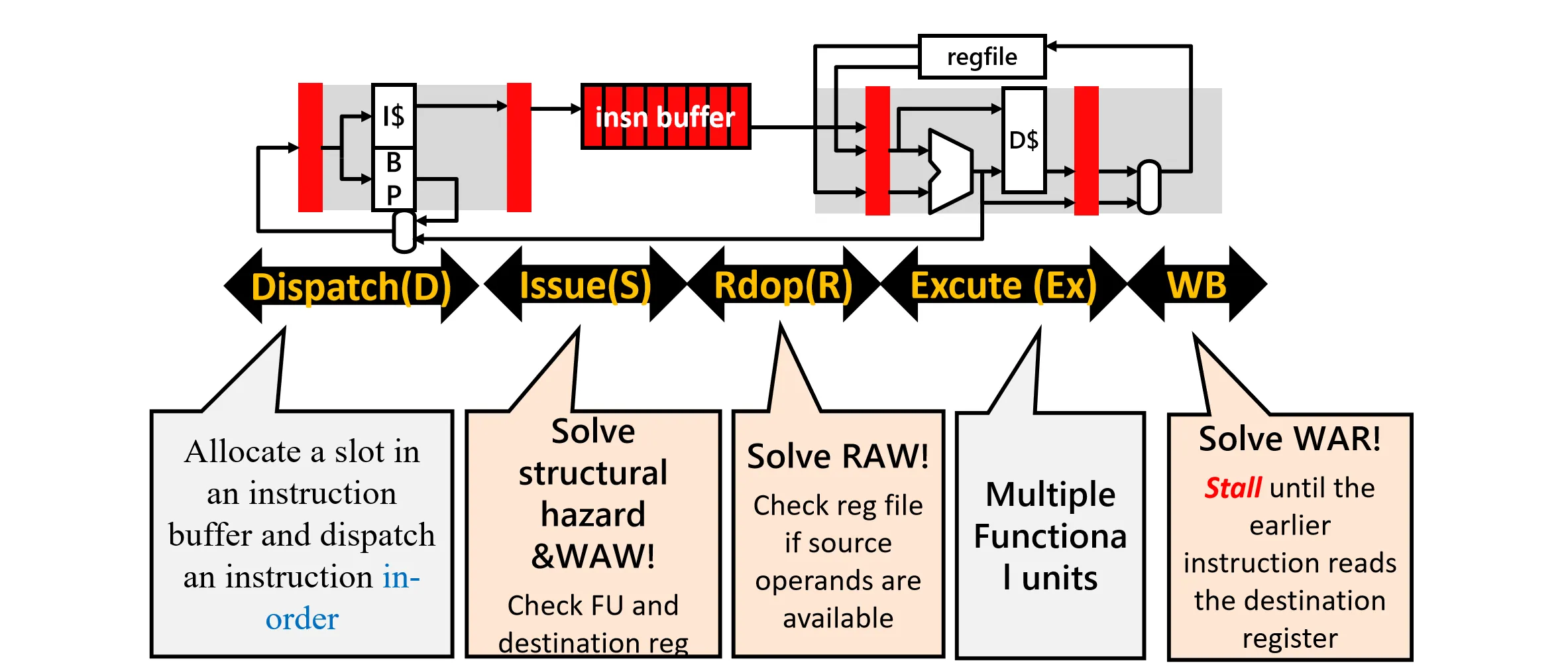
为了简化,我们这里认为指令已经放入Instruction buffer(window),且忽略访存。指令的执行分为四个阶段:
- Issue:检查指令是否可以发射(检查Structural Hazard和WAW)
- Read operands:检查是否可以读取操作数(检查RAW)
- Execute:指令在功能单元中执行
- Write back:将结果写回寄存器(检查WAR)
为了实现上述控制,Scoreboard 维护了三个主要的数据结构:
- Instruction Status Table:记录每条指令的当前状态
- ID1:Issued
- ID2:Read Operands
- EX:Executing
- WB:Write Back
- Functional Unit Status Table:记录每个功能单元的状态
- B:FU是否忙碌
- Op:正在执行的操作
- dst:目标寄存器
- src1, src2:源寄存器编号
- Q1, Q2:产生源寄存器值的FU
- R1, R2:源寄存器值是否可用
- Register Result Status Table:记录每个寄存器当前由哪个功能单元写入
一个简化的 Scoreboard 示例:
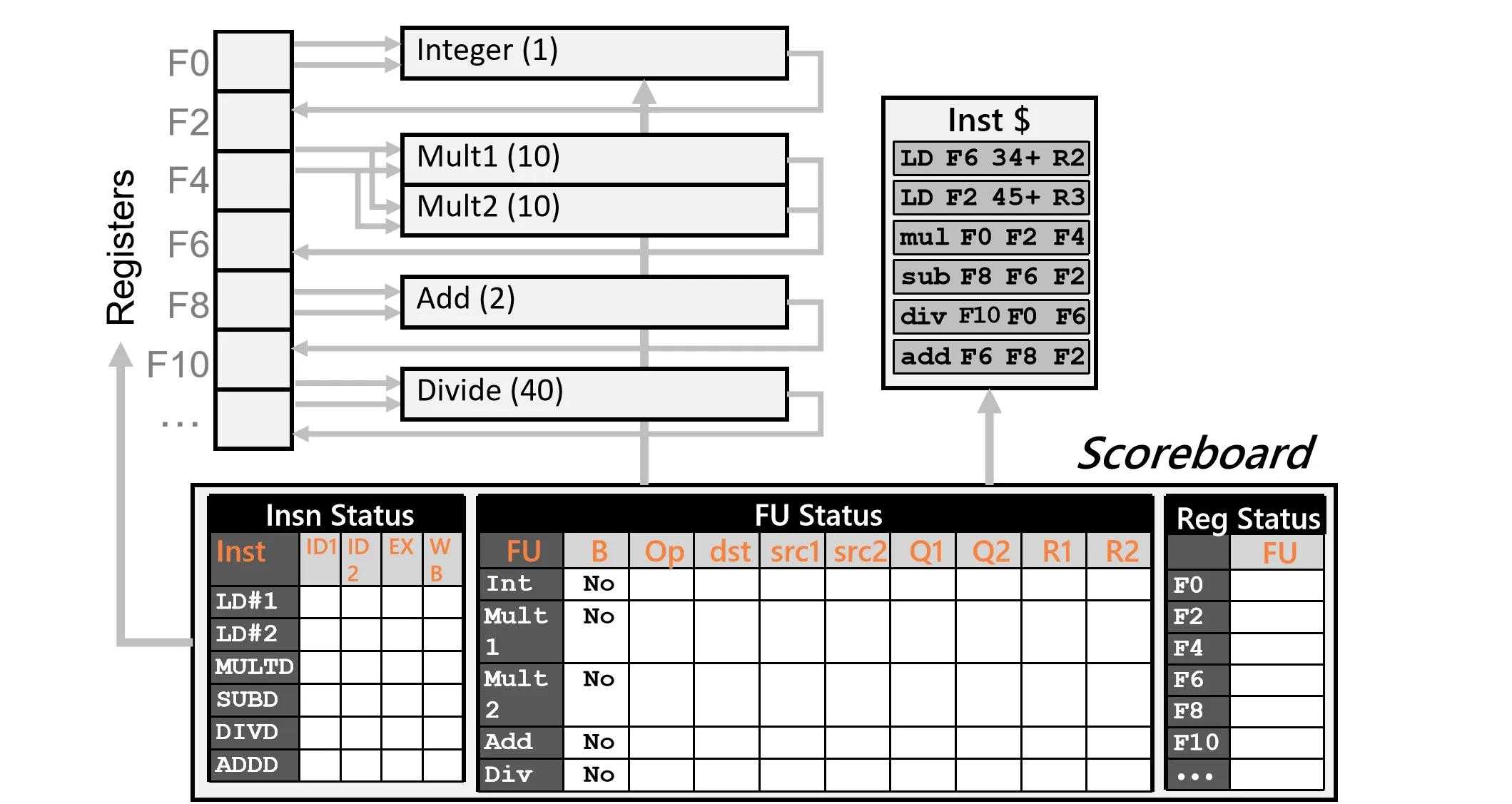
左侧是寄存器,右侧是Instruction Buffer,中间是FU,其中Integer单元用于地址计算。不同类型的计算要花费不同的周期数
下面我们来简单模拟一下 Scoreboard 的执行过程
Cycle 1:
- Issue Ins 1,检查没有结构冲突和WAW冲突,发射指令,修改Scoreboard状态

Cycle 2:
- Rop Ins 1,检查没有RAW,读取操作数
- Issue Ins 2,发现FU忙碌,结构冲突,Stall
在Scoreboard中,指令都是顺序Issue的,即Ins 2 Stall 后不会去Issue Ins 3
Cycle 3:
- EX Ins 1,开始执行
- 此时Ins 2继续Stall
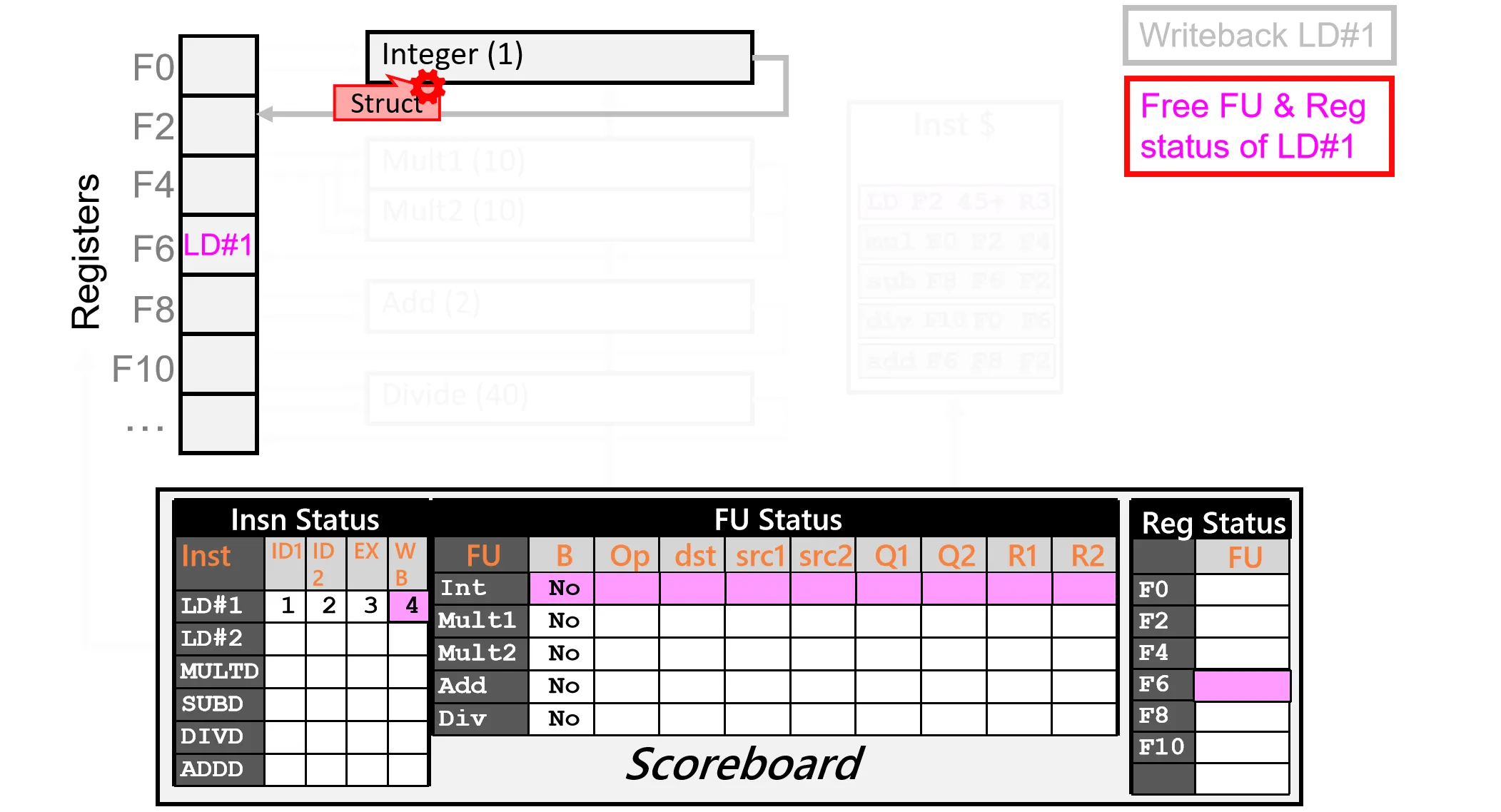
Cycle 4:
- WB Ins 1,写回结果,更新寄存器状态和Scoreboard状态(此时没有结构冲突了,下个Cycle可以 Issue Ins 2)
Cycle 5:
- Issue Ins 2,此时没有冲突,可以发射,更新Scoreboard状态
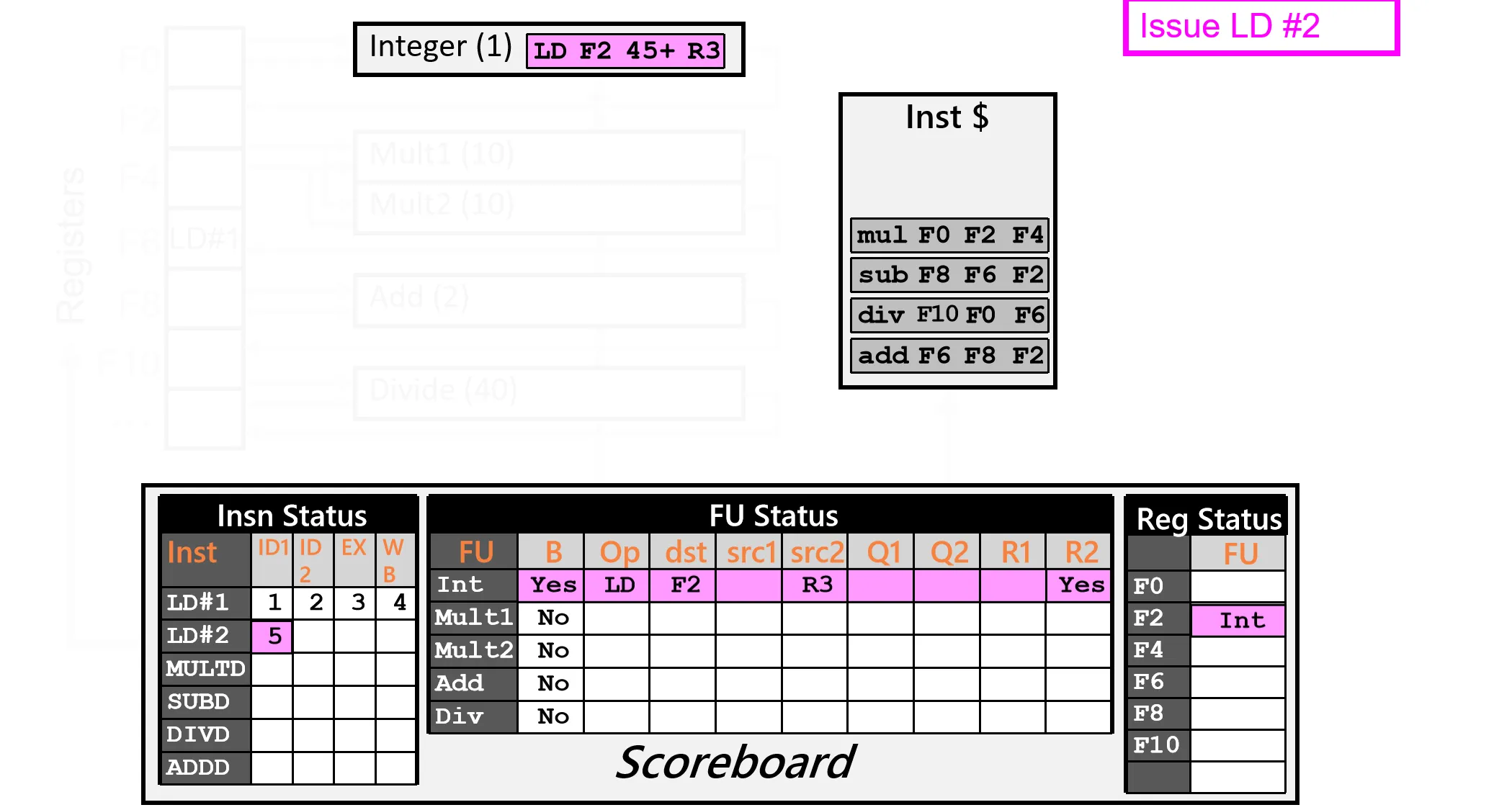
Cycle 6:
- Rop Ins 2,检查没有RAW,读取操作数
- Issue Ins 3,没有 Structural Hazard 和 WAW,发射指令
- 注意到 src1 = F2 寄存器的值是来自于 Int FU的结果,要记在 Scoreboard 里(R1=NO)
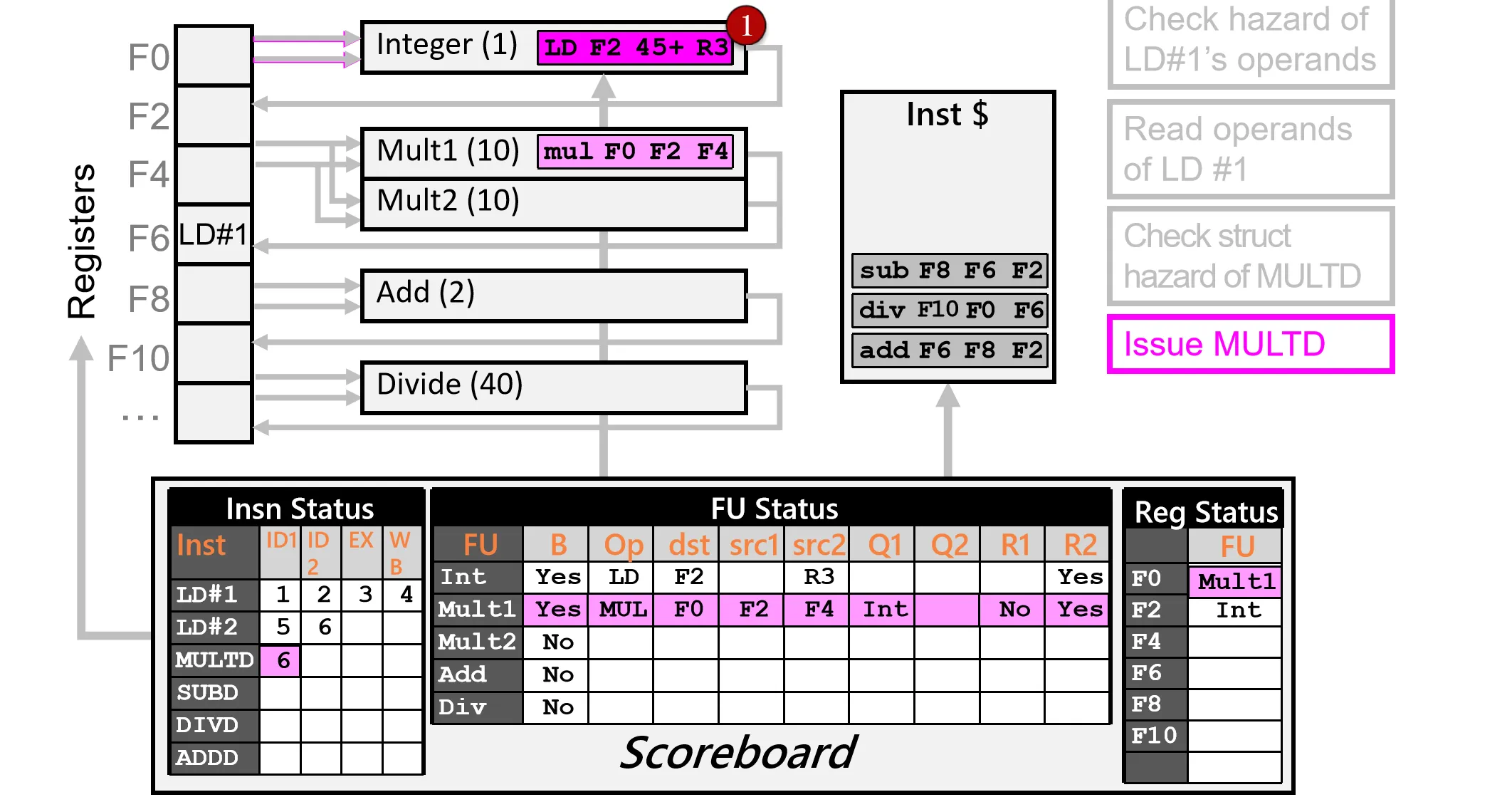
Cycle 7:
- EX Ins 2,开始执行
- Rop Ins 3,检查 RAW,发现 F2 寄存器的值不可用(R1=NO),Stall
- Issue Ins 4,没有结构冲突和 WAW ,发射指令
- 同样注意到 src2 = F2 寄存器的值是来自于 Int FU的结果,要记在 Scoreboard 里(R2=NO)
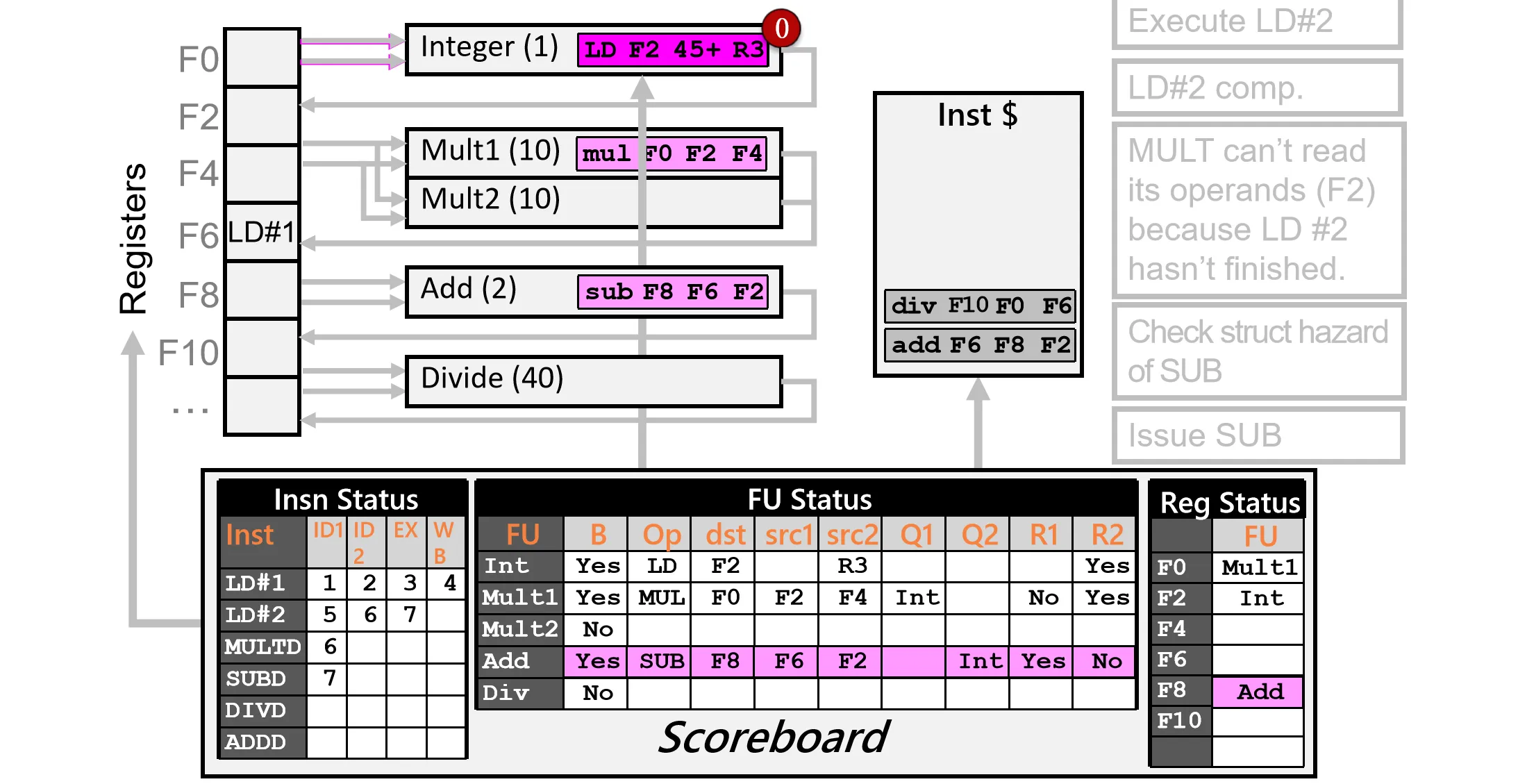
Cycle 8:
- WB Ins 2,写回结果,更新寄存器状态和Scoreboard状态
- Rop Ins 3,Ins 4,此时没有 RAW,下个 Cycle 可以读取操作数
- Issue Ins 5,没有结构冲突和 WAW,发射指令,更新 Scoreboard 状态(R1=NO,因为 src1=F0 来自于 Mult1 FU 的结果)
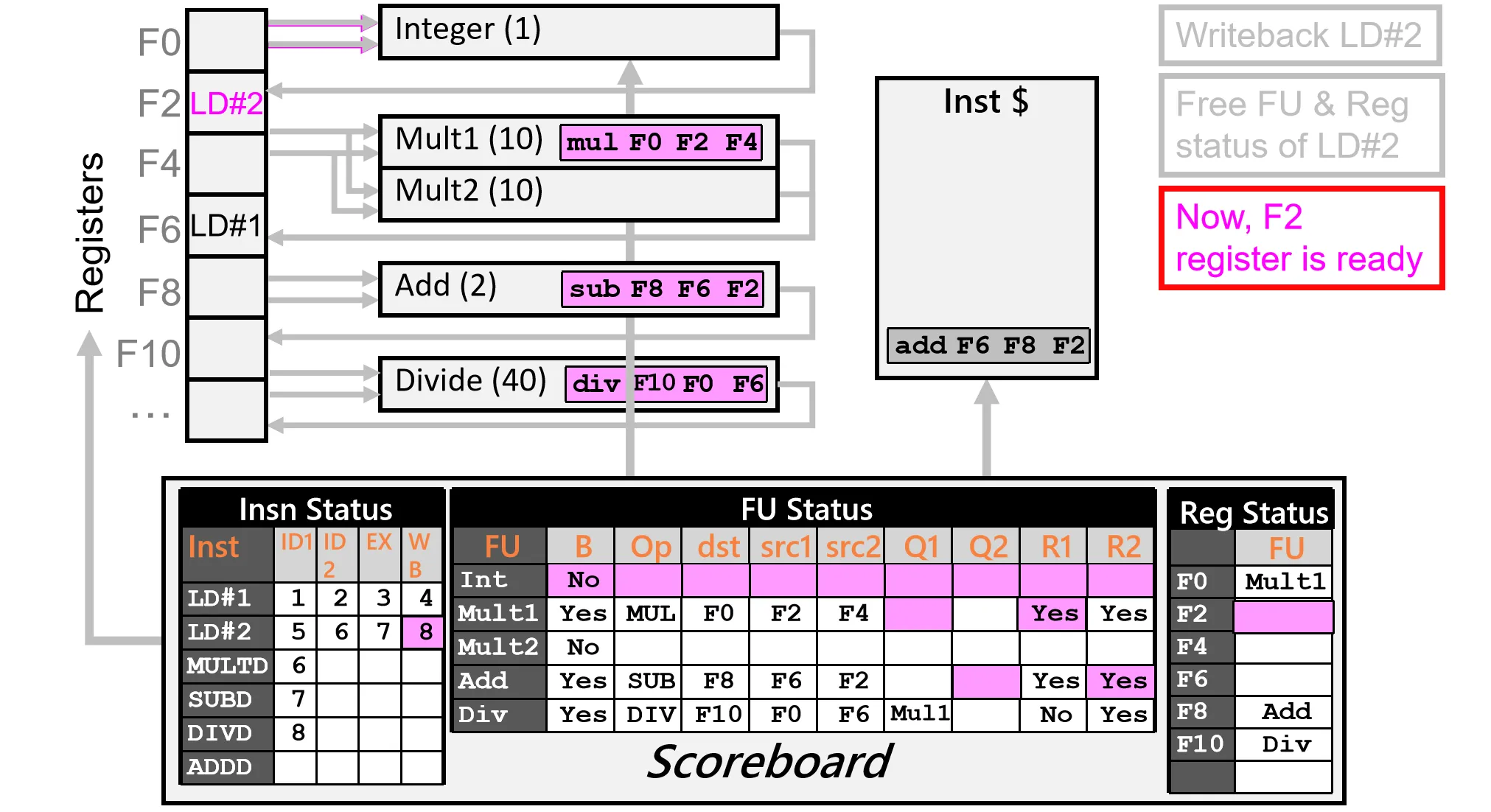
Cycle 9:
- Ins 3和 Ins 4 都可以正常读取操作数
- Ins 5 依赖于 Ins 3 的结果,R1=NO,Stall
- Issue Ins 6,Add FU 被占据,结构冲突,Stall
Cycle 10、11:
- Ins 3 和 Ins 4 执行,Cycle 11 时 Ins 4 完成
- Ins 5 和 Ins 6 继续 Stall
Cycle 12:
- Ins 4 写回,更新寄存器和Scoreboard
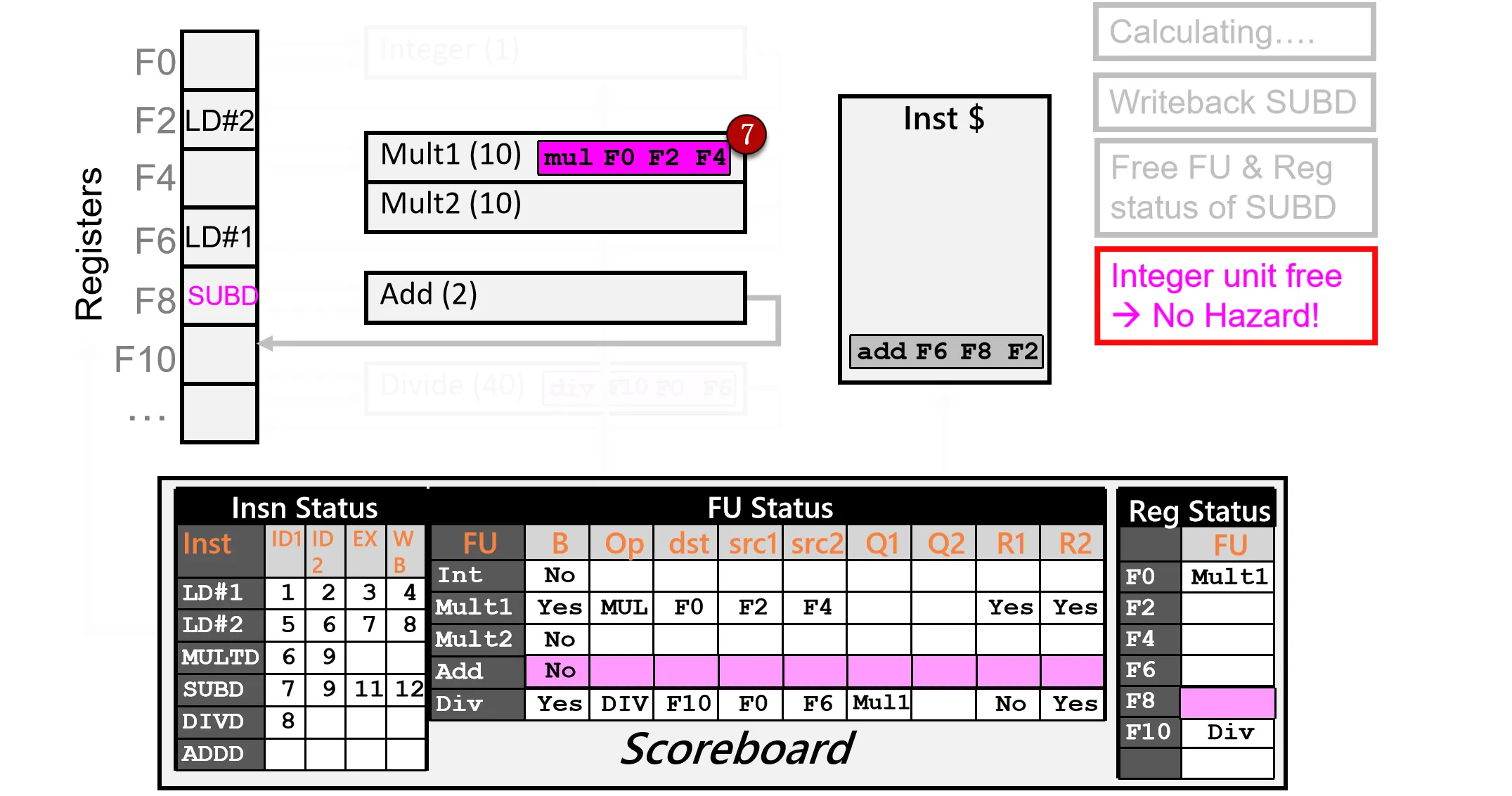
Cycle 13:
- 可以 Issue Ins 6,更新 Scoreboard 状态
Cycle 14、15、16:
- Ins 6 Rop 和 EX
Cycle 17:
- Ins 6 尝试 Write Back,但发现 WAR 冲突(Ins 5 还没读取 F6),Stall
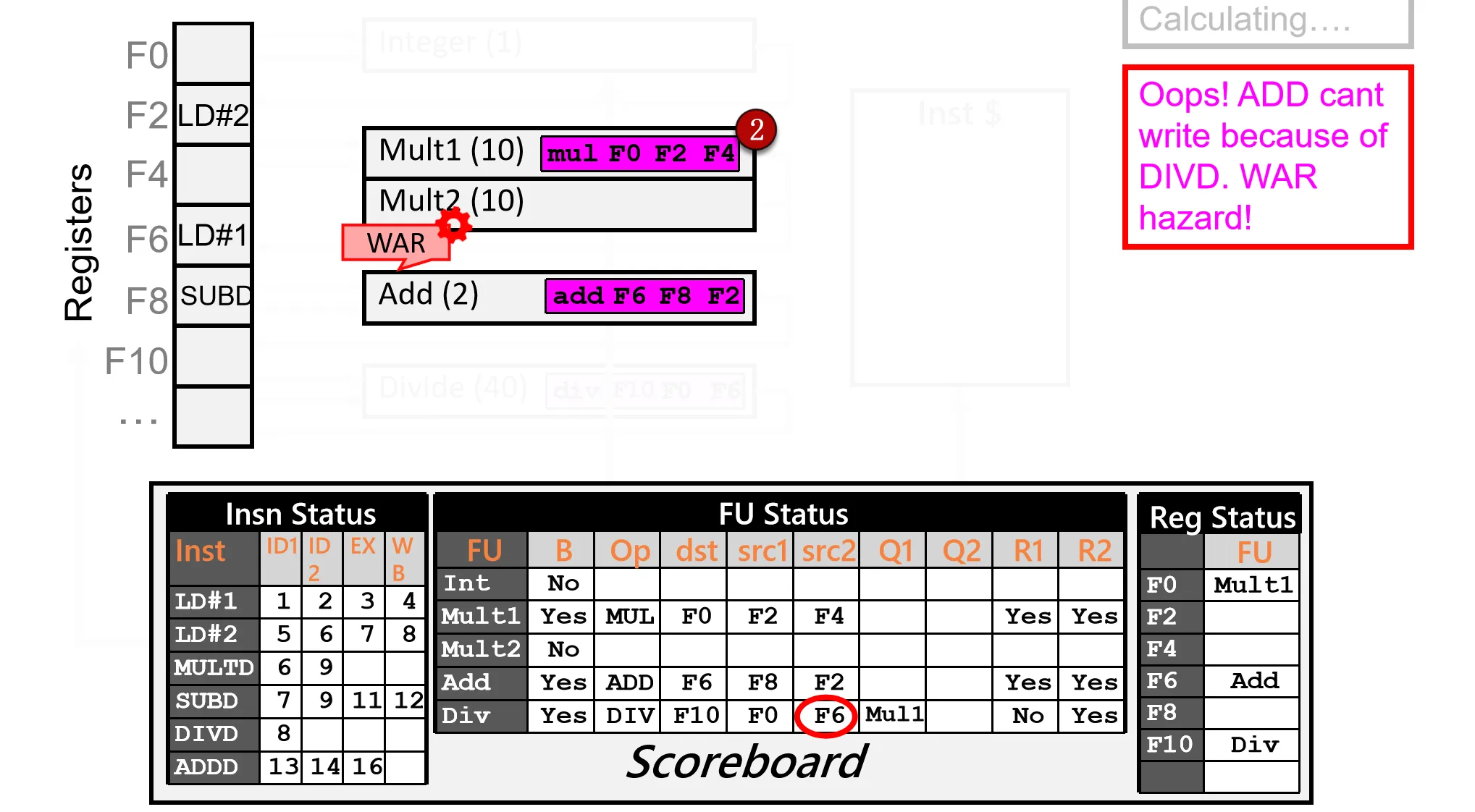
Cycle 19、20:
- Ins 4 执行完成,写回,更新寄存器和 Scoreboard,现在F0 ready
Cycle 21:
- Ins 5 Rop 成功,更新 Scoreboard 状态
- Ins 6 的 WRA 冲突没有了
Cycle 22:
- Ins 6 Write Back 成功,更新寄存器和 Scoreboard 状态
- Ins 5 继续执行
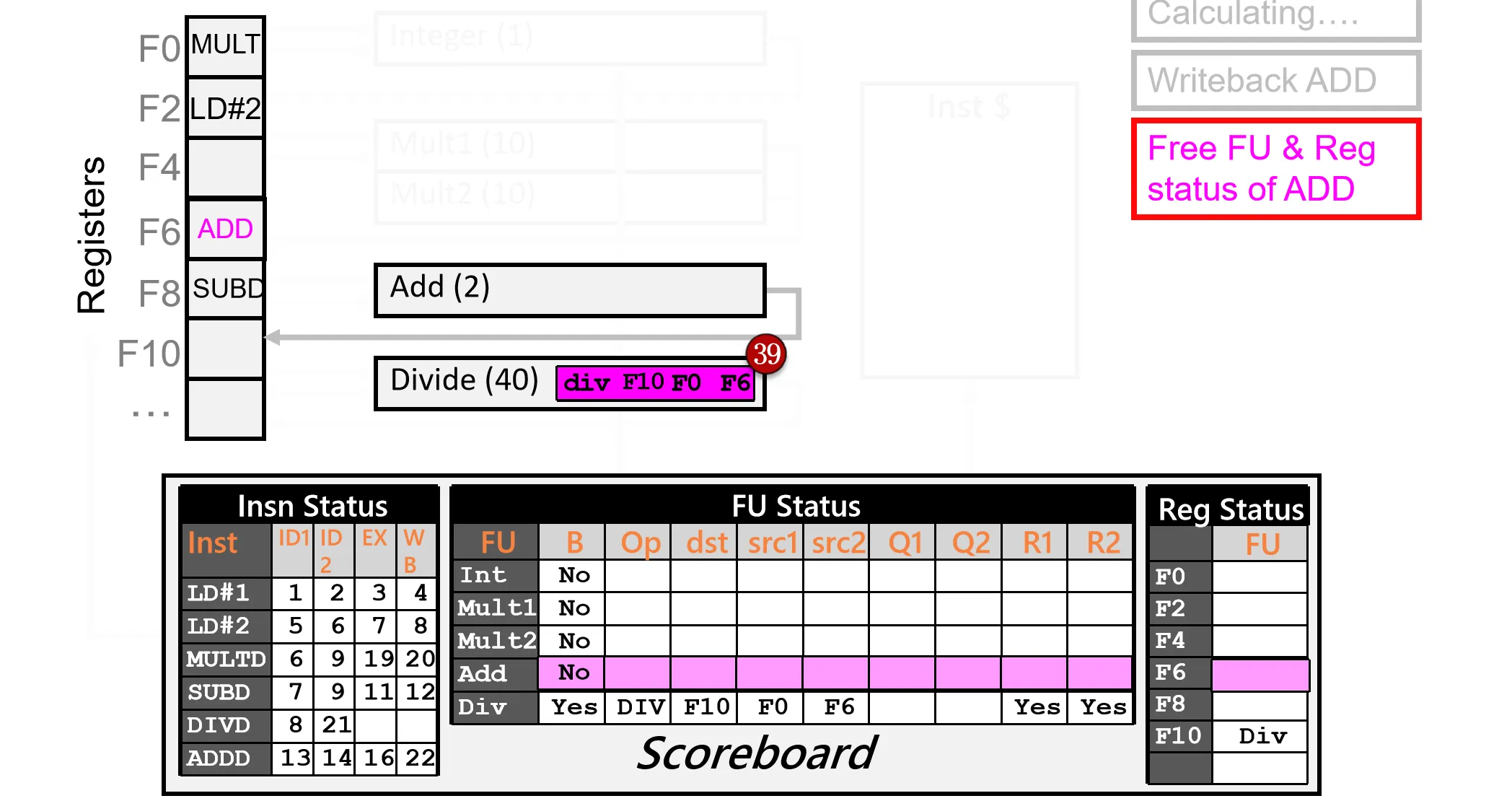
直到最后 Cycle 62 所有指令都执行完毕并写回
Scoreboard 的特征可以总结为:顺序发射,乱序执行,乱序写回
优点:
- 相比后面的一些结构,Scoreboard维护的硬件结构较为简单
- 一部分性能提升
缺点与不足:
- 没有Forwarding/Bypassing
- 通过Stall解决所有冒险
Tomasulo#
Tomasulo的核心思想是通过硬件实现Register Renaming来消除 WAR 和 WAW Hazard,并利用一条Common Data Bus 实现广播式的data forwarding
一个简化的Tomasulo示例:

- 这里面提供了一个单独的Load/Store Buffer用于处理访存指令
- 在 FU 以及 Register File 处有一些缓冲,被称为 Reservation Station(RS) ,功能与Scoreboard类似,在其中实现了 Register Renaming
- CDB 负责在 FU和 Register File 之间广播数据,相当于做了 Fowarding 操作
- 各个 RS 其实是分散在不同位置,这里为了便于后续模拟就放在一起
- RS 中的内容和Scoreboard类似,相同部分省略
- V1, V2:源操作数的值(不像Scoreboard里面记录地址)
- Tag1, Tag2:产生源操作数的 RS
- Addr:用于 Load/Store 指令,存放偏移地址
Tomasulo中指令的执行分为三个阶段:
- Issue(D):检查结构冲突,将指令放入相应的 RS;检查操作数是否可用,如果可用则读取,否则将操作数记录产生该操作数的 RS。最后记录要写入的寄存器 RS 为当前指令
- Execute(X):当指令的所有操作数都准备好后,指令开始在功能单元中执行
- Write Result(W):指令执行完成后,把结果放在 CDB 上,free 写入寄存器的 RS;如果某些在等待该结果的 RS 监听到 CDB 上的数据,则读取该数据直接写在 RS 中
接下来还是按照之前的例子,模拟一下Tomasulo的过程
前面的过程与Scoreboard类似,但由于 Tomasulo 有多个 Load buffer,可以同时发射多条 Load 指令。在第三周期,可以发射第三条乘法指令。但这条指令依赖于 LD2 的结果因此无法直接执行
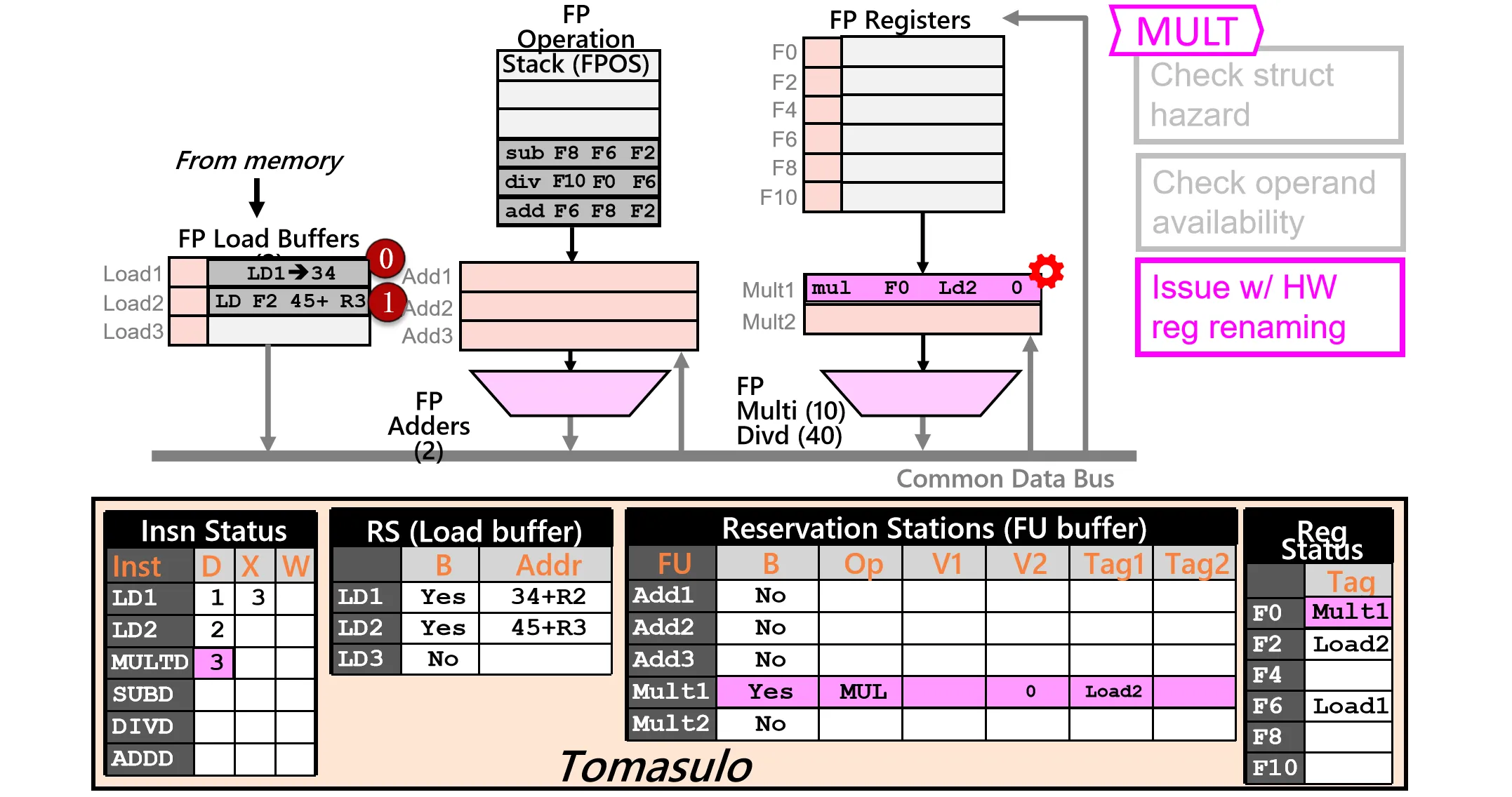
注意这里会把操作数直接写在 RS 里,而不是像 Scoreboard 那样记录地址。Mult 的 第一个操作数来自于 LD2 的结果,因此 Tag1=LD2
Cycle 4:
- LD1 进行写回,结果通过 CDB 广播,更新寄存器和 RS
- LD2 执行完成
- Mult 指令 Stall
- 此时可以Issue 第四条指令 sub,因为 Add RS 还有空位。同时更新依赖关系 Tag2=LD2
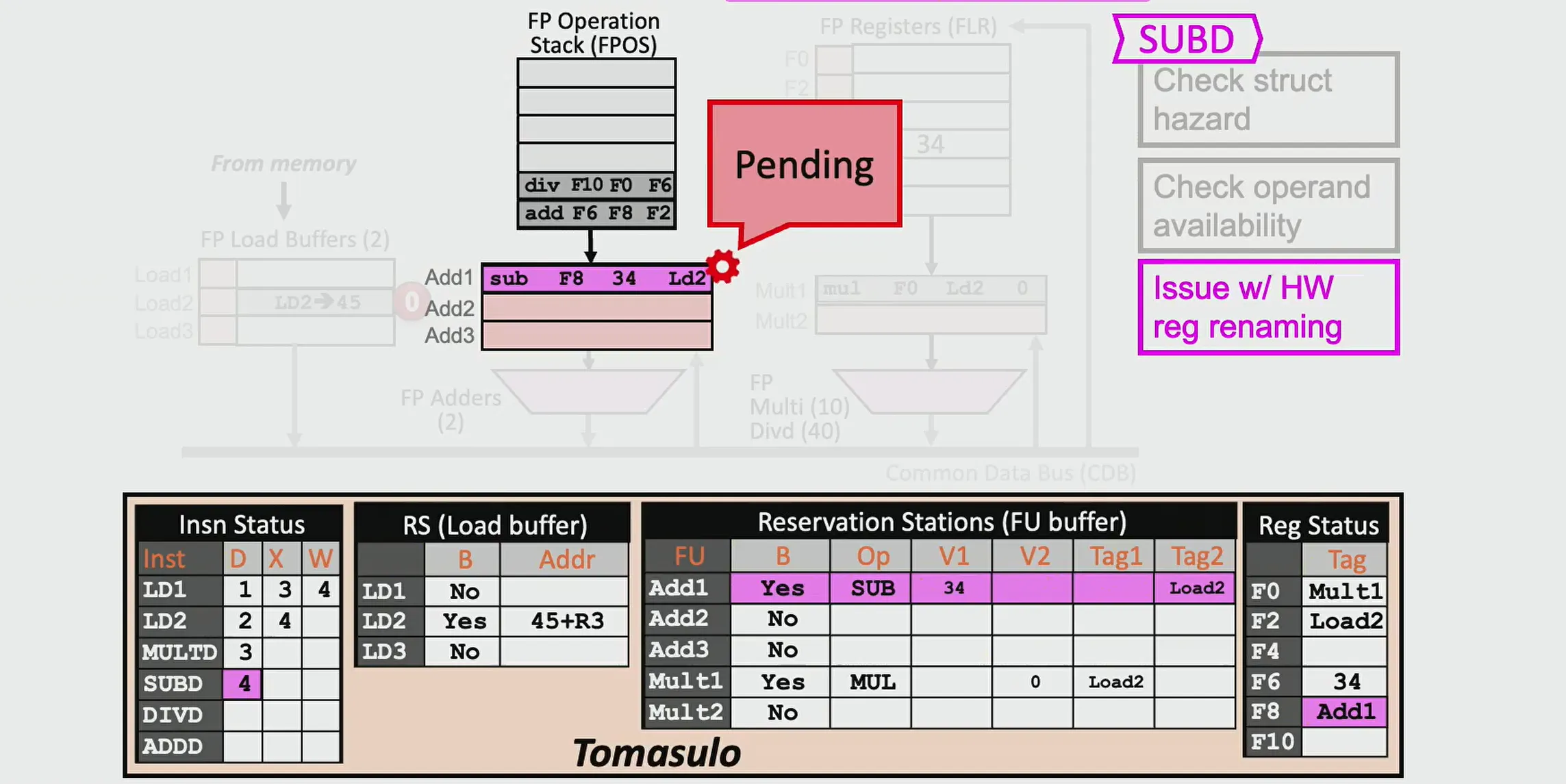
Cycle 5:
- LD2 写回,结果通过 CDB 广播,更新寄存器和 RS
- Add 和 Mult 指令从CDB上读取操作数,开始执行
- 和 Scoreboard 的区别:Tomasulo 不需要先把数据写回寄存器,在下个周期读出来再执行(forwarding)。与此同时 fowarding 也避免了 WAR Hazard
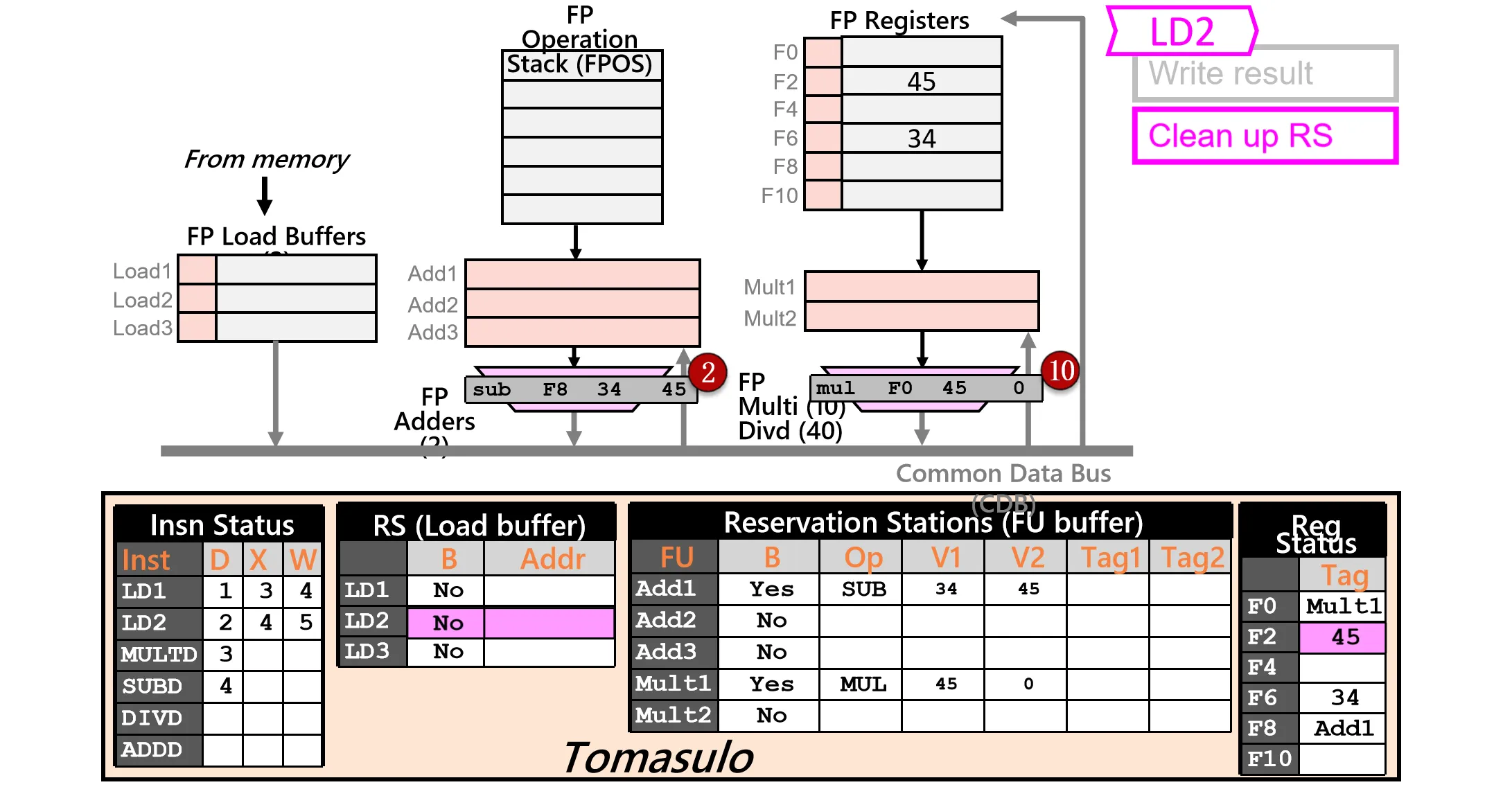
- 同时这个周期接着 Issue 第五条指令 Div,更新依赖关系 Tag1=Mult1
后续Cycle 的行为与上面的类似,涉及到指令的Issue和依赖检测,指令执行完成后结果的forwarding等。就不再详细描述
Tomasulo 指令执行特征与Scoreboard一样,都是顺序发射,乱序执行,乱序写回。
比 Scoreboard 要快,主要在于
- 通过Rename和Forwarding 避免了很多 Stall
- 提供了多个 Load/Store Buffer,减少了Structural Hazard
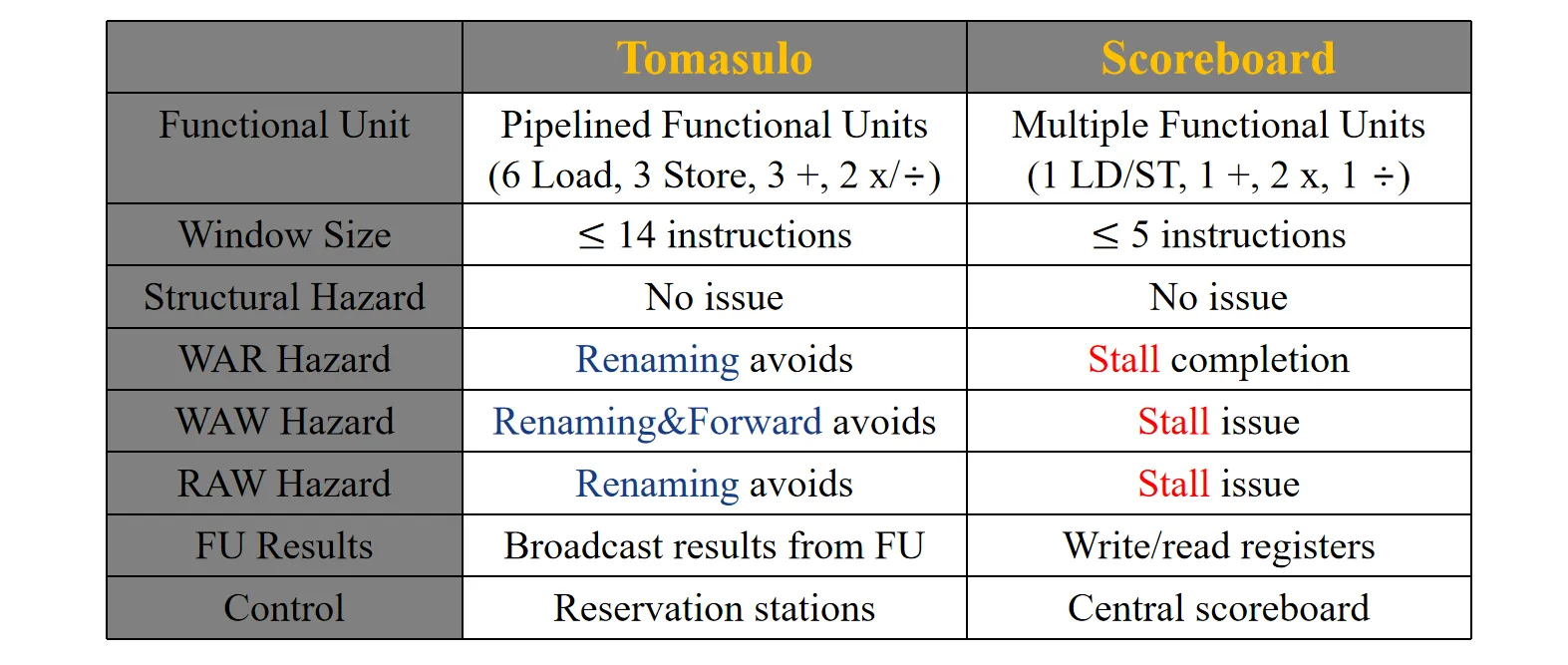
Tomasulo vs Scoreboard:
Re-order Buffer#
Tomasulo 的问题:
- Register Renaming 依赖于 RS 名称,RS 只有在数据写回后才能释放,因为要依赖 RS 名称进行fowarding(理论上EX之后RS记录的内容就不再需要了,可以释放RS)
- 乱序完成导致如果BP错误,或者异常发生时,无法恢复到正确的程序状态(寄存器已经被修改了)
Re-order Buffer(ROB) 的核心思想是:将执行完成与状态更新解耦,处理器内部虽然是乱序执行的黑盒,但只需要让外界认为指令是按顺序完成的即可
我们引入两个核心概念来区分数据的存储位置:
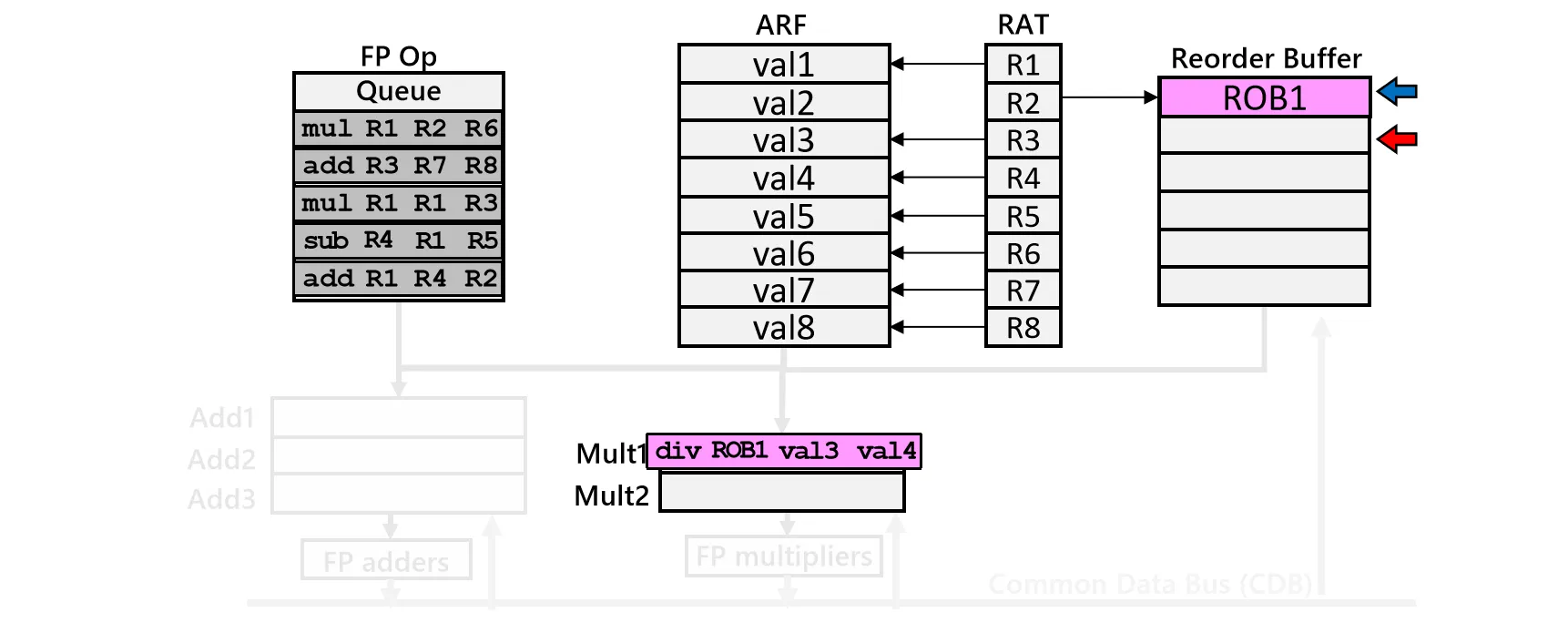
- Reorder Buffer (ROB):用于存储乱序执行后的临时结果。ROB 是一个先进先出的环形队列,严格按照指令的程序顺序分配表项
- Architectural Register File (ARF):用于存储指令提交后的最终结果,这代表了程序员视角下确定的处理器状态
在这种架构下,指令的生命周期发生了变化。指令执行完毕后,结果不再直接写入 ARF,而是先写入 ROB。只有当该指令之前的所有指令都已成功完成,且没有发生异常或预测错误时,该指令的结果才会从 ROB 刷入 ARF。这个过程被称为 Commit
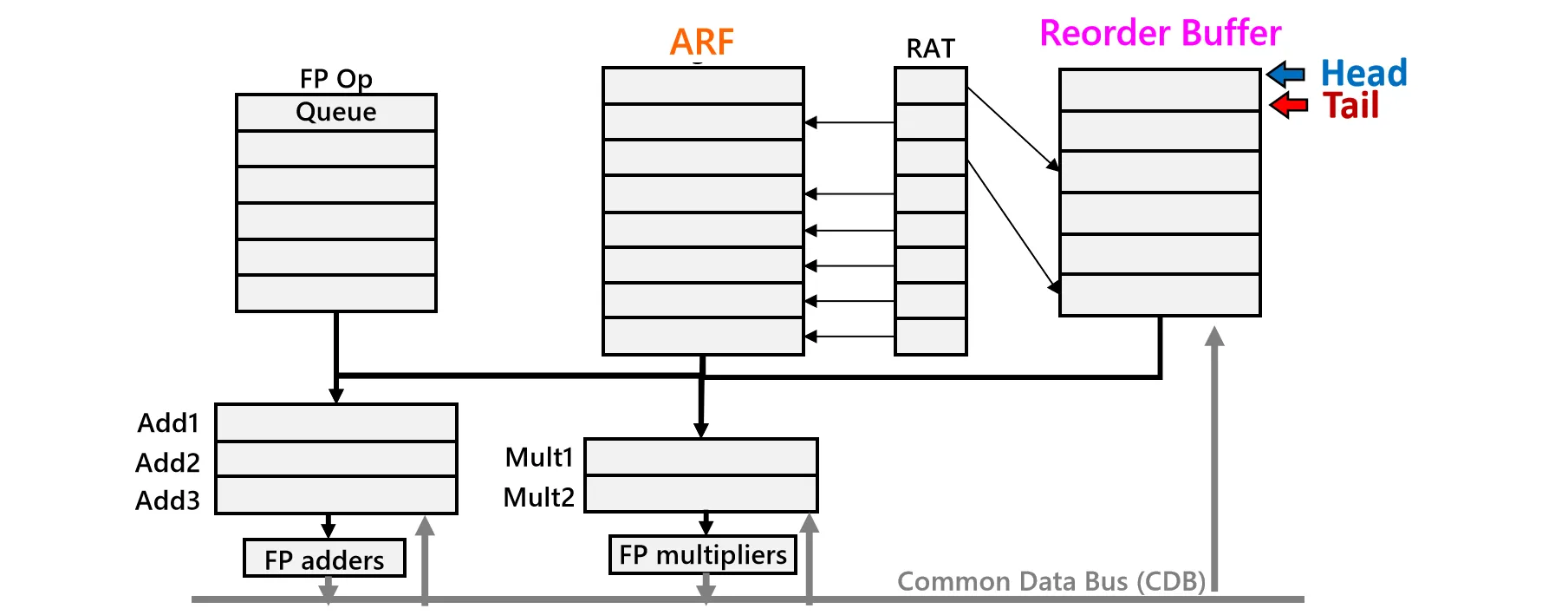
- Register Alias Table (RAT) 用于维护寄存器重命名映射关系,指示逻辑寄存器当前的值是在 ARF 中还是在 ROB 中
引入 ROB 后,处理器的流水线被扩展为四个主要阶段:
- Issue
处理器顺序地取指并进行译码,检查是否存在Structural Hazard(如果出现则Stall)
首先检查 RS 是否有空闲位置,其次检查 ROB 是否有空闲表项。ROB 是一个环形队列,我们通过 Tail 指针分配新的表项
接着进行寄存器重命名。通过查询 RAT,确定源操作数是在 ARF 中还是在某个 ROB 表项中。如果操作数就绪,直接读取;如果未就绪,则记录产生该结果的 ROB 表项编号(例如 )
最后,将目的寄存器映射更新为当前分配的 ROB 表项编号(),并将指令分发到 RS,同时推进 ROB 的 Tail 指针
- Execute
这一步骤与之前类似。只有所有源操作数都就绪,指令才会进入FU进行计算。否则会监听CDB,等待所需数据到达
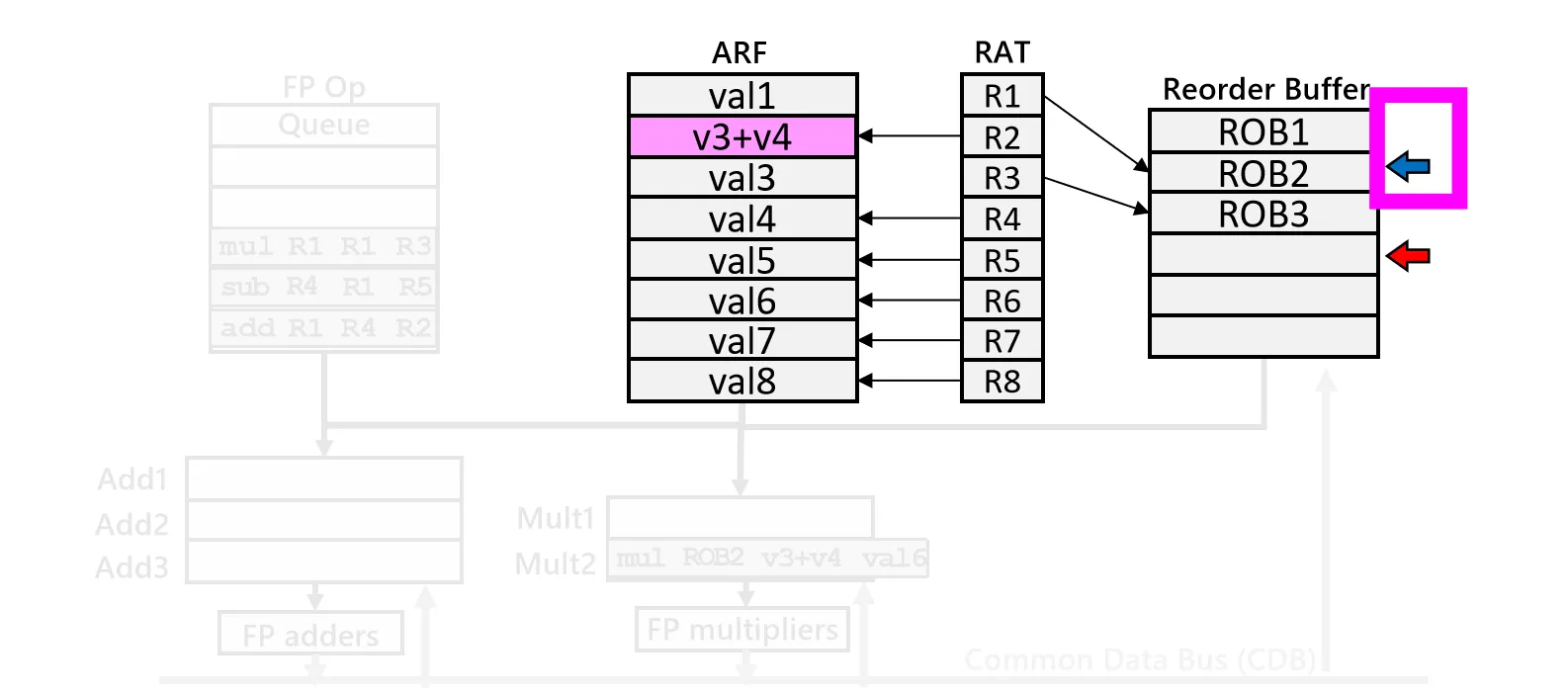
- Write Result
执行结束后会将结果广播在CDB上,关键区别在于:结果不再直接写入寄存器文件,而是写入对应的 ROB 表项,并标记为完成。
- Commit
当 ROB 的 Head 指向的指令已完成时(且无异常),我们将结果从 ROB 写入 ARF,更新 RAT(如果 RAT 仍指向该 ROB 项),并推进 Head 指针,指向下一条指令
Summary#
在这里,我们讨论的流水线都基于以下模型:
- Fetch & Decode:In-Order。取指和译码必须按顺序进行
- Issue:In-Order。在这里的模型中,发射是顺序的。(虽然现代高性能处理器支持乱序发射)
- Execute:Out-of-Order
- Write Result:Out-of-Order
- Commit:ROB 中的指令按顺序提交,Scoreboard和Tomasulo中没有Commit阶段,指令写回寄存器是乱序的